Pdf форматы: Что такое PDF? Формат PDF
PDF с точки зрения программиста / Хабр
Я имею дело с PDF не только как пользователь, а, прежде всего, как разработчик софта, умеющего его читать и писать (возможно, вы сталкивались с продуктами компании ABBYY, работающими с PDF – ABBYY FineReader, ABBYY PDF Transformer). Я предполагаю, что вы прочитали статью
habrahabr.ru/company/abbyy/blog/105006и далее пишу только про некоторые особенности и ограничения PDF, которые больше интересны продвинутым пользователям. Никаких сложных технических деталей при этом не буду касаться, так что программистам, желающим научиться читать или писать PDF, лучше сразу перейти к чтению спецификацию версии 1.7 со страницы
www.adobe.com/devnet/pdf/pdf_reference_archive.html🙂
Назначение и особенности PDF
Изначально формат PDF задумывался компанией Adobe ещё в конце 80х годов прошлого века как «электронная твёрдая копия» странично-структурированных документов, которую можно просматривать и печатать в виде, идентичном оригинальному, на разных машинах и платформах, но который не предполагается редактировать. Это определение отличает PDF от большинства других форматов хранения и распространения человеко-читаемых документов. За прошедшие годы PDF сильно эволюционировал, являясь в настоящее время контейнером для самого разнообразного контента (текст, векторная и растровая графика, интерактивные элементы, формы, аудио, видео, аннотации разных видов), но его исходное предназначение до сих пор остаётся источником как его возможностей, так и многочисленных ограничений.
Это определение отличает PDF от большинства других форматов хранения и распространения человеко-читаемых документов. За прошедшие годы PDF сильно эволюционировал, являясь в настоящее время контейнером для самого разнообразного контента (текст, векторная и растровая графика, интерактивные элементы, формы, аудио, видео, аннотации разных видов), но его исходное предназначение до сих пор остаётся источником как его возможностей, так и многочисленных ограничений.
Так, форматы текстовых документов (DOC, RTF, DOCX и т.д.) в основном ориентированы не на просмотр, а на редактирование документов. Созданный разумным пользователем 🙂 документ логично реагирует на вставку/замену/удаление текста, картинок, таблиц в разных местах, изменение размеров и полей страниц, изменение форматирования фрагментов текста любого размера и тому подобные действия. Интернет страницы в формате HTML не слишком ориентированы на редактирование (хотя и допускают его), но при условии прямых рук автора нормально переносят отображение не только на экране монитора своего создателя, но и на устройствах с совершенно другими экранами и взаимодействием с пользователем.
У PDF же особый путь – наибольшее распространение он получил как формат-паразит, в котором документы не создаются человеком «с нуля», а чаще всего порождаются из других форматов путём глубокой машинной переработки, теряющей многие или даже все детали, ненужные для
PDF-принтер переводит GDI(«интерфейс графических устройств»)-команды вывода в нужные места символов, линий, кривых, прямоугольников, растровых изображений и прочих геометрических примитивов в соответствующие им PDF-команды с сохранением в файл. При этом, разумеется, сохраняются количество и размер страниц, на которое выполнялась печать.
Такое преобразование способно очень точно передать внешний вид того, что получилось, перед печатью (например, линии и символы не теряют своей чёткости при любом масштабировании и при этом хранятся достаточно компактно), но совершенно игнорирует устройство документа, из которого это получилось. Например, для подчёркивания слова или другого фрагмента текста в PDF не предусмотрено выделенной команды или атрибута символов – вместо этого отдельно выводятся символы (группами, которые обычно даже не совпадают со словами или строками), а отдельно рисуются линии или тоненькие прямоугольники нужной толщины и цвета в нужных местах страницы. Таблицы, которые человек воспринимает как целостный набор ячеек, для приложения, отображающего PDF, – просто хаотический набор символов и линий, по случайному совпадению образовавших нечто, воспринимаемое человеком как таблица. Гиперссылки, которые в исходном документе можно было использовать как для навигации внутри документа, так и для перехода на Веб-адреса, при печати исчезают как средство навигации, остаются лишь окрашенные и/или подчёркнутые надписи. В общем, сплошные имитация и надувательство. Такие PDF я ниже буду называть «векторными» (как состоящие из векторных команд, к которым относится и рисование символов).
Например, для подчёркивания слова или другого фрагмента текста в PDF не предусмотрено выделенной команды или атрибута символов – вместо этого отдельно выводятся символы (группами, которые обычно даже не совпадают со словами или строками), а отдельно рисуются линии или тоненькие прямоугольники нужной толщины и цвета в нужных местах страницы. Таблицы, которые человек воспринимает как целостный набор ячеек, для приложения, отображающего PDF, – просто хаотический набор символов и линий, по случайному совпадению образовавших нечто, воспринимаемое человеком как таблица. Гиперссылки, которые в исходном документе можно было использовать как для навигации внутри документа, так и для перехода на Веб-адреса, при печати исчезают как средство навигации, остаются лишь окрашенные и/или подчёркнутые надписи. В общем, сплошные имитация и надувательство. Такие PDF я ниже буду называть «векторными» (как состоящие из векторных команд, к которым относится и рисование символов).
Другой способ получения PDF-документов, ставший особенно популярным в последние годы, – переработка в него отсканированных бумажных страниц.
Некоторые современные приложения (в том числе приложения комплекта OpenOffice, Microsoft Office новых версий, ABBYY FineReader и ABBYY PDF Transformer) умеют создавать PDF самостоятельно, пользуясь при этом гораздо большим арсеналом средств, чем PDF-принтеры, ибо знают об исходном документе гораздо больше, чем нужно передать принтеру. Это позволяет сохранить, например, гиперссылки как таковые (а не просто как окрашенный и/или подчёркнутый текст) или описать некоторые элементы структуры документа для его переформатирования и показа на экранах малых разрешений.
Преобразование PDF-документов в другие форматы
Желание отредактировать содержимое PDF-документа или преобразовать его в другие, желательно редактируемые форматы (как для немедленного редактирования, так и для хранения с возможностью поиска/редактирования «когда-нибудь»), возникает по разным причинам.

Неслучайно в софтверной индустрии сформировалась целая отрасль, производящая средства конверсии с лучшей функциональностью. Из написанного выше (и особенно – ниже), должно стать понятно, насколько это непростая задача. Большинство пользователей, не читавших этого креатива, так не считают – поэтому я его и пишу 🙂
Основные проблемы при преобразовании PDF в другие форматы

Хуже другое – даже в пределах одной страницы PDF можно использовать (слишком) широкий набор средств изображения похожего глазу текста: буквы могут быть видны как части растрового изображения – например, в логотипах (задача их распознавания – в чистом виде задача OCR-приложений, того же ABBYY FineReader), как результат рисования кривыми Безье или специальными текстовыми командами. Этот последний случай – самый лучший для обработки, но даже здесь не обязательно указываются общепринятые коды символов из Unicode или других кодировок – ибо в PDF-файл можно записывать особые шрифты из подмножества только реально использованных символов и ссылаться на символы по совершенно условным «номерам глифов», а не по кодам. То есть не всегда просто как обнаружить символы в нужном месте, так и определить их коды! С форматированием, в том числе с выбором похожего шрифта при отсутствии точного аналога, всё ещё хитрее.
Символы, даже если их присутствие и коды тем или иным способом установлены, своим порядком вывода на страницу очень часто никак не соответствуют исходной последовательности их размещения и чтения на странице. Например, на двухколоночной странице команды вывода текста из правой и левой колонок могут быть произвольно перемешаны. На такой странице нужно выделить области, в каждой из которых размещён логически связный текст – это тоже задача, много лет решаемая OCR-приложениями. Некоторую помощь даёт структурная информация из тегированных PDF – но часто даже у сделанных сейчас PDF эта информация либо отсутствует – как при выводе через PDF-принтер – либо бывает недостаточно полна.
Когда мы решили, что в некоторых местах страницы есть связный текст (а где-то даже поняли, как он сгруппирован в таблицы – это очень нетривиальная задача!), и нашли, какие символы и в какие строчки складываются, нужно преобразовать эти строчки в абзацы и более высокоуровневые элементы, привычные пользователям как текстовых процессоров, так и HTML – колонки, таблицы, врезки. Данных об абзацном форматировании в PDF обычно нет, так что все эти характеристики тоже нужно вычислять – как при всём том же распознавании. Если пытаться игнорировать элементы текста сложнее строчек или абзацев, то, выведя всё в коротких врезках, получим документ, который выглядит как настоящий, но почти не редактируется – помните задачу о замене по всему документу слова «MS» на «Microsoft»? Это очень хороший тест на редактируемость. Для редактируемого документа важна способность текста перетекать из одних зон в другие – в нужных случаях, которые ещё надо суметь отличить от ненужных.
Данных об абзацном форматировании в PDF обычно нет, так что все эти характеристики тоже нужно вычислять – как при всём том же распознавании. Если пытаться игнорировать элементы текста сложнее строчек или абзацев, то, выведя всё в коротких врезках, получим документ, который выглядит как настоящий, но почти не редактируется – помните задачу о замене по всему документу слова «MS» на «Microsoft»? Это очень хороший тест на редактируемость. Для редактируемого документа важна способность текста перетекать из одних зон в другие – в нужных случаях, которые ещё надо суметь отличить от ненужных.
Только проделав всё это, можно превратить содержимое PDF в файл редактируемого формата, выглядящий похоже на оригинал и удобный для работы. Конечно, за многие годы многие умные люди в разных компаниях научились решать каждую из этих задач хорошо или даже отлично, но идеального решения всей задачи в целом я ещё не встречал. Но мы над этим работаем 🙂
Вячеслав Сапроненко SlaSapro
Департамент продуктов для распознавания текстов
Сохранение или конвертация файлов в формат PDF или XPS в классической версии Project
Чтобы экспортировать или сохранить файл Office в формате PDF, откройте его и в меню Файл выберите пункт Экспорт или Сохранить как. Чтобы просмотреть пошаговые инструкции, выберите приложение Office в раскрывающемся списке.
Чтобы просмотреть пошаговые инструкции, выберите приложение Office в раскрывающемся списке.
-
Откройте таблицу или отчет, которые требуется опубликовать в формате PDF.
-
На вкладке Внешние данные в группе Экспорт нажмите кнопку PDF или XPS.
-
В поле Имя файла введите или выберите имя документа.
-
В списке Тип файла выберите PDF.
-
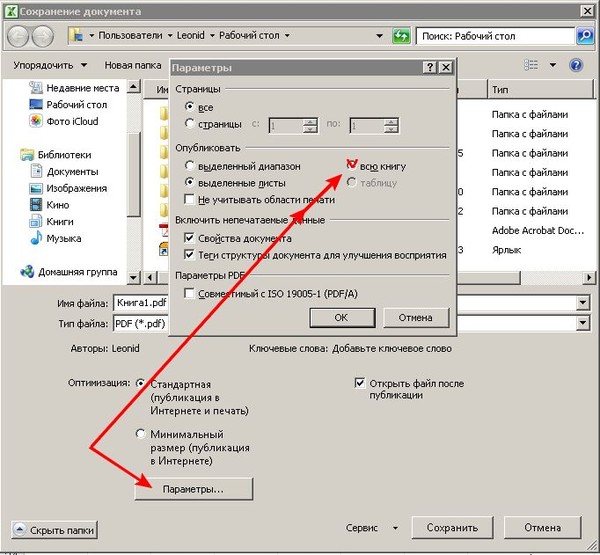
Если требуется высокое качество печати документа, установите переключатель в положение Стандартная (публикация в Интернете и печать).

-
Если качество печати не так важно, как размер файла, установите переключатель в положение Минимальный размер (публикация в Интернете).
-
-
Нажмите кнопку Параметры, чтобы выбрать страницы для печати, указать, должна ли печататься разметка, а также выбрать параметры вывода. Нажмите кнопку ОК.
-
Нажмите кнопку Опубликовать.

Эти сведения также относятся к Microsoft Excel Starter 2010.
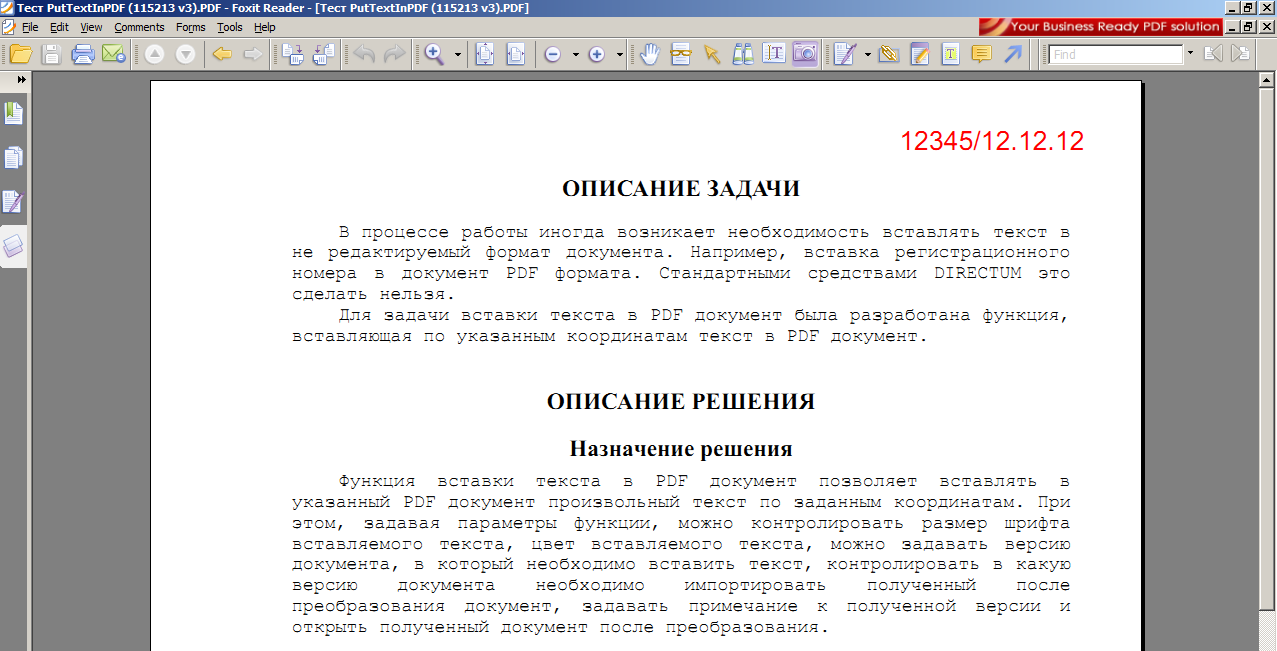
Примечание: Вы не можете сохранять листы Power View как PDF-файлы.
-
Откройте вкладку Файл.
-
Выберите команду Сохранить как.
Чтобы от видите диалоговое окно Сохранить как в Excel 2013 или Excel 2016, необходимо выбрать расположение и папку. -
В поле Имя файла введите имя файла, если оно еще не присвоено.
-
В списке Тип файла выберите PDF.
-
Если файл требуется открыть в выбранном формате после его сохранения, установите флажок Открыть файл после публикации.
-
Если необходимо высокое качество печати документа, установите переключатель в положение Стандартная (публикация в Интернете и печать).
-
Если качество печати не так важно, как размер файла, установите переключатель в положение Минимальный размер (публикация в Интернете).
-
-
Нажмите кнопку Параметры, чтобы выбрать страницы для печати, указать, должна ли печататься разметка, а также выбрать параметры вывода. Подробную информацию о диалоговом окне «Параметры» в Excel см. в статье Дополнительные сведения о вариантах создания PDF. По завершении нажмите кнопку ОК.
-
Нажмите кнопку Сохранить.

OneNote 2013 и OneNote 2016
-
Откройте вкладку Файл.
-
Нажмите кнопку Экспорт.
-
В разделе Экспорт текущего элемента выберите часть записной книжки, которую необходимо сохранить в формате PDF.
-
В разделе Выбор формата выберите пункт PDF (*.pdf) и нажмите кнопку Экспорт.
-
В диалоговом окне Сохранить как в поле Имя файла введите название записной книжки.
-
Нажмите кнопку Сохранить.

OneNote 2010
-
Откройте вкладку Файл.
-
Выберите команду Сохранить как и выберите параметр, соответствующий части записной книжки, которую необходимо сохранить в формате PDF.
-
В разделе Сохранить раздел как выберите пункт PDF и нажмите кнопку Сохранить как.
-
В поле Имя файла введите имя для записной книжки.
-
Нажмите кнопку Сохранить.
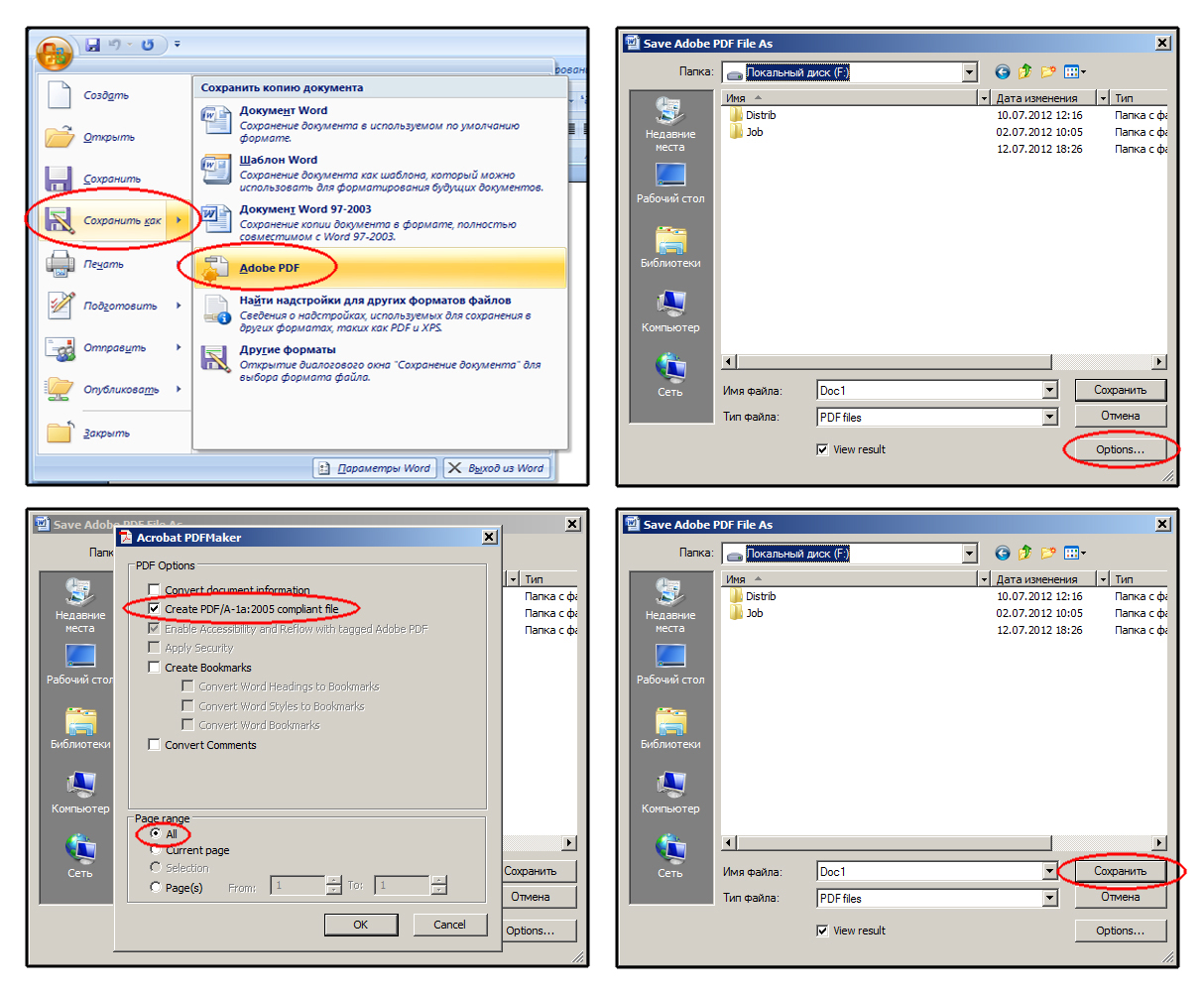
-
Откройте вкладку Файл.
-
Выберите команду Сохранить как.
Чтобы увидеть диалоговое окно Сохранить как в PowerPoint 2013 и PowerPoint 2016, необходимо выбрать расположение и папку. -
В поле Имя файла введите имя файла, если оно еще не присвоено.
-
В списке Тип файла выберите PDF.
-
Если файл требуется открыть в выбранном формате после его сохранения, установите флажок Открыть файл после публикации.
-
Если необходимо высокое качество печати документа, установите переключатель в положение Стандартная (публикация в Интернете и печать).
-
Если качество печати не так важно, как размер файла, установите переключатель в положение Минимальный размер (публикация в Интернете).
-
-
Нажмите кнопку Параметры, чтобы выбрать страницы для печати, указать, должна ли печататься разметка, а также выбрать параметры вывода. По завершении нажмите кнопку ОК.
-
Нажмите кнопку Сохранить.
-
На вкладке Файл выберите команду Сохранить как.
Чтобы от видите диалоговое окно Сохранить как в Project 2013 или Project 2016, необходимо выбрать расположение и папку. -
В поле Имя файла введите имя файла, если оно еще не присвоено.
-
В списке Тип файла выберите PDF-файлы (*.pdf) или XPS-файлы (*.xps) и нажмите кнопку Сохранить.
-
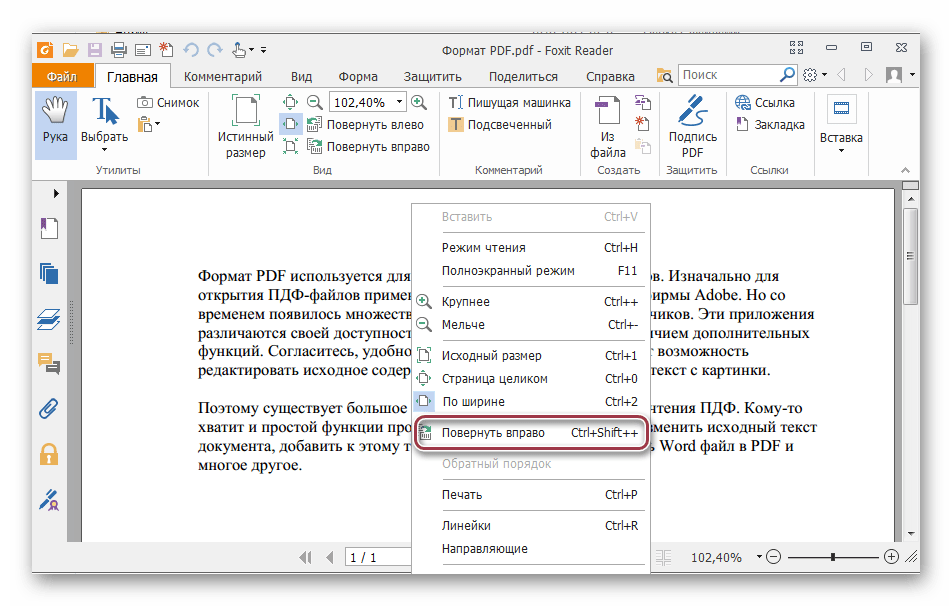
В диалоговом окне Параметры экспорта документа укажите в пункте Диапазон публикации, следует ли Включить непечатаемые данные или использовать Совместимость с ISO 19500-1 (только для PDF).

Советы по форматированию
Приложение Project не поддерживает все возможные функции форматирования документов PDF или XPS, но с помощью некоторых параметров печати вы можете изменять вид конечного документа.
На вкладке Файл выберите пункт Печать, а затем измените любой из следующих параметров:
В диалоговом окне Параметры страницы вы можете изменить параметры на таких вкладках:
-
«Поля»,
-
«Легенда»,
-
«Вид».
-
Откройте вкладку Файл.
-
Выберите команду Сохранить как.
Чтобы диалоговое окно Сохранить как в Publisher 2013 или Publisher 2016, необходимо выбрать расположение и папку. -
В поле Имя файла введите имя файла, если оно еще не присвоено.
-
В списке Тип файла выберите PDF.
-
Если необходимо изменить способ оптимизации документа, выберите команду Изменить.
(Щелкните Параметры в Publisher 2013 или Publisher 2016).-
Внесите все необходимые изменения в разрешение изображения и непечатаемые сведения.
-
Чтобы изменить параметры печати документа, выберите Параметры печати.
-
По завершении нажмите кнопку ОК.
-
-
Если после сохранения файл требуется открыть в выбранном формате, установите флажок Открыть файл после публикации.
-
Нажмите кнопку Сохранить.
 (Щелкните Параметры в Publisher 2013 или Publisher 2016).
(Щелкните Параметры в Publisher 2013 или Publisher 2016).-
Откройте вкладку Файл.
-
Выберите команду Сохранить как.
Чтобы от видите диалоговое окно Сохранить как в Visio 2013 или Visio 2016, необходимо выбрать расположение и папку. -
В поле Имя файла введите имя файла, если оно еще не присвоено.
-
В списке Тип файла выберите PDF.
-
Если файл требуется открыть в выбранном формате после его сохранения, установите флажок Автоматический просмотр файла после сохранения.
-
Если необходимо высокое качество печати документа, установите переключатель в положение Стандартная (публикация в Интернете и печать).
-
Если качество печати не так важно, как размер файла, установите переключатель в положение Минимальный размер (публикация в Интернете).
-
-
Нажмите кнопку Параметры, чтобы выбрать страницы для печати, указать, должна ли печататься разметка, а также выбрать параметры вывода. Нажмите кнопку ОК.
-
Нажмите кнопку Сохранить.


Word 2013 и более новые
-
Выберите Файл > Экспорт > Создать PDF/XPS.
-
Если свойства документа Word содержат информацию, которую вы не хотите включать в PDF-файл, в окне Опубликовать как PDF или XPS нажмите кнопку Параметры. Затем выберите пункт Документ и снимите флажок Свойства документа. Задайте другие нужные параметры и нажмите кнопку ОК.
Дополнительные сведения о свойствах документа см. в разделе Просмотр или изменение свойств файла Office 2016.
-
В окне Опубликовать как PDF или XPS выберите место, где нужно сохранить файл. При необходимости измените имя файла.
-
Нажмите кнопку Опубликовать.

Дополнительные сведения о вариантах создания PDF
-
Чтобы преобразовать в формат PDF только некоторые страницы, укажите их в полях Страницы.
-
Чтобы включить исправления в PDF, в разделе Опубликовать установите переключатель в положение Документ с исправлениями. В противном случае убедитесь установите переключатель в положение Документ.
-
Чтобы создать набор закладок в PDF-файле, установите флажок Создать закладки, используя. Затем установите переключатель Заголовки или, если вы добавили закладки в свой документ, Закладки Word.
-
Если вы хотите включить в PDF-файл свойства документа, убедитесь в том, что флажок Свойства документа установлен.
-
Чтобы сделать документ удобней для чтения в программах чтения с экрана, установите флажок Теги структуры документа для улучшения восприятия.
-
Совместимость с ISO 19005-1 (PDF/A). Этот параметр предписывает создать PDF-документ, используя стандарт архивации 1.7 PDF. Стандарт PDF/A позволяет гарантировать, что при открытии на другом компьютере документ будет выглядеть точно так же.
-
Преобразовать текст в точечный рисунок, если невозможно внедрить шрифты. Если невозможно внедрить шрифты в документ, при создании PDF-файла используется точечный рисунок текста, чтобы PDF-документ выглядел так же, как оригинальный. Если этот параметр не выбран и в файле используется невстраиваемый шрифт, программа чтения PDF-файлов может применить другой шрифт.
-
Зашифровать документ с помощью пароля.
Выберите этот параметр, чтобы ограничить доступ к PDF-файлу людям, у которых нет пароля. Когда вы нажмете кнопку ОК, Word откроет диалоговое окно Шифрование документа в формате PDF, в котором вы можете ввести пароль и его подтверждение.

 Выберите этот параметр, чтобы ограничить доступ к PDF-файлу людям, у которых нет пароля. Когда вы нажмете кнопку ОК, Word откроет диалоговое окно Шифрование документа в формате PDF, в котором вы можете ввести пароль и его подтверждение.
Выберите этот параметр, чтобы ограничить доступ к PDF-файлу людям, у которых нет пароля. Когда вы нажмете кнопку ОК, Word откроет диалоговое окно Шифрование документа в формате PDF, в котором вы можете ввести пароль и его подтверждение.Открытие PDF-файла в Word и копирование содержимого из него
Вы можете скопировать из PDF-документа нужное содержимое, открыв его в Word.
Выберите Файл > Открыть и найдите PDF-файл. Word откроет PDF в новом файле. Вы можете скопировать нужное содержимое, включая изображения и схемы.
Word 2010
Эти сведения также относятся к Microsoft Word Starter 2010.
-
Откройте вкладку Файл.
-
Выберите команду Сохранить как.
Чтобы увидеть диалоговое окно Сохранить как в Word 2013 и Word 2016, необходимо выбрать расположение и папку. -
В поле Имя файла введите имя файла, если оно еще не присвоено.
-
В списке Тип файла выберите PDF.
-
Если файл требуется открыть в выбранном формате после его сохранения, установите флажок Открыть файл после публикации.
-
Если необходимо высокое качество печати документа, установите переключатель в положение Стандартная (публикация в Интернете и печать).
-
Если качество печати не так важно, как размер файла, установите переключатель в положение Минимальный размер (публикация в Интернете).
-
-
Нажмите кнопку Параметры, чтобы выбрать страницы для печати, указать, должна ли печататься разметка, а также выбрать параметры вывода. По завершении нажмите кнопку ОК.
-
Нажмите кнопку Сохранить.


Чтобы сохранить файл в формате PDF в Office для Mac, выполните эти простые действия:
-
Откройте вкладку Файл.
-
Нажмите кнопку Сохранить как.
-
Щелкните Формат файла в нижней части окна.
-
Выберите PDF в списке доступных форматов.
-
Присвойте файлу имя, если оно еще не указано, а затем нажмите кнопку Экспорт.

С помощью Word, PowerPoint и OneNote в Интернете можно преобразовать документ в формат PDF.
-
Выберите файл > печать >печать (в PowerPoint выберите один из трех форматов).
-
В меню в области Принтер выберитесохранить в формате PDF, а затем — Сохранить.
-
Затем в открываемом меню проводника можно назвать PDF-файл, выбрать, где его сохранить, а затем выбрать сохранить.

При этом приложение создаст обычный PDF-файл, в котором будут сохранены макет и форматирование исходного документа.
Если вам нужны дополнительные возможности для управления PDF-файлом, например добавление закладок, преобразуйте документ в ФОРМАТ PDF с помощью настольного приложения. Нажмите кнопку Открыть в настольном приложении на панели инструментов PowerPoint и OneNote, чтобы начать работу с классическим приложением, а затем в Word сначала выберите в word dropdown Editing (Редактирование), а затем выберите открыть в настольном приложении.
Если у вас нет настольного приложения, вы можете попробовать или купить последнюю версию Office сейчас.
У вас есть предложения для этой возможности?
Голосуйте за понравившиеся идеи или предлагайте свои в копилке идей на сайте word.uservoice.com.
Чтобы экспортировать документ Word или книгу Excel в файл формата PDF на устройстве с iOS, нажмите в левом верхнем углу кнопку Файл и выберите пункт Экспорт, а затем — PDF.
Экспорт в Word, PDF или другой формат в Pages на Mac
Чтобы сохранить копию документа Pages в другом формате, требуется экспортировать его, выбрав новый формат. Это удобно, когда Вам нужно отправить документ людям, которые используют другое ПО. Если Вы вносите изменения в экспортированный документ, это не влияет на оригинал.
Пометки и изменения, добавленные с помощью смарт-аннотаций, не отображаются в документах, экспортированных в форматах Word, EPUB или Pages ’09. Можно экспортировать документ в формате PDF со смарт-аннотациями и комментариями либо без них.
Можно экспортировать документ в формате PDF со смарт-аннотациями и комментариями либо без них.
Примечание. Если для исходного файла задан пароль, он действует также для копий, экспортированных в форматы PDF, Word и Pages ’09, но его можно изменить или удалить.
Сохранение копии документа Pages в другом формате
Откройте документ, затем выберите «Файл» > «Экспортировать в» > [формат файла] (меню «Файл» расположено у верхнего края экрана).
Укажите настройки экспорта.
PDF. Эти файлы можно открывать и в некоторых случаях редактировать с помощью таких приложений, как «Просмотр» и Adobe Acrobat. Нажмите всплывающее меню «Качество изображения», затем выберите подходящий вариант (чем выше выбранное качество изображений, тем больше будет размер файла). Если Вы добавили текстовое описание к своим изображениям, рисункам, аудио или видео для озвучивания с помощью VoiceOver или других вспомогательных технологий, они экспортируются автоматически.
Чтобы включить смарт-аннотации или комментарии, установите соответствующий флажок. Чтобы включить теги универсального доступа для таблиц с большим объемом данных, нажмите «Дополнительные параметры», затем выберите «Вкл.».Word. Если необходимо, чтобы файл был совместим с более старой версией Microsoft Word (1997–2004), нажмите «Дополнительные параметры», затем выберите «.doc» во всплывающем меню.
EPUB. Используйте этот формат, чтобы сделать документ доступным для чтения в приложениях для чтения электронных книг (например, Apple Books). Введите имя автора и название, затем выберите обложку.
Если Вы работаете с текстовым документом, выберите тип макета. Фиксированный макет позволяет сохранить форматирование Вашего документа. Этот вариант лучше всего подходит для документов с несколькими колонками текста или большим количеством изображений. Макет с плавающей версткой изменяется в зависимости от размеров экрана и ориентации устройства, а также позволяет пользователю менять размер шрифта.
Этот вариант лучше всего подходит для документов с большим количеством текста.Для задания дополнительных параметров нажмите стрелку раскрытия рядом с пунктом «Дополнительные параметры», выберите категорию, укажите язык документа, выберите режим просмотра (одна или две страницы одновременно), а также включите или отключите оглавление и встраивание шрифтов.
Простой текст (TXT). Основной текст экспортируется без форматирования. Текстовые блоки, фигуры, изображения, линии, таблицы и диаграммы не экспортируются. Документы с макетом страницы нельзя экспортировать в формате TXT.
Совет. Чтобы узнать, является документ текстовым или документом с макетом страницы, нажмите в панели инструментов. Если вверху боковой панели есть вкладка «Закладки», это текстовый документ.
Форматированный текст (RTF). Основной текст и таблицы экспортируются как текст и таблицы в расширенном текстовом формате (RTF). Если документ содержит текстовые блоки, фигуры, линии и диаграммы, которые можно экспортировать, они экспортируются как изображения, а сам документ экспортируется в формате RTFD.
Файлы RTFD могут не поддерживаться другими приложениями и не открываться в них. Документы с макетом страницы нельзя экспортировать в форматах RTF или RTFD.Pages ’09. Файлы этого формата можно открывать в Pages версий от 4.0 до 4.3 включительно на компьютере Mac.
Если пароль является доступным параметром, выполните одно из указанных ниже действий.
Установка пароля. Установите флажок «Требовать пароль для открытия», затем введите пароль. Требование пароля применяется только к экспортированной копии.
Сохранение исходного пароля документа. Убедитесь, что флажок «Требовать пароль для открытия» установлен.
Использование другого пароля для экспортированной копии. Установите флажок «Требовать пароль для открытия», нажмите «Сменить пароль», затем задайте новый пароль.
Экспорт копии без защиты паролем. Снимите флажок «Требовать пароль для открытия».
Нажмите «Далее», затем введите имя документа (без расширения файла, например .
pdf или .epub, — оно будет добавлено к имени документа автоматически).Введите один или несколько тегов (необязательно).
Чтобы указать место для сохранения экспортированной копии презентации, нажмите всплывающее меню «Где», выберите место, затем нажмите «Экспортировать».
 Чтобы включить смарт-аннотации или комментарии, установите соответствующий флажок. Чтобы включить теги универсального доступа для таблиц с большим объемом данных, нажмите «Дополнительные параметры», затем выберите «Вкл.».
Чтобы включить смарт-аннотации или комментарии, установите соответствующий флажок. Чтобы включить теги универсального доступа для таблиц с большим объемом данных, нажмите «Дополнительные параметры», затем выберите «Вкл.». Этот вариант лучше всего подходит для документов с большим количеством текста.
Этот вариант лучше всего подходит для документов с большим количеством текста. Файлы RTFD могут не поддерживаться другими приложениями и не открываться в них. Документы с макетом страницы нельзя экспортировать в форматах RTF или RTFD.
Файлы RTFD могут не поддерживаться другими приложениями и не открываться в них. Документы с макетом страницы нельзя экспортировать в форматах RTF или RTFD. pdf или .epub, — оно будет добавлено к имени документа автоматически).
pdf или .epub, — оно будет добавлено к имени документа автоматически).Экспорт книги или другого документа в формате EPUB
Чтобы документ можно было открывать в приложениях для чтения электронных книг (например, Apple Books), его можно экспортировать в формате EPUB.
Откройте документ, затем выберите «Файл» > «Экспортировать в» > «EPUB» (меню «Файл» расположено в верхней части экрана).
Укажите необходимую информацию.
Заголовок и автор. Введите заголовок и имя автора, которые будут видеть читатели при просмотре Вашей публикации.
Обложка. Используйте первую страницу документа либо выберите файл PDF или файл изображения.
Макет. Для текстового документа можно использовать «Фиксированный макет», чтобы сохранить макет страницы, или «С плавающей версткой», чтобы читатели могли настраивать размер и стиль шрифта (при этом может измениться количество содержимого, видимого на каждой странице). Для документов с макетом страницы можно использовать только фиксированный макет.
Категория и язык. Нажмите «Дополнительные параметры», затем назначьте категорию документу EPUB и укажите язык документа.
Режим просмотра. Нажмите «Дополнительные параметры», затем выберите «Одна страница», чтобы показывать только одну страницу, или «Две страницы», чтобы показывать разворот на две страницы.
Использовать оглавление. Нажмите «Дополнительные параметры», затем выберите «Использовать оглавление», чтобы включить созданное оглавление в документ.
Встроенные шрифты. Нажмите «Дополнительные параметры» и установите этот флажок, чтобы включить в документ EPUB шрифты TrueType и OpenType.
Нажмите «Далее», затем введите название документа.
Расширение файла .epub автоматически добавляется к имени документа.
Введите один или несколько тегов (необязательно).
Чтобы указать место для сохранения документа, нажмите всплывающее меню «Где», выберите место, затем нажмите «Экспорт».

Чтобы сделать свою книгу доступной для покупки или загрузки из Apple Books, можно опубликовать ее в Apple Books непосредственно из приложения Pages. Файл EPUB создается в процессе публикации: заранее экспортировать книгу в формат EPUB не нужно.
Расширение файла PDF. Чем открыть PDF?
Расширение PDF
Чем открыть файл PDF
В Windows: Adobe Reader, Adobe Acrobat X, Foxit Reader, Sumatra PDF, Corel WordPerfect Office X6, Nuance PDF Converter Professional 8, LULU Soda PDF, Solid PDF Tools, Informative Graphics Brava! Reader, Adobe Illustrator, Microsoft Word, jPDF Tweak, FME DESKTOP, Adobe Creative Suite, любой браузер с плагином Adobe Reader
В Mac OS: Apple Preview, Adobe Reader, Adobe Acrobat X, Nuance PDF Converter для Mac 2. 0, Adobe Illustrator для Mac, Adobe Creative Suite для Mac, Solid PDF to Word, Skim, Mac OS X, Preview, любой браузер с плагином Adobe Reader
0, Adobe Illustrator для Mac, Adobe Creative Suite для Mac, Solid PDF to Word, Skim, Mac OS X, Preview, любой браузер с плагином Adobe Reader
В Linux: KPDF, KDE Okular, Evince, PDFedit, Foxit Reader для Linux, любой браузер с плагином Adobe Reader
Кроссплатформенное ПО: LibreOffice Impress
В Windows Mobile/CE: Adobe Reader
В Symbian: OfficeSuite
В Google Android: Adobe Reader, Quickoffice Pro, OfficeSuite Viewer, OfficeSuite Professional, ThinkFree Mobile, Documents To Go, Polaris Office, Kingsoft Office, QuickOffice Pro, Picsel Smart Office
В Blackberry: eOffice
В Apple iOS (iPhone, iPad, iPod): GoodReader, Apple iBooks, Adobe Debut, Quickoffice Pro, Pages for iOS, Comic Zeal
Описание расширения PDF
Популярность:
Раздел: Документы
Разработчик:
Расширение PDF в первую очередь связано с форматом документов Adobe Acrobat Portable Document Format (PDF). Другие форматы файлов с расширением .PDF встречаются очень редко, и будет не преувеличением сказать, что 99,99% файлов PDF, найденных в сети Интернет, это документы Adobe Portable.
Другие форматы файлов с расширением .PDF встречаются очень редко, и будет не преувеличением сказать, что 99,99% файлов PDF, найденных в сети Интернет, это документы Adobe Portable.
Portable Document Format (PDF) представляет собой файл формата, разработанный Adobe Systems с использованием ряда возможностей языка PostScript, который является кроссплатформенным, т.е. не зависит от операционной системы компьютера, на котором открывают файл PDF. Каждый файл .PDF инкапсулирует полное описание 2D-документов (и, с появлением Acrobat 3D, встроенных 3D-документов), что включает в себя текст, шрифты, изображения и 2D векторную графику, которые входят в документ. PDF-файлы не содержат информацию, специфичную для прикладного программного обеспечения, аппаратных средств, операционной системы или используется для создания или просмотра документов. Эта функция гарантирует, что файл PDF будет отображаться точно так же, независимо от его происхождения или назначения (но в зависимости от наличия таких же шрифтов). Google, Bing и другие поисковые системы в настоящее время индексируют PDF документы, которые можно просматривать в веб-браузере с помощью бесплатного плагина Adobe Reader.
Google, Bing и другие поисковые системы в настоящее время индексируют PDF документы, которые можно просматривать в веб-браузере с помощью бесплатного плагина Adobe Reader.
Любой может создавать приложения, читать и создавать PDF файлы без необходимости платить комиссию Adobe Systems, однако Adobe имеет ряд патентов, связанных с форматом PDF, которые утверждают, что это открытый стандарт, лицензирует их на безвозмездной основе для использования в разработке программного обеспечения, которое соответствует его спецификации PDF.
PDF файлы больше всего целесообразно использовать для кодирования точного вида документа не зависимо от операционной системы. Формат PDF может описывать как очень простые одно-страничные документы, так он может также быть использован для сложных много страничных документов, которые используют различные шрифты, графику, цвета и изображения.
Существуют много программ, которые открывают файл PDF почти для всех операционных системах, такие, как Xpdf, Foxit и Adobe имеет собственную программу Adobe Reader. В основном такие программы бесплатны. Есть множество программ для создания PDF-файлов, в том числе встроенная возможность в Mac OS X печати PDF (в меню Файл вместо нажатия на «Print» выберите «Save as PDF» в выпадающем меню в левом нижнем углу экрана), кроссплатформенная OpenOffice, многочисленные драйвера печати в PDF для Microsoft Windows, и сам Adobe Acrobat. Существует также специализированное программное обеспечение для редактирования PDF-файлов.
В основном такие программы бесплатны. Есть множество программ для создания PDF-файлов, в том числе встроенная возможность в Mac OS X печати PDF (в меню Файл вместо нажатия на «Print» выберите «Save as PDF» в выпадающем меню в левом нижнем углу экрана), кроссплатформенная OpenOffice, многочисленные драйвера печати в PDF для Microsoft Windows, и сам Adobe Acrobat. Существует также специализированное программное обеспечение для редактирования PDF-файлов.
Некорректные расширения: pdf[1], pdf-, pdf,
Mime тип: application/pdf, application/x-pdf, application/acrobat, applications/vnd.pdf, text/pdf, text/x-pdf
HEX код: 25 50 44 46 2D 31 2E
ASCII код: %PDF-1.
Другие программы, связанные с расширением PDF
- Файл настоек ArcView от Esri
Расширение файла pdf используется программой ArcView для хранения настроек. Относится к разделу Конфигурационные файлы.
Популярность:
- Информационный файл устройства печати Netware от Novell, Inc.

Файл PDF связан с Novell Netware. Этот файл создается или был скопирован с помощью программы NetWare PRINTDEF. С помощью этой программы, вы можете импортировать .PDF файл из другого источника или создать их на файловом сервере. Команды в этом файле, добавляются в начало и в конец каждого задания на печать, инициализируя принтер из файла настроек. Относится к разделу Системные файлы.
Популярность:
Файл PDF – как использовать этот формат и конвертировать
Разработанный Adobe Systems, файл с расширением PDF представляет собой файл Portable Document Format. PDF-файлы могут содержать не только изображения и текст, но также интерактивные кнопки, гиперссылки, встроенные шрифты, видео и многое другое.
Вы часто будете видеть руководства по продуктам, электронные книги, листовки, заявления о приеме на работу, отсканированные документы, брошюры и другие виды документов, доступных в формате PDF.
Поскольку PDF-файлы не зависят от программного обеспечения, которое их создало, ни от какой-либо конкретной операционной системы или оборудования, они выглядят одинаково независимо от того, на каком устройстве они открыты.
Как открыть файл PDF
Большинство людей обращаются напрямую к Adobe Acrobat Reader, когда им нужно открыть PDF. Adobe создала стандарт PDF, и её программа, безусловно, самая популярная бесплатная программа для чтения PDF. Это вполне нормально, но я считаю, что это несколько раздутая программа со множеством функций, которые вам никогда не понадобятся или которые вы не захотите использовать.
Большинство веб-браузеров, таких как Chrome и Firefox, могут открывать PDF-файлы сами. Вам может понадобиться или не потребоваться дополнение или расширение, чтобы сделать это, но довольно удобно открывать PDF в браузере, когда вы нажимаете ссылку в Интернете.
Я рекомендую SumatraPDF или MuPDF, если вы хотите чего-то большего. Оба бесплатны.
Как редактировать файл PDF
Adobe Acrobat является самым популярным редактором PDF, но Microsoft Word сделает это тоже. Также существуют другие редакторы PDF, такие как PhantomPDF и Nitro Pro.
Бесплатный редактор PDF от PDFescape, DocHub и PDF Buddy – это несколько бесплатных онлайн-редакторов PDF, которые позволяют действительно легко заполнять формы, подобные тем, которые вы иногда видите в заявлении на работу или налоговой форме. Просто загрузите свой PDF-файл на веб-сайт, чтобы сделать такие вещи, как вставка изображений, текста, подписей, ссылок и т.д., а затем загрузите его обратно на свой компьютер в формате PDF.
Просто загрузите свой PDF-файл на веб-сайт, чтобы сделать такие вещи, как вставка изображений, текста, подписей, ссылок и т.д., а затем загрузите его обратно на свой компьютер в формате PDF.
Подобный онлайн-редактор PDF под названием Fill – это замечательно, если вам просто нужно добавить подпись в PDF. Он также поддерживает включение флажков, дат и обычного текста, но вы не можете редактировать существующий текст или легко заполнять формы.
Если вы хотите извлечь часть PDF-файла как отдельную или разделить PDF-файл на несколько отдельных документов, есть несколько способов сделать это, но можно просто воспользоваться онлайн-инструментом, например: PDF.io.
Как конвертировать PDF файл
Большинство людей, желающих преобразовать PDF-файл в какой-либо другой формат, заинтересованы в этом, чтобы получить возможность редактировать содержимое PDF. Преобразование PDF означает, что он больше не будет .PDF и вместо этого откроется в программе, отличной от программы чтения PDF.![]()
Например, преобразование PDF в файл Microsoft Word (DOC и DOCX) позволяет открывать файл не только в Word, но и в других программах редактирования документов, таких как OpenOffice и LibreOffice. Использование этих типов программ для редактирования преобразованного PDF, вероятно, гораздо более удобно, по сравнению с незнакомым редактором PDF.
Если вместо этого вы хотите, чтобы файл не в формате PDF был файлом .PDF, вы можете использовать создатель PDF. Эти типы инструментов могут принимать такие вещи, как изображения, электронные книги и документы Microsoft Word, и экспортировать их в формате PDF, что позволяет открывать их в программе чтения PDF или электронных книг.
Сохранение или экспорт из какого-либо формата в PDF можно выполнить с помощью бесплатного создателя PDF. Некоторые даже служат PDF-принтером, что позволяет вам «напечатать» практически любой файл в формате .PDF. На самом деле, это простой способ конвертировать практически любой документ в PDF.
Некоторые из упомянутых выше программ могут быть использованы обоими способами, то есть вы можете использовать их как для преобразования PDF-файлов в различные форматы, так и для создания PDF-файлов.
Calibre – это ещё один пример бесплатной программы, которая поддерживает преобразование в формат электронных книг и обратно.
Кроме того, многие из упомянутых программ могут также объединять несколько PDF-файлов в один, извлекать определенные PDF-страницы и сохранять только изображения из PDF.
Бесплатный конвертер PDF в Word от FormSwift – это один из примеров онлайн-конвертера PDF, который может сохранять PDF-файлы в DOCX.
EasyPDF.com – это ещё один онлайн-конвертер PDF, который поддерживает сохранение PDF в различных форматах, чтобы он был совместим с Word, PowerPoint, Excel или AutoCAD. Вы также можете конвертировать страницы PDF в GIF или в один текстовый файл. PDF-файлы могут быть загружены из Dropbox, Google Drive или с вашего компьютера. CleverPDF является аналогичной альтернативой.
Ещё одно преобразование – PDF в PPTX. Если вы используете PDFConverter.com для преобразования документа, каждая страница PDF будет разделена на отдельные слайды, которые вы можете использовать в PowerPoint или любом другом программном обеспечении для презентаций, которое поддерживает файлы PPTX.
Как обезопасить PDF
Защита PDF может включать в себя запрос пароля для его открытия, а также запрет на печать кем-либо PDF-файла, копирование его текста, добавление комментариев, вставку страниц и другие вещи.
Soda PDF, FoxyUtils и некоторые из создателей и конвертеров PDF, на которые есть указания выше, например PDFMate PDF Converter Free, PrimoPDF и FreePDF Creator, – это лишь некоторые бесплатные приложения из многих, которые могут изменять параметры безопасности.
Как разблокировать PDF
Хотя в некоторых случаях рекомендуется защищать PDF-файл паролем, вы можете забыть, что это за пароль, потеряв доступ к вашему собственному файлу.![]()
Если вам необходимо удалить или восстановить пароль владельца PDF (тот, который ограничивает определенные действия) или пароль пользователя PDF (тот, который ограничивает открытие) в файле PDF, используйте один из инструментов для удаления паролей в PDF.
Официальная документация на формат PDF¶
На этой странице собраны сведения по состоянию на 01.03.2015.
Основные справочные документы
Основная страница со справочной информацией http://www.adobe.com/devnet/pdf/pdf_reference.html
Архив со старыми версиями документации http://www.adobe.com/devnet/pdf/pdf_reference_archive.html
Стандарт ISO 32000-1
Копия стандарта ISO 32000-1, размещённая на сайте Adobe, PDF, 756 стр., eng, 8.6Мб. (Jul 2008)
Расширения Adobe к стандарту ISO 32000, ExtensionLevel 3, PDF, 140 стр., eng, 1.3Мб. Расширения реализованы в ПО Adobe Acrobat 9.0 and LiveCycle ES 8.2. (Jun 2008)
Расширения Adobe к стандарту ISO 32000, ExtensionLevel 5,
PDF, 8 стр. , eng, 316.4Кб. Расширения реализованы в
ПО Adobe Acrobat 9.1 и Adobe Reader 9.1. (Jun 2009)
, eng, 316.4Кб. Расширения реализованы в
ПО Adobe Acrobat 9.1 и Adobe Reader 9.1. (Jun 2009)
Дальнейшие расширения к ISO: Extension Level 6 и Extension Level 8 определяют расширения касающиеся XML Forms Architecture. http://partners.adobe.com/public/developer/xml/index_arch.html
Версия формата 1.7
Эта версия была стандартизирована как стандарт ISO 32000-1.
Описание формата PDF версия 1.7 (6-я редакция), PDF, 1310 стр., eng, 31.0Мб.
Исправления к описанию версии 1.7, PDF, 18 стр., eng, 163.5Кб. (Updated Oct. 23, 2007)
Дополнения от редации к описанию версии 1.7, PDF, 4 стр., eng, 105Кб. (Nov 2006)
Расширения Adobe версии 1.7, PDF, 11 стр., eng, 170.1 Кб. Расширения реализованы в ПО Adobe Acrobat 8.1 and LiveCycle ES 8.2.
Версия формата 1.6
Описание формата PDF версия 1.6 (5-я редакция), PDF, 1236 стр., eng, 8.7Мб. (Nov 2004)
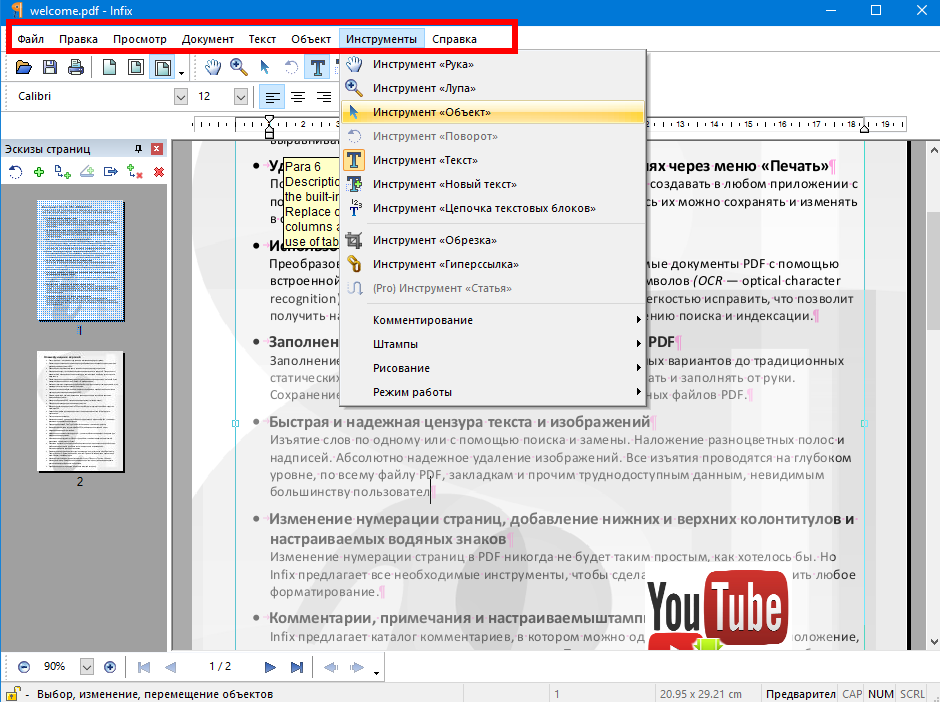
Исправления к описанию версии 1.6, PDF, 3 стр., eng, 105Кб. (Updated Oct. 4, 2006)
Дополнительное описание режимов смешивания при использовании прозрачности,
PDF, 6 стр. , eng, 89Кб. (Jan. 23, 2006)
, eng, 89Кб. (Jan. 23, 2006)
Версия формата 1.5
Описание формата PDF версия 1.5, рев. 5 (4-я редакция), PDF, 1172 стр., eng, 13.5Мб. (Aug 2003)
Описание формата PDF версия 1.5, рев. 6 (4-я редакция), PDF, 1172 стр., eng, 8.8Мб. (Aug 2003)
Исправления к описанию версии 1.5, TXT, eng, 7.1Кб. (Revised Oct. 29, 2004)
Версия формата 1.4
Описание формата PDF версия 1.4 (3-я редакция), PDF, 978 стр., eng, 8.9Мб. (Nov 2001)
Исправления к описанию версии 1.5, TXT, eng, 7.1Кб. (Revised Jun 2003)
Изменения в версии 1.4 относительно версии 1.3, PDF, 236 стр., eng, 849.3Кб.
Форматы графических изображений: подробнее о файлах JPG, PNG, SVG, PDF и EPS | Дизайн, лого и бизнес
В данной статье рассмотрим графические форматы изображений, используемые в компьютерных программах. Названия форматов, зашифрованные в аббревиатуры, не совсем понятны поначалу. Но далее все станет более прозрачно.
Теперь необходимо понять и разобраться, в чем разница между растровой и векторной графиками.
Эти вопросы мы рассматривали ранее. Итак, начнем по порядку.
Создайте свой логотип онлайн. Более 50 тысяч брендов по всему миру уже используют логотипы от Турболого.
Создать логотип онлайнРастровые форматы изображений
Самые известные и часто встречаемые растровые форматы – это JPG (или же JPEG), PDF, PNG.
JPG
Чаще всего встречаемый и известный формат — JPG.
После сжатия отличия минимальные, небольшая потеря качества, но и величина самого файла будет существенно меньше. Это очень удобно для применения в электронных публикациях.
Его особенность в том, что при сжатии можно делать выбор либо в пользу качества, либо размера. Пользователь сам решает, что ему больше подходит: это главное отличие от формата PNG. То есть вы выбираете, какое должно быть качество, вследствие чего определяется величина полученного файла. Чем сильнее сжатие, тем меньше конечный размер файла. Это помогает экономно расходовать место на жестком диске.
Часто формат JPG используют для хранения снимков (содержащих цветопередачу, яркость) и пересылки картинок в Интернете.
PNG
В PNG сжатие происходит без потери качества. Этот растровый формат распространен при хранении графических материалов, логотипов, орнаментов, текстовой графики.
Главное достоинство формата PNG – выбор палитры хранения переходных этапов. Этот метод сжатия хорош тем, что он происходит без потери качества изображения.
Векторные форматы файлов
Формат PDF знает каждый, кто хоть раз сталкивался с печатью документации и прочей бумажной продукции. Образцы экспортируются в формат PDF для дальнейшей печати. В них можно найти элементы как векторной, так и растровой графики, будь это видеоматериалы или документы.
Уникальность формата PDF в том, что с ним могут работать специальные приложения типа Acrobat, а также Microsoft. Это весьма доступный формат по причине его универсальности. Многие программы работают с ним.
SVG
Если расшифровать формат SVG, он будет означать «масштабируемая векторная графика». Предназначен для разработки и описания двухмерных векторных изображений. Так как формат SVG относится к векторным изображениям, у него возможно увеличить какую угодно часть, не потеряв в качестве изображения.
Так как формат SVG относится к векторным изображениям, у него возможно увеличить какую угодно часть, не потеряв в качестве изображения.
Преимущество его в том, что текст в этом формате является текстом, и потому он индексируется поисковыми машинами.
EPS
Это один из самых удобных способ сохранения графической информации. Совмещает в себе векторную и растровую графики. Применяется в редакциях, создает шрифты. Используется для вывода изображения на печать, устройство которого поддерживает язык PostScript. Работать и редактироваться файлы можно только в специальных программах компании Adobe. В других же программах они открываются в режиме просмотра.
Продуктовый и графический дизайнер с опытом работы более 10 лет. Пишу о брендинге, дизайне логотипов и бизнесе.
8 типов стандартов PDF — каждый служит уникальной цели
PDF, формат переносимых документов, является отраслевым стандартом для обмена и печати документов. Каждый документ, преобразованный или сохраненный в формате PDF, может быть сохранен как определенный стандарт; какой стандарт вы сохраните свой файл, как будет определяться целью, для которой он был создан. Если вы сохраните в неправильном стандарте, у вас могут возникнуть проблемы при попытке распечатать, поделиться или заархивировать файлы сейчас или в будущем.
Если вы сохраните в неправильном стандарте, у вас могут возникнуть проблемы при попытке распечатать, поделиться или заархивировать файлы сейчас или в будущем.
Понимание стандартов PDF
Всего существует восемь стандартов PDF; шесть являются стандартами ISO, а два — стандартами других организаций.
Шесть типов стандартов PDF из ISO
ISO расшифровывается как Международная организация по стандартизации, которая выдает сертификаты для продуктов, соответствующих их стандартам во многих отраслях, включая документы в формате PDF. Они устанавливают стандарты, основанные на строгом процессе сертификации, для обеспечения качества, надежности и универсальности. Каждый стандарт PDF от ISO имеет гарантированное качество, основанное на определенном наборе обстоятельств. Таким образом, какой стандарт вы используете, будет определяться набором обстоятельств вашего документа — как ваш PDF будет храниться, просматриваться, совместно использоваться, распечатываться и т. д.
д.
- PDF – этого общего стандарта PDF достаточно для использования в офисе, совместного использования и просмотра в Интернете, а также для документов стандартного качества.
- PDF/A — этот стандарт был разработан для долговременного хранения файлов и обычно используется архивистами, менеджерами документации и менеджерами по соблюдению требований. Он имеет ограниченный набор функций, включая JavaScript, аудио- и видеоконтент и шифрование, поскольку они могут помешать пользователям открывать и просматривать их в будущем.
- PDF/E — Архитекторы, инженеры, специалисты по строительству и группы по производству продуктов будут использовать этот стандарт чаще всего.Согласно Planet PDF, «этот стандарт был предназначен для решения ключевых проблем в области крупноформатных чертежей, мультимедиа, полей форм и управления правами — и это лишь некоторые из них, — которые могут помешать инженерному сообществу использовать PDF в своих рабочих процессах».
- PDF/X — этот стандарт лучше всего подходит для полиграфистов, графических дизайнеров и творческих профессионалов. При использовании этого стандарта можно ожидать высокого качества документов профессионального уровня. Этот стандарт PDF обеспечит готовность документов к печати за счет правильного встраивания шрифтов, изображений, цветовых профилей и многого другого.
- PDF/UA — этот стандарт повышает удобочитаемость для людей с ограниченными возможностями, ИТ-менеджеров в государственных или коммерческих предприятиях и менеджеров по соблюдению нормативных требований. UA означает универсальный доступ; этот стандарт будет работать со вспомогательными технологиями, которые помогают пользователям читать и ориентироваться.
- PDF/VT — профессионалы в области печати также будут использовать этот стандарт для документов. Этот стандарт основан на компонентах стандарта PDF/X, что позволяет сохранить некоторые функции, такие как цветовые профили, слои и прозрачность.Самым большим дополнением является возможность настраивать данные в этих файлах, такие как банковские выписки, счета-фактуры или персонализированные маркетинговые материалы.
 При использовании этого стандарта можно ожидать высокого качества документов профессионального уровня. Этот стандарт PDF обеспечит готовность документов к печати за счет правильного встраивания шрифтов, изображений, цветовых профилей и многого другого.
При использовании этого стандарта можно ожидать высокого качества документов профессионального уровня. Этот стандарт PDF обеспечит готовность документов к печати за счет правильного встраивания шрифтов, изображений, цветовых профилей и многого другого.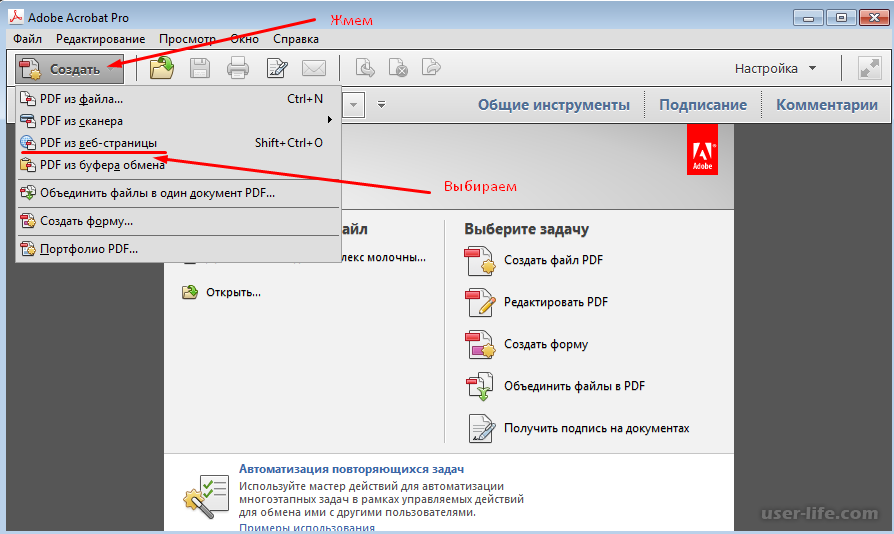
Два типа стандартов PDF от других организаций
Другие организации приняли стандарты для своих конкретных потребностей в документах.
- PAdES — Стандартизирует безопасные безбумажные транзакции, соответствующие европейскому законодательству. Этот стандарт был установлен для цифровых подписей PDF в ЕС.
- PDF Healthcare — Согласно Acrobat, этот стандарт «предлагает передовой опыт и рекомендации по внедрению для облегчения сбора, обмена, сохранения и защиты медицинской информации. Следование этим рекомендациям обеспечивает более безопасный электронный контейнер, который может хранить и передавать медицинскую информацию, включая личные документы, данные XML, изображения и данные DICOM, клинические записи, лабораторные отчеты, электронные формы, отсканированные изображения, фотографии, цифровые рентгеновские снимки и ЭКГ».
Знание параметров PDF оптимизирует качество вашего документа, если у вас есть определенные цели просмотра, совместного использования, печати или архивирования документов.![]() Если вам нужна дополнительная информация о печати высококачественных PDF-файлов (PDF/X), загляните в нашу статью о предустановках PDF.
Если вам нужна дополнительная информация о печати высококачественных PDF-файлов (PDF/X), загляните в нашу статью о предустановках PDF.
Какие существуют версии PDF/A?
Организации предпочитают PDF/A из-за его признания в отрасли и преимуществ перед другими форматами архивирования с точки зрения его способности сохранять текст, векторную графику, растровые изображения и связанные метаданные. Тем не менее, с различными стандартами PDF/A и уровнями соответствия (а в настоящее время существует восемь возможных комбинаций) легко немного заблудиться.
Если вы хотите освежить свою таксономию PDF/A, читайте дальше. В этой статье мы рассмотрим различные стандарты и уровни соответствия PDF/A, а также их значение.
Каковы различные версии PDF/A и уровни соответствия?
PDF/A поставляется во многих возможных вариантах, созданных путем смешивания различных стандартов PDF/A и уровней соответствия.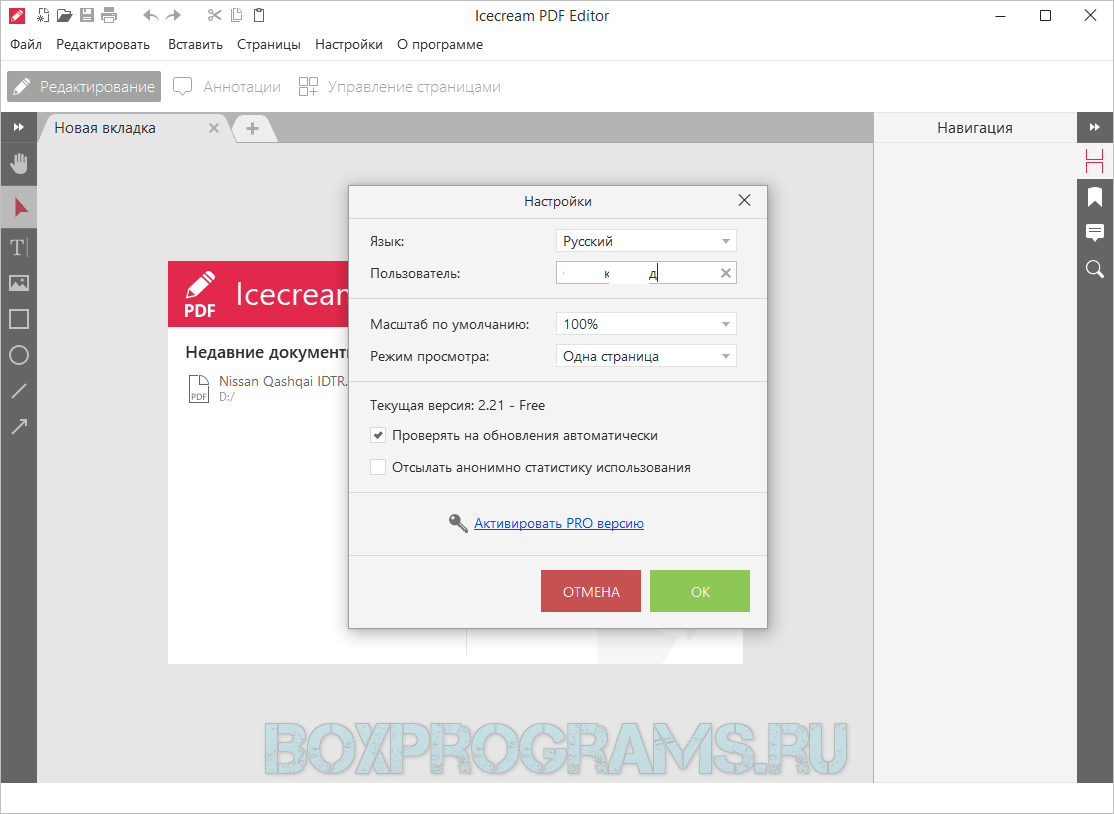 Каждый стандарт PDF/A определяет набор доступных функций и технологий сжатия изображений, которые помогают сохранить содержимое файла.В свою очередь, каждый стандарт PDF/A поддерживает различные уровни соответствия (a и b для PDF/A-1; и a, b и u для PDF/A-2 и -3). Эти уровни соответствия контролируют требования «доступности» файла, которые влияют на способность компьютеров и людей понимать содержимое.
Каждый стандарт PDF/A определяет набор доступных функций и технологий сжатия изображений, которые помогают сохранить содержимое файла.В свою очередь, каждый стандарт PDF/A поддерживает различные уровни соответствия (a и b для PDF/A-1; и a, b и u для PDF/A-2 и -3). Эти уровни соответствия контролируют требования «доступности» файла, которые влияют на способность компьютеров и людей понимать содержимое.
Подробно: различные стандарты PDF/A
PDF/A-1: (ISO 19005-1:2005)
PDF/A-1 — исходный стандарт PDF/A, наиболее часто используемый сегодня, и самый ограничительный.Поскольку он основан на более старом стандарте PDF, PDF 1.4, опубликованном Adobe Systems в 2001 году, PDF/A-1 не поддерживает JPEG 2000, слои или вложения. Кроме того, несмотря на поддержку в PDF 1.4, прозрачность считалась «слишком новой» во время создания PDF/A-1 и поэтому не была включена.
Отсутствующие функции: JPEG2000, прозрачность, слои и вложения
Уровни соответствия: a & b
На основе PDF 1. 4
4
PDF/A-2: (ISO 19005-2) в ПДФ 1.7 (ISO 32000-1:2008) PDF/A-2 представляет несколько функций, недоступных в PDF 1.4, а также прозрачность. Дополнения включают слои, улучшенное сжатие изображений (JPEG 2000 и JBIG2) и вложения — при условии, что эти вложения имеют формат PDF/A.
PDF/A-2 не делает файлы PDF/A-1 устаревшими. Скорее, стандарт предназначен для прямой совместимости: например, действительный файл PDF/A-1b должен пройти проверку в программном обеспечении, установленном для проверки на PDF/A-2b или PDF/A-3b.
Наконец, в PDF/A-2 был введен уровень соответствия u (как в Unicode ).Уровень u позволяет организациям гарантировать надежный поиск и копирование текста документа без необходимости соответствия файла другим требованиям уровня a.
Новые и разрешенные функции: JPEG 2000, прозрачность, слои и вложения (только другие файлы PDF/A)
Уровни соответствия: a, b и u
На основе PDF 1. 7 (ISO 32000-1:2008) )
7 (ISO 32000-1:2008) )
PDF/A-3 (ISO 19005-3:2012)
PDF/A-3 практически идентичен PDF/A-2.(Они оставили нетронутыми даже опечатки.) Единственное отличие состоит в том, что PDF/A-3 допускает вложение файлов любого типа.
Тем не менее, программе просмотра PDF/A не требуется никаких дополнительных действий с этими вложенными файлами, кроме обеспечения их надлежащего извлечения. Таким образом, стандарт не может гарантировать, сможете ли вы читать или иным образом использовать эти файлы в будущем , что побуждает архивариусов высказывать опасения, что PDF/A-3 может позволить обойти архивные ограничения на разрешенные форматы.
В ответ на вышеуказанное беспокойство было отмечено, что тщательно разработанный рабочий процесс, построенный с учетом архивных соображений, может учитывать и использовать возможности PDF/A-3. Действительно, PDF/A-3 был в значительной степени вдохновлен желанием иметь доступный машиночитаемый компонент, такой как проприетарные двоичные данные или XML, используемый в ситуациях, когда встроенные форматы могут быть тщательно прописаны. Примером этого является гибридный стандарт электронного выставления счетов ZUGFeRD, опубликованный через два года после введения PDF/A-3, одобренный правительством Германии и одобренный многими организациями и предприятиями Европейского Союза.
Примером этого является гибридный стандарт электронного выставления счетов ZUGFeRD, опубликованный через два года после введения PDF/A-3, одобренный правительством Германии и одобренный многими организациями и предприятиями Европейского Союза.
Новые и разрешенные функции: Вложения (любой тип файла)
Уровни соответствия: a, b и u
На основе PDF 1.7 (ISO 32000-1:2008)
PDF/ 19005-4:2019)
Иногда называемый PDF/A-NEXT, PDF/A-4 — это следующая версия стандарта PDF/A, опубликованная в ноябре 2020 года как ISO 19005-4:2020. A-4 обновляет PDF/A, чтобы привести его в соответствие с PDF 2.0, последней версией стандарта PDF ISO.
Примечательно, что отдельные уровни соответствия a, b и u не используются в PDF/A-4.Вместо этого PDF/A-4 поощряет, но не требует добавления логических структур более высокого уровня, а также требует сопоставления Unicode для всех шрифтов.
Кроме того, PDF/A-4 вводит два новых уровня соответствия, e и f. PDF/A-4f позволяет встраивать типы файлов любого другого формата, тогда как PDF/A-4e вводит поддержку аннотаций типов RichMedia и 3D, а также встроенных файлов для создания версии PDF/A, совместимой с современными геопространственными, строительными и инженерные рабочие процессы. («Е» означает «инженерный», как и в ранее созданном стандарте PDF/E.)
PDF/A-4f позволяет встраивать типы файлов любого другого формата, тогда как PDF/A-4e вводит поддержку аннотаций типов RichMedia и 3D, а также встроенных файлов для создания версии PDF/A, совместимой с современными геопространственными, строительными и инженерные рабочие процессы. («Е» означает «инженерный», как и в ранее созданном стандарте PDF/E.)
Новые возможности: Совместимость с PDF 2.0
Уровни соответствия: e & f На основе PDF 2.0 (ISO 32000-2:2017)
Различные уровни соответствия PDF/A
Уровень b (базовый)
PDF/A-1b, PDF/A-2b, PDF/A- 3b
Соответствие уровня B требует только того, чтобы документы соответствовали рекомендациям по надежному просмотру, и, следовательно, это самый простой для достижения уровень.
Из спецификации ISO:
Уровень соответствия B
Уровень соответствия, охватывающий требования этой части ISO 19005 в отношении внешнего вида электронных документов, но ни их структурных или семантических свойств, ни требования, чтобы весь текст имел эквиваленты Unicode .
Уровень a (доступный)
PDF/A-1a, PDF/A-2a, PDF/A-3a
«Доступный» уровень соответствия — это надмножество соответствия b-уровня. Он добавляет требования к информации, предназначенной для сохранения логической структуры документа, семантического содержания и естественного порядка чтения.
Другими словами, соответствие уровня А не только гарантирует, что документы будут выглядеть одинаково в будущем; это также помогает машинам и людям лучше понимать и переназначать его содержание.Действительный PDF/A-уровень будет содержать текст, который можно надежно искать и копировать, а также контент, более доступный для таких технологий, как программы чтения с экрана для слепых.
Список требований уровня A выглядит следующим образом:
- Контент должен быть помечен с иерархическим деревом структуры , что означает, что такие элементы, как порядок чтения, рисунки и таблицы, явно идентифицируются через метаданные.
- Должен быть указан естественный язык документа.
- Изображения и символы должны иметь альтернативный описательный текст.
- Файл должен включать сопоставление символов Unicode для надежного поиска и копирования.
Примечание: ни одно из этих требований не изменит внешний вид документа.
Уровень u (Unicode)
PDF/A-2u, PDF/A-3u
Как и «уровень a», соответствие уровня u требует преобразования символов в Unicode . Однако он отбрасывает требования уровня A, включая встроенную логическую структуру (т.т. е., теги и дерево структур), как указано в разделе 6.7 ISO 19005-2 (PDF 1.7). Таким образом, PDF/A, соответствующий уровню u, будет иметь текст, который можно надежно найти и скопировать, но порядок чтения не гарантируется.
Подробнее о PDF/A и решениях PDF/A от PDFTron
Таким образом, знание параметров PDF/A поможет вам повысить ценность ваших документов для конкретных целей просмотра, совместного использования, печати или архивирования. Если вам нужна дополнительная информация о PDF/A, посетите нашу страницу «Все о PDF/A».
Если вам нужна дополнительная информация о PDF/A, посетите нашу страницу «Все о PDF/A».
Если вы заинтересованы в преобразовании в определенный вариант PDF/A, попробуйте бесплатный онлайн-инструмент для преобразования PDF/A от PDFTron, способный преобразовать более 20 форматов файлов в любую версию PDF/A; или прочитайте нашу статью о том, как конвертировать в PDF/A с помощью PDF SDK PDFTron или инструмента командной строки.
Если у вас есть какие-либо вопросы о PDF SDK PDFTron, свяжитесь с нами!
Формат файла PDF: базовая структура [обновлено в 2020 г.]
Все мы знаем, что существует ряд атак, когда злоумышленник включает шелл-код в документ PDF.Этот шеллкод использует некоторую уязвимость в том, как документ PDF анализируется и представляется пользователю для выполнения вредоносного кода в целевой системе.
На следующем изображении представлено количество уязвимостей, обнаруженных в популярной программе для чтения PDF-файлов Adobe Acrobat Reader DC, которая была выпущена в 2015 году и стала единственной поддерживаемой версией Acrobat Reader после прекращения поддержки Acrobat XI в октябре 2017 года.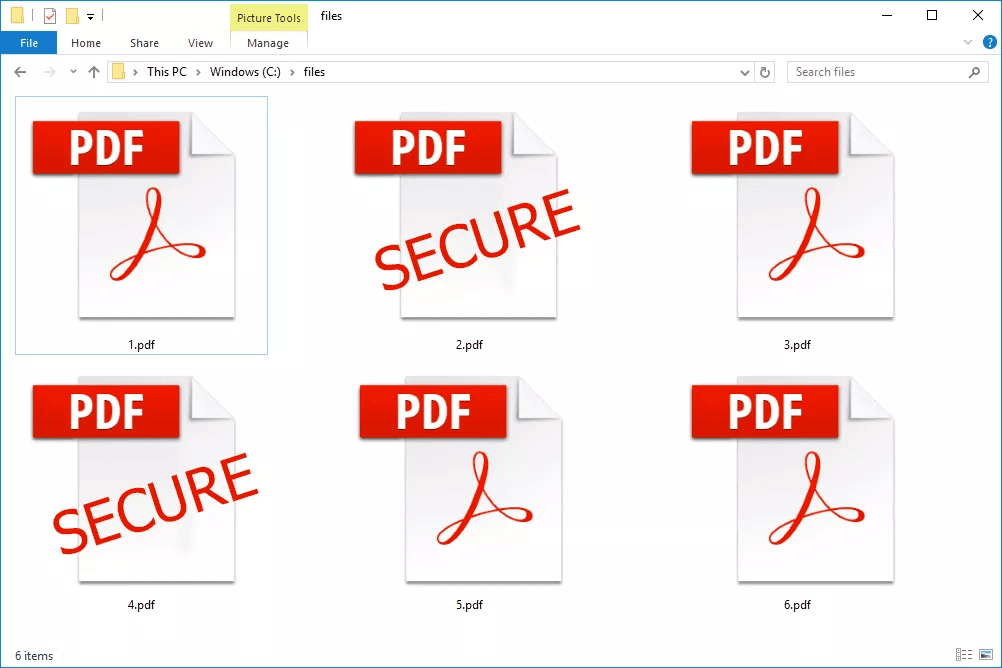 Количество уязвимостей увеличивается. с годами. Наиболее важными уязвимостями являются уязвимости выполнения кода, которые злоумышленник может использовать для выполнения произвольного кода на целевой системе (если Acrobat Reader еще не пропатчен).
Количество уязвимостей увеличивается. с годами. Наиболее важными уязвимостями являются уязвимости выполнения кода, которые злоумышленник может использовать для выполнения произвольного кода на целевой системе (если Acrobat Reader еще не пропатчен).
Рис. 1. Уязвимости Adobe Acrobat Reader DC
Это важный показатель того, что мы должны регулярно обновлять нашу программу для чтения PDF-файлов, поскольку количество обнаруженных в последнее время уязвимостей весьма устрашающе.
Структура файла PDF
Всякий раз, когда мы хотим обнаружить новые уязвимости в программном обеспечении, мы должны сначала понять протокол или формат файла, в котором мы пытаемся обнаружить новые уязвимости. В нашем случае мы должны сначала подробно разобраться в формате файла PDF.В этой статье мы рассмотрим формат файла PDF и его внутренности.
PDF — это портативный формат документов, который можно использовать для представления документов, содержащих текст, изображения, мультимедийные элементы, ссылки на веб-страницы и многое другое.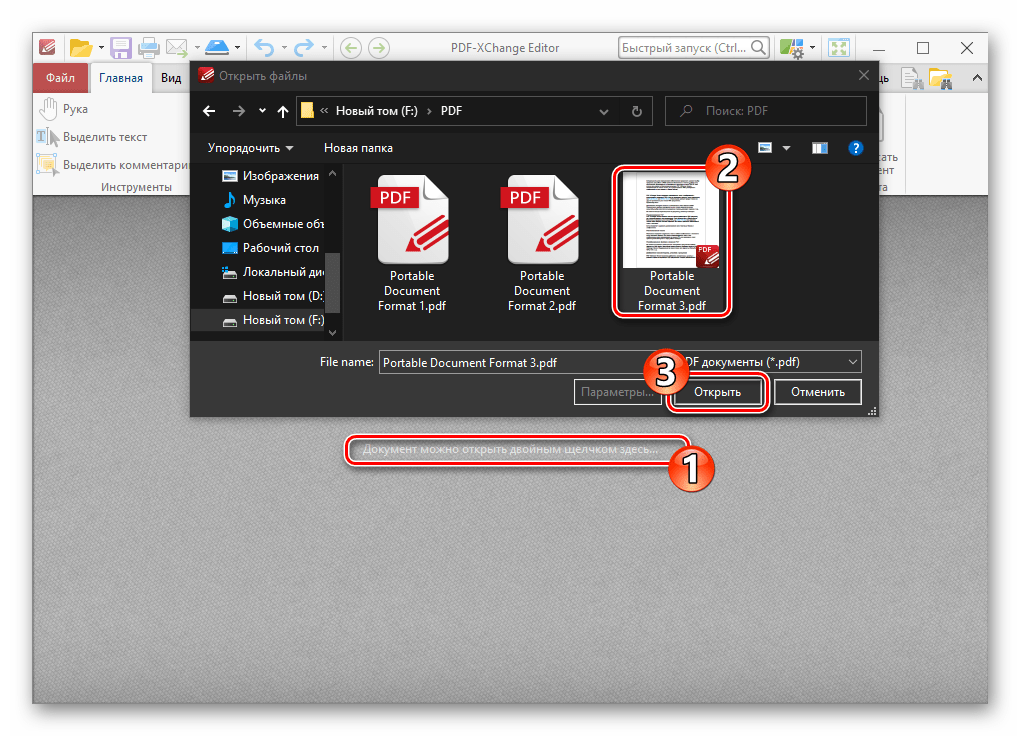 Он имеет широкий спектр функций. Спецификация формата PDF-файла общедоступна здесь и может использоваться всеми, кто интересуется форматом PDF-файла. Только для формата файла PDF имеется почти 800 страниц документации, так что читать ее — это не то, что нужно делать по прихоти.
Он имеет широкий спектр функций. Спецификация формата PDF-файла общедоступна здесь и может использоваться всеми, кто интересуется форматом PDF-файла. Только для формата файла PDF имеется почти 800 страниц документации, так что читать ее — это не то, что нужно делать по прихоти.
PDF имеет больше функций, чем просто текст: он может включать изображения и другие мультимедийные элементы, быть защищенным паролем, выполнять JavaScript и так далее. Базовая структура файла PDF представлена на рисунке ниже:
Рисунок 2: Структура PDF
Каждый документ PDF содержит следующие элементы:
Заголовок
Это первая строка файла PDF, в которой указывается номер версии используемой спецификации PDF, используемой в документе.Если мы хотим узнать это, мы можем использовать шестнадцатеричный редактор или просто использовать команду xxd , как показано ниже:
[обычный]
# xxd temp.pdf | head -n 1
0000000: 2550 4446 2d31 2e33 0a25 c4e5 f2e5 eba7 %PDF-1. 3.%……
3.%……
[/plain]
PDF-документ temp.pdf использует спецификацию PDF 1.3. Символ «%» является комментарием в PDF, поэтому в приведенном выше примере первая и вторая строки фактически представляют собой комментарии, что верно для всех документов PDF. Следующие байты взяты из вывода ниже: 2550 4446 2d31 2e33 0a25 c4e5 и соответствуют ASCII-тексту «%PDF-1.3.%». Ниже приведены некоторые символы ASCII, которые используют непечатаемые символы (обратите внимание на точки «.»), которые обычно указывают некоторым программным продуктам, что файл содержит двоичные данные и не должен рассматриваться как 7-битный ASCII. текст. В настоящее время номера версий имеют форму 1.N, где N находится в диапазоне от 0 до 7.
Кузов
В теле документа PDF есть объекты, которые обычно включают текстовые потоки, изображения, другие мультимедийные элементы и т. д. Раздел «Тело» используется для хранения всех данных документа, отображаемых пользователю.
Таблица внешних ссылок
Это таблица перекрестных ссылок, которая содержит ссылки на все объекты в документе.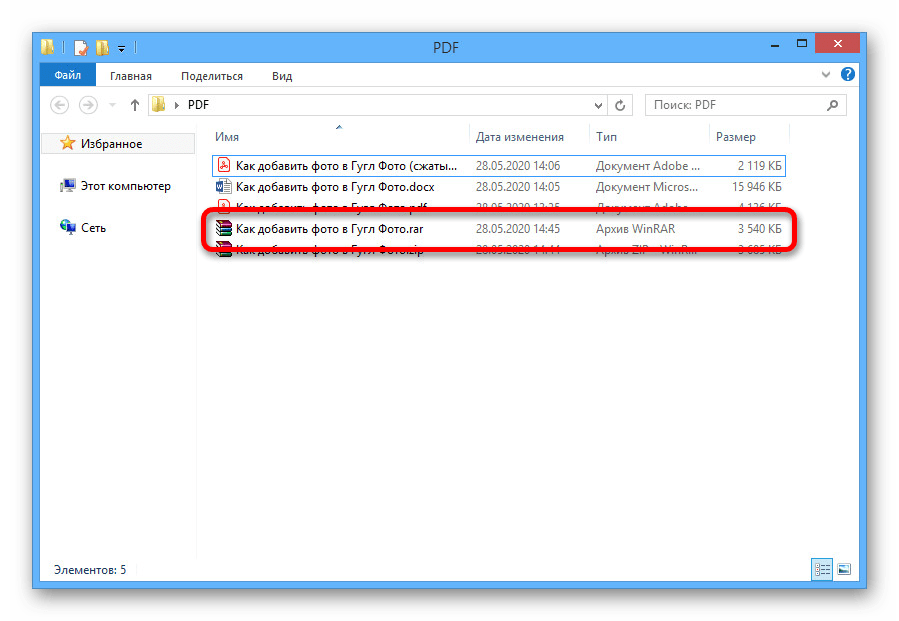 Назначение таблицы перекрестных ссылок состоит в том, что она обеспечивает произвольный доступ к объектам в файле, поэтому нам не нужно читать весь PDF-документ, чтобы найти конкретный объект. Каждый объект представлен одной записью в таблице перекрестных ссылок, длина которой всегда составляет 20 байт. Покажем пример:
Назначение таблицы перекрестных ссылок состоит в том, что она обеспечивает произвольный доступ к объектам в файле, поэтому нам не нужно читать весь PDF-документ, чтобы найти конкретный объект. Каждый объект представлен одной записью в таблице перекрестных ссылок, длина которой всегда составляет 20 байт. Покажем пример:
[простой]
xref
0 1
0000000023 6557 0000000023 6557 000000000023 00000 n
21 4
000007 0000018 00002 00000 n
00000032 00000 n
0000000024 00001 F
000000000000 00001 F
36 1
0000026900 00000 N
[/ ]
Мы можем отобразить таблицу перекрестных ссылок PDF-документа, просто открыв PDF-файл в текстовом редакторе и прокрутив его до конца.В приведенном выше примере мы видим, что у нас есть четыре подраздела (обратите внимание на четыре строки, которые содержат только два числа). Первое число в этих строках соответствует номеру объекта, а вторая строка указывает количество объектов в текущем подразделе. Каждый объект представлен одной записью длиной 20 байт (включая CRLF).
Каждый объект представлен одной записью длиной 20 байт (включая CRLF).
Первые 10 байтов — это смещение объекта от начала документа PDF до начала этого объекта. Далее следует пробел с другим числом, указывающим номер поколения объекта.После этого следует еще один разделитель пробела, за которым следует буква «f» или «n», чтобы указать, свободен ли объект или используется.
Первый объект имеет идентификатор 0 и всегда содержит одну запись с номером поколения 65535, которая находится во главе списка свободных объектов (обратите внимание на букву «f», которая означает «свободный»). Последний объект в таблице перекрестных ссылок использует номер поколения 0.
. Второй подраздел имеет идентификатор объекта 3 и содержит один элемент, объект 3, который начинается со смещения 25324 байта от начала документа.Третий подраздел содержит четыре объекта, первый из которых имеет идентификатор 21 и начинается со смещения 25518 от начала файла. Другие объекты имеют последующие номера 22, 23 и 24.
Все объекты отмечены флажком «f» или «n». Флаг «f» означает, что объект все еще может присутствовать в файле, но помечен как свободный, поэтому его нельзя использовать. Эти объекты содержат ссылку на следующий свободный объект и номер поколения, который будет использоваться, если объект снова станет действительным. Флаг «n» используется для представления действительных и используемых объектов, которые содержат смещение от начала файла и номер поколения объекта.
Обратите внимание, что нулевой объект указывает на следующий свободный объект в таблице, объект 23. Поскольку объект 23 также свободен, он сам указывает на следующий свободный объект в таблице, объект 24. Но объект 24 является последним свободным объектом в таблице. файл, поэтому он указывает на нулевой объект. Если мы представим приведенную выше таблицу перекрестных ссылок с каждым номером объекта, это будет выглядеть следующим образом:
[простой]
xref
0 1
0000000023 65535 F
3 1
0000025324 00000 N
21 1
000007 22 1
0000025632 00000 N
23 1
0000000024 00001 F
24 1
0000000000 00001 F
36 1
0000026900 00000 п
[/простой]
Номер поколения объекта увеличивается, когда объект освобождается, поэтому, если объект снова становится действительным (меняет флаг с «f» на «n»), номер поколения все еще действителен без необходимости его увеличения.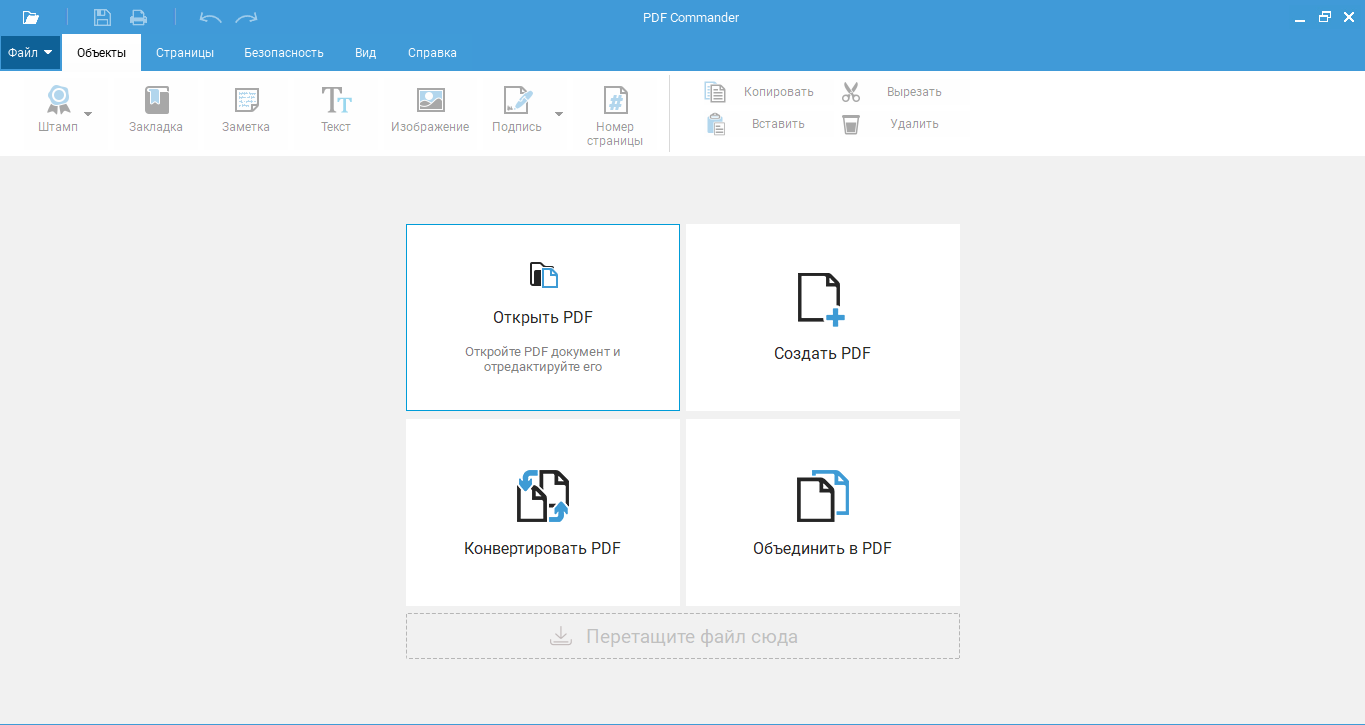 Номер поколения объекта 23 равен 1, поэтому, если он снова станет действительным, номер поколения по-прежнему будет 1, но если его снова удалить, номер поколения увеличится до 2.
Номер поколения объекта 23 равен 1, поэтому, если он снова станет действительным, номер поколения по-прежнему будет 1, но если его снова удалить, номер поколения увеличится до 2.
Обычно в PDF-документах, которые постепенно обновляются, присутствует несколько подразделов, в противном случае должен присутствовать только один подраздел, начинающийся с нулевого числа.
Прицеп
Трейлер PDF указывает, как приложение, читающее PDF-документ, должно находить таблицу перекрестных ссылок и другие специальные объекты.Все программы чтения PDF должны начинать чтение PDF с конца файла. Пример прицепа представлен ниже:
прицеп
&lt;<
/Размер 22
/Корень 2 0 R
/Информация 1 0 R
&gt;&gt;
startxref
24212
%%EOF
Последняя строка документа PDF содержит конец строки файла «%%EOF». Перед концом тега файла находится строка со строкой startxref , указывающая смещение от начала файла до таблицы перекрестных ссылок. В нашем случае таблица перекрестных ссылок начинается со смещения 24212 байт. Перед этим находится строка трейлера , которая указывает начало раздела трейлера. Содержимое концевых разделов заключено в символы << и >> (это словарь, который принимает пары ключ-значение).
В нашем случае таблица перекрестных ссылок начинается со смещения 24212 байт. Перед этим находится строка трейлера , которая указывает начало раздела трейлера. Содержимое концевых разделов заключено в символы << и >> (это словарь, который принимает пары ключ-значение).
Мы видим, что раздел трейлера определяет несколько клавиш, каждая из которых предназначена для определенного действия. В разделе трейлера можно указать следующие ключи:
- /Size [целое число]: указывает количество записей в таблице перекрестных ссылок (включая объекты в обновляемых разделах).Используемый номер не должен быть косвенной ссылкой.
- /Prev [целое число]: указывает смещение от начала файла до предыдущего раздела перекрестных ссылок, которое используется при наличии нескольких разделов перекрестных ссылок. Номер должен быть перекрестной ссылкой.
- /Root [словарь]: указывает объект ссылки для объекта каталога документов, который является специальным объектом, содержащим различные указатели на различные виды других специальных объектов (подробнее об этом позже).
- /Encrypt [словарь]: указывает словарь шифрования документа.
- /Info [словарь]: указывает ссылочный объект для информационного словаря документа.
- /ID [массив]: задает массив двухбайтовых незашифрованных строк, формирующих идентификатор файла.
- /XrefStm [целое число]: указывает смещение от начала файла до потока перекрестных ссылок в декодированном потоке. Это присутствует только в файлах гибридных ссылок, что указано, если мы также хотим открывать документы, даже если приложения не поддерживают потоки сжатых ссылок.
Мы должны помнить, что исходная структура может быть изменена, если мы обновим документ PDF позже. Обновление обычно добавляет дополнительные элементы в конец файла.
Добавочные обновления
PDF был разработан с учетом добавочных обновлений, поскольку мы можем добавлять некоторые объекты в конец файла PDF без перезаписи всего файла. Благодаря этому изменения в документе PDF можно быстро сохранить. Новую структуру PDF-документа можно увидеть на картинке ниже:
Новую структуру PDF-документа можно увидеть на картинке ниже:
Рисунок 3: Структура PDF
Мы видим, что документ PDF по-прежнему содержит исходный заголовок, тело, таблицу перекрестных ссылок и трейлер.Кроме того, в документ PDF были добавлены другие разделы основной части, перекрестных ссылок и трейлеров. Дополнительные разделы перекрестных ссылок будут содержать только записи для объектов, которые были изменены, заменены или удалены. Удаленные объекты останутся в файле, но будут помечены флагом «f». Каждый трейлер должен заканчиваться тегом «%%EOF» и должен содержать запись /Prev, указывающую на предыдущий раздел перекрестных ссылок.
В версиях PDF 1.4 и выше мы можем указать запись версии в словаре каталога документа, чтобы переопределить версию по умолчанию из заголовка PDF.
Пример
Давайте представим простой пример PDF и проанализируем его. Давайте загрузим образец PDF-документа отсюда и проанализируем его. При открытии этого PDF-документа он выглядит так, как показано ниже:
При открытии этого PDF-документа он выглядит так, как показано ниже:
Рисунок 4: Образец документа PDF
Разделы перекрестных ссылок и трейлеров представлены на рисунке ниже:
Рисунок 5: Перекрестные ссылки и конечные разделы
Раздел перекрестных ссылок был сокращен для ясности.Раздел перекрестных ссылок содержит один подраздел, содержащий 223 объекта. Раздел трейлера начинается со смещения байта 50291, включает 223 объекта, где корневой элемент указывает на объект 221, а информационный элемент указывает на объект 222.
В следующем разделе мы рассмотрим основные типы данных структуры PDF.
Типы данных PDF
Документ PDF содержит восемь основных типов объектов, описанных ниже. Это следующие типы: логические значения, числа, строки, имена, массивы, словари, потоки и нулевой объект.Объекты могут быть помечены, чтобы на них могли ссылаться другие объекты. Помеченный объект также называется косвенным объектом.
Булевы значения
Есть два ключевых слова: true и false , которые представляют логические значения.
Числа
В документе PDF есть два типа чисел: целые и действительные. Целое число состоит из одной или нескольких цифр, которым может предшествовать знак плюс или минус. Пример целочисленных объектов можно увидеть ниже:
Действительное значение может быть представлено одной или несколькими цифрами, с необязательным знаком и начальным, конечным или встроенным десятичным запятым (точкой).Пример реальных чисел можно увидеть ниже:
- 123,0 -123,0 +123,0 123. -0,123
Имена
Имена в документах PDF представлены последовательностью символов ASCII в диапазоне от 0x21 до 0x7E. Исключением являются символы: %, (, ), <, >, [, ], {, }, / и #, перед которыми должна стоять косая черта. Альтернативным представлением символов является их шестнадцатеричный эквивалент, которому предшествует символ «#». Существует ограничение длины элемента имени, которое может составлять всего 127 байт.
При написании имени необходимо использовать косую черту для введения имени; косая черта не является частью имени, а является префиксом, указывающим, что далее следует последовательность символов, представляющая имя. Если мы хотим использовать пробел или любой другой специальный символ как часть имени, он должен быть закодирован двузначным шестнадцатеричным представлением.
Примеры имен можно увидеть в таблице ниже:
Рисунок 6: имен PDF (источник)
Струны
Строки в PDF-документе представлены в виде последовательности байтов, заключенных в скобки или угловые скобки, но могут иметь максимальную длину 65535 байт.Любой символ может быть представлен в виде ASCII, а также в восьмеричном или шестнадцатеричном представлении. Восьмеричное представление требует, чтобы символ был записан в форме ддд, где ддд — восьмеричное число. Шестнадцатеричное представление требовало, чтобы символ был записан в форме

Пример представления строки в круглых скобках можно увидеть ниже:
Пример представления строки, заключенной в угловые скобки, можно увидеть ниже (шестнадцатеричное представление ниже такое же, как и выше, и оно читается как «mystring»):
Мы также можем использовать специальные известные символы при представлении строки.Это: n для новой строки, r для возврата каретки, t для горизонтального табулятора, b для возврата, f для перевода страницы, ( для левой скобки, ) для правой скобки и для обратной косой черты.
Массивы
Массивы в документах PDF представлены в виде последовательности объектов PDF, которые могут быть разных типов и заключены в квадратные скобки. Вот почему массив в документе PDF может содержать любые типы объектов, такие как числа, строки, словари и даже другие массивы. Массив также может иметь нулевые элементы.Массив представлен квадратной скобкой. Пример массива представлен ниже:
- 123 123.0 правда (mystring) /myname]
Словари
Словари в документе PDF представлены в виде таблицы пар ключ/значение. Ключ должен быть объектом имени, тогда как значением может быть любой объект, включая другой словарь. Максимальное количество статей в словаре — 4096 статей. Словарь может быть представлен статьями, заключенными в двойные угловые скобки << и >>.Пример словаря представлен ниже:
Ключ должен быть объектом имени, тогда как значением может быть любой объект, включая другой словарь. Максимальное количество статей в словаре — 4096 статей. Словарь может быть представлен статьями, заключенными в двойные угловые скобки << и >>.Пример словаря представлен ниже:
<< /mykey1 123
/mykey2 0,123
/mykey3 << /mykey4 правда
/mykey5 (mystring)
>>
>>
Потоки
Потоковый объект представлен последовательностью байтов и может быть неограниченной длины, поэтому изображения и другие блоки больших данных обычно представляются в виде потоков.Объект потока представлен объектом словаря, за которым следует поток ключевых слов, за которым следуют новая строка и конец потока.
Пример объекта потока можно увидеть ниже:
<<
/Тип /Страница
/Длина 23 0 R
/Фильтр/LZWDecode
>>
поток
…
endstream
Все объекты потока должны быть косвенными объектами, а словарь потока должен быть прямым объектом. Словарь потока указывает точное количество байтов потока.После данных должен быть символ новой строки и ключевое слово endstream.
Словарь потока указывает точное количество байтов потока.После данных должен быть символ новой строки и ключевое слово endstream.
Общие ключевые слова, используемые во всех потоковых словарях, следующие (обратите внимание, что запись длины является обязательной):
- Длина: сколько байт файла PDF используется для данных потока. Если поток содержит запись фильтра, длина должна указывать количество байтов закодированных данных.
- Тип: тип объекта PDF, который описывает словарь.
- Фильтр: имя фильтра, который будет применяться при обработке данных потока.Можно указать несколько фильтров в том порядке, в котором они должны применяться.
- DecodeParms: словарь или массив словарей, используемых фильтрами, заданными параметром Filter. Это значение указывает параметры, которые необходимо передать фильтрам при их применении. В этом нет необходимости, если фильтры используют значения по умолчанию.
- F: Указывает файл, содержащий данные потока.
- FFilter: имя фильтра, который будет применяться при обработке данных, найденных во внешнем файле потока.
- FDecodeParms: словарь или массив словарей, используемых фильтрами, указанными в FFilter.
- DL: указывает количество байтов в декодированном потоке. Это можно использовать, если на диске достаточно места для записи потока в файл.
- N: количество косвенных объектов, хранящихся в потоке.
- Первый: смещение в декодированном потоке первого сжатого объекта.
- Расширяет: указывает ссылку на другие потоки объектов, формирующие дерево наследования.

Данные потока в потоке объектов будут содержать N пар целых чисел, где первое целое число представляет номер объекта, а второе целое число представляет смещение в декодированном потоке этого объекта. Объекты в потоках объектов являются последовательными, и их не нужно хранить в порядке возрастания относительно номера объекта. Первая запись в словаре идентифицирует первый объект в потоке объектов.
Мы не должны хранить следующую информацию в потоке объектов:
- Потоковые объекты
- Объекты с номером поколения, отличным от нуля
- Словарь шифрования документа
- Косвенный объект записи длины в словаре потока объектов
- Каталог документов, словарь линеаризации, страничные объекты
В формате PDF 1.5, информация о перекрестных ссылках может храниться в потоке перекрестных ссылок вместо таблицы перекрестных ссылок. Каждый поток перекрестных ссылок содержит информацию, эквивалентную таблице перекрестных ссылок и трейлеру.
Нулевой объект
Нулевой объект представлен ключевым словом «null».
Косвенные объекты
Прежде всего, мы должны знать, что любой объект в документе PDF может быть помечен как косвенный объект. Это дает объекту уникальный идентификатор объекта, который другие объекты могут использовать для ссылки на косвенный объект.Косвенный объект — это пронумерованный объект, представленный ключевыми словами «obj» и «endobj». Endobj должен присутствовать в отдельной строке, но obj должен располагаться в конце строки идентификатора объекта, которая является первой строкой косвенного объекта. Строка идентификатора объекта состоит из номера объекта, номера поколения и ключевого слова «obj». Пример косвенного объекта:
Endobj должен присутствовать в отдельной строке, но obj должен располагаться в конце строки идентификатора объекта, которая является первой строкой косвенного объекта. Строка идентификатора объекта состоит из номера объекта, номера поколения и ключевого слова «obj». Пример косвенного объекта:
2 1 obj
12345
endobj
В приведенном выше примере мы создаем новый косвенный объект, который содержит объект номер 12345.Объявив объект косвенным объектом, мы можем использовать его в таблице перекрестных ссылок PDF-документа и повторно использовать его на любой странице, словаре и т. д. в документе. Поскольку каждый косвенный объект имеет свою собственную запись в таблице перекрестных ссылок, доступ к косвенным объектам можно получить очень быстро.
Идентификатор объекта косвенного объекта состоит из двух частей; первая часть — это номер текущего косвенного объекта. Непрямые объекты не обязательно должны быть последовательно пронумерованы в документе PDF.Вторая часть — это номер поколения, который устанавливается равным нулю для всех объектов во вновь созданном файле. Позже это число увеличивается при обновлении объектов.
Позже это число увеличивается при обновлении объектов.
Мы можем обращаться к косвенным объектам с косвенной ссылкой, которая состоит из номера объекта, номера поколения и ключевого слова R. Чтобы сослаться на указанный выше косвенный объект, мы должны написать что-то вроде следующего:
Если мы пытаемся сослаться на неопределенный объект, мы на самом деле ссылаемся на нулевой объект.
Структура документа
Документ PDF состоит из объектов, содержащихся в разделе body файла PDF. Большинство объектов в документе PDF являются словарями. Каждая страница документа представлена объектом страницы, который представляет собой словарь, включающий ссылки на содержимое страницы. Объекты страницы связаны между собой и образуют дерево страниц, которое объявляется косвенной ссылкой в каталоге документов.
Всю структуру PDF-документа можно представить на рисунке ниже [1]:
Рисунок 7: Структура PDF-документа (исходник)
На картинке выше мы видим, что каталог документов содержит ссылки на дерево страниц, иерархию структуры, ветки статей, именованные места назначения и интерактивную форму. Мы не будем вдаваться в подробности того, что делает каждый из этих разделов, а представим только самый важный раздел — Дерево страниц.
Мы не будем вдаваться в подробности того, что делает каждый из этих разделов, а представим только самый важный раздел — Дерево страниц.
Каталог документов
Из рисунка выше видно, что каталог документов является корнем объектов в документе PDF. Мы уже говорили, что именно элемент /Root в разделе Trailer PDF указывает каталог документов. Каталог документов содержит ссылки на другие объекты, определяющие содержание документа. Он также содержит информацию, определяющую, как документ будет отображаться на экране.Записи в каталоге документов следующие:
- /Type: тип объекта PDF, который описывает каталог (в нашем случае это Catalog, так как это объект каталога документов).
- /Версия: Версия спецификации PDF, на основе которой был создан документ.
- /Extensions: информация о расширениях разработчика в этом документе.
- /Pages: косвенная ссылка на объект, являющийся корнем дерева страниц документа.
- /Dests: косвенная ссылка на объект, который является корнем именованного объекта назначения.
- /Outlines: косвенная ссылка на объект каталога структуры, который является корнем иерархии схемы документа.
- /Threads: косвенная ссылка на массив словарей потоков, представляющих темы статей документа.
- /Metadata: косвенная ссылка на поток метаданных, содержащий метаданные для документа.

Есть много других записей, которые мы видим как часть каталога документов, но не будем описывать их здесь.Подробности читатель может посмотреть в наших источниках. Пример каталога документов представлен ниже:
1 0 obj
<< /Тип /Каталог
/Страниц 2 0 R
/Пейджмоде/UseOutlines
/Контуры 3 0 R
>>
эндообъект
Дерево страниц
Доступ к страницам документа осуществляется через дерево страниц, которое определяет все страницы в документе PDF. Дерево содержит узлы, представляющие страницы PDF-документа, которые могут быть двух типов: промежуточные и конечные узлы.Промежуточные узлы также называются узлами дерева страниц, а конечные узлы называются объектами страниц.
Простейшая структура дерева страниц может состоять из одного узла дерева страниц, который напрямую ссылается на все объекты страницы (таким образом, все объекты страницы являются листами).
Каждый узел в дереве страниц должен иметь следующие записи:
- /Type: Тип объекта PDF, который описывает этот объект (в нашем случае это Pages , так как мы говорим об узлах дерева страниц).
- /Parent: Должен присутствовать во всех узлах дерева страниц, кроме корневого, где эта запись не должна присутствовать. Эта запись указывает своего родителя.
- /Kids: Должен присутствовать во всех узлах дерева страниц, кроме конечных, и указывает все дочерние элементы, непосредственно доступные из текущего узла.
- /Count: указывает количество конечных узлов, которые являются потомками этого узла в последующем дереве страниц.
Мы должны помнить, что дерево страниц не относится ни к чему в документе PDF, например к страницам или главам.
Базовый пример дерева страниц можно увидеть ниже:
2 0 obj
<< /Тип /Страницы
/Дети [ 4 0 R
10 0 Р
24 0 Р
]
/Количество 3
>>
эндообъект
4 0 объект
<< /Тип /Страница
…
>>
эндообъект
10 0 объект
<< /Тип /Страница
…
>>
эндообъект
24 0 объект
<< /Тип /Страница
…
>>
endobj
Приведенное выше дерево страниц определяет объект Root с идентификатором 2, у которого есть три дочерних объекта: объекты 4, 10 и 20.Мы также можем видеть, что листья дерева страниц — это словари, определяющие атрибуты отдельной страницы документа. Есть несколько атрибутов, которые мы можем использовать при их определении для каждой страницы документа.
Мы рассмотрели базовую структуру PDF-документа и его типы данных. Если мы хотим начать поиск уязвимостей в читалках PDF, нам нужно изменить PDF-документ таким образом, чтобы читатель PDF не смог с ним справиться и вылетал. Обычно, если мы можем вызвать сбой программы для чтения PDF, мы обнаруживаем уязвимость в системе безопасности, которую мы можем использовать для выполнения произвольного кода на целевой машине.
Если мы хотим начать поиск уязвимостей в читалках PDF, нам нужно изменить PDF-документ таким образом, чтобы читатель PDF не смог с ним справиться и вылетал. Обычно, если мы можем вызвать сбой программы для чтения PDF, мы обнаруживаем уязвимость в системе безопасности, которую мы можем использовать для выполнения произвольного кода на целевой машине.
Пример
В этой статье мы рассмотрим очень простой пример PDF-документа. Сначала нам нужно создать PDF-документ, чтобы затем попытаться его проанализировать. Чтобы создать документ PDF, давайте сначала создадим очень простой документ .tex, содержащий то, что можно увидеть на рисунке ниже:
.Рисунок 8: Простой документ
Мы видим, что документ .tex содержит немногое. Во-первых, мы определяем документ как статью, а затем включаем содержимое статьи в начальный и конечный документ.Мы включаем новый раздел с заголовком (Введение) и включаем статический текст «Hello World!».
Мы можем скомпилировать документ . tex в документ PDF с помощью команды pdflatex и указать имя файла .tex в качестве аргумента. Полученный PDF-файл выглядит так, как показано на рисунке ниже:
tex в документ PDF с помощью команды pdflatex и указать имя файла .tex в качестве аргумента. Полученный PDF-файл выглядит так, как показано на рисунке ниже:
Рисунок 9: Результат
Мы видим, что документ PDF на самом деле не содержит очень многого, только текст, который мы на самом деле включили, и никаких изображений, JavaScript или других элементов.
Пример 1
Давайте посмотрим на структуру PDF-документа, которая представлена в выводе ниже:
%PDF-1.5
%РФШ
3 0 объект <<
/Длина 138
/Фильтр /FlateDecode
>>
поток
…
конечный поток
эндообъект
10 0 объект <<
/Длина2 1526
/Длина3 7193
/Длина4 0
/Длина 8194
/Фильтр /FlateDecode
>>
поток
…
конечный поток
эндообъект
12 0 объект <<
/Длина2 1509
/Длина3 9410
/Длина4 0
/Длина 10422
/Фильтр /FlateDecode
>>
поток
…
конечный поток
эндообъект
15 0 объект <<
/Производитель (pdfTeX-1. 40.12)
40.12)
/Создатель (TeX)
/Дата Создания (D:20121012175007+02’00’)
/ModDate (D:20121012175007+02’00’)
/В ловушке /Ложь
/PTEX.Fullbanner (это pdfTeX, версия 3.1415926-2.3-1.40.12 (TeX Live 2011) kpathsea версия 6.0.1)
>> эндобж
6 0 объект <<
/Тип /ObjStm
/№ 10
/Первый 65
/Длина 761
/Фильтр /FlateDecode
>>
поток
…
конечный поток
эндообъект
16 0 объект <<
/Тип /XRef
/Индекс [0 17]
/Размер 17
/Вт [1 2 1]
/Корень 14 0 R
/Информация 15 0 R
/ID [<1DC2E3E09458C9B4BEC8B67F56B57B63> <1DC2E3E09458C9B4BEC8B67F56B57B63>]
/Длина 60
/Фильтр /FlateDecode
>>
поток
…
конечный поток
эндообъект
стартксссылка
20215
%%EOF
Для создания такого простого документа PDF достаточно много необходимых элементов, поэтому мы можем представить, как будет выглядеть действительно сложный документ PDF. Мы также должны помнить, что все закодированные потоки данных были удалены и заменены тремя точками для ясности и краткости.
Мы также должны помнить, что все закодированные потоки данных были удалены и заменены тремя точками для ясности и краткости.
Давайте представим каждый из разделов PDF. Заголовок можно увидеть на картинке ниже:
Рисунок 10: Заголовок PDF
Тело видно на картинке ниже:
Рис. 11: Корпус PDF
Раздел xref можно увидеть на рисунке ниже:
Рисунок 11: PDF xref
И, наконец, раздел Прицеп представлен ниже:
Рис. 12: Прицеп PDF
Мы представили все разделы PDF-документа, но нам еще предстоит их проанализировать.Заголовок PDF-документа стандартный и нам особо о нем говорить не нужно, а раздел body оставим на потом.
Вот почему мы должны сначала взглянуть на раздел внешних ссылок. Мы видим, что смещение от начала файла до таблицы xref составляет 20215 байт, что в шестнадцатеричном виде равно 0x4ef7.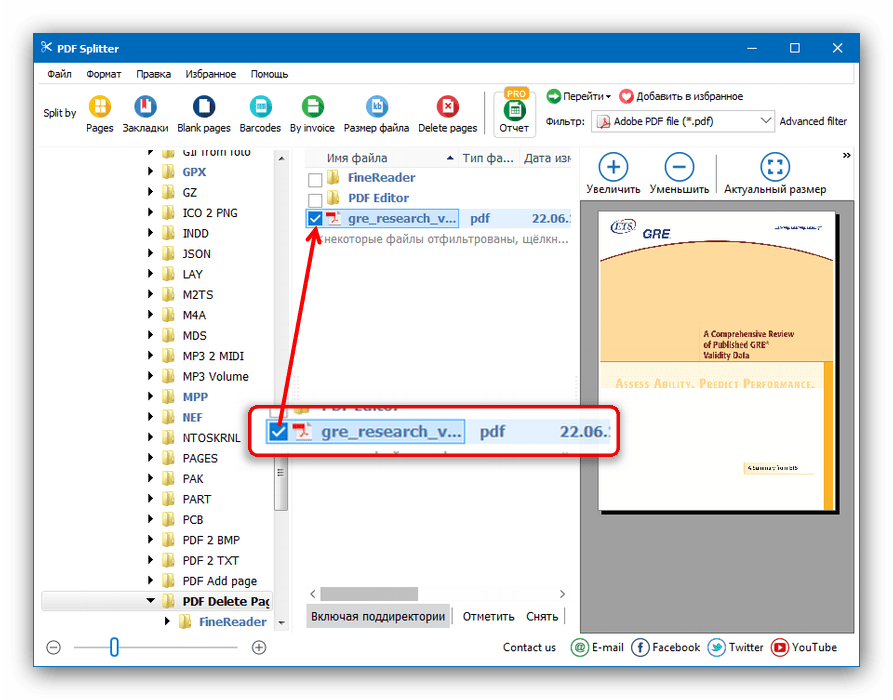 Если мы посмотрим на шестнадцатеричное представление файла, которое мы можем получить с помощью инструмента xxd, мы увидим то, что представлено на рисунке ниже:
Если мы посмотрим на шестнадцатеричное представление файла, которое мы можем получить с помощью инструмента xxd, мы увидим то, что представлено на рисунке ниже:
Рисунок 13: Шестнадцатеричное представление файла
Выделенные байты лежат точно в начале смещения 20125 байт от начала файла.Предыдущие байты 0x0a — это новая строка, а текущие байты 0x31 представляют собой число 1, которое точно является началом таблицы внешних ссылок. Вот почему таблица внешних ссылок представлена косвенным объектом с идентификатором 16 и номером поколения 0. (Это должно иметь место для всех объектов, поскольку мы только что создали документ PDF и ни один из объектов еще не был изменен. Если мы посмотрите на весь документ в формате PDF, мы увидим, что это совершенно верно, все объекты имеют нулевой номер поколения.)
Параметр /Type косвенного объекта классифицирует его как таблицу внешних ссылок.Массив /Index содержит пару целых чисел для каждого подраздела в этом разделе. Первое целое число указывает номер первого объекта в подразделе, а второе целое число указывает количество записей в подразделе. В нашем примере номер объекта равен нулю, а в этом подразделе 17 записей. Это также определяется директивой /Size. Обратите внимание, что это число на единицу больше, чем наибольшее число любого номера объекта в подразделе. Атрибут /W указывает массив целых чисел, представляющих размер полей в записи перекрестной ссылки, что означает, что поля имеют размер один байт, два байта и один байт.
Первое целое число указывает номер первого объекта в подразделе, а второе целое число указывает количество записей в подразделе. В нашем примере номер объекта равен нулю, а в этом подразделе 17 записей. Это также определяется директивой /Size. Обратите внимание, что это число на единицу больше, чем наибольшее число любого номера объекта в подразделе. Атрибут /W указывает массив целых чисел, представляющих размер полей в записи перекрестной ссылки, что означает, что поля имеют размер один байт, два байта и один байт.
После этого следует элемент /Root, указывающий, что каталог каталога для документа PDF должен быть номером объекта 14. /Info — это информационный каталог документа PDF, который содержится в объекте номер 15. Массив /ID необходим, поскольку Запись шифрования присутствует и содержит две строки, составляющие идентификатор файла. Эти две строки используются в качестве входных данных для алгоритма шифрования.
Параметр /Length указывает длину ключа шифрования в битах; значение должно быть кратно 8 в диапазоне от 40 до 128 (значение по умолчанию — 40). В нашем случае длина ключа шифрования составляет 60 бит. Параметр /Filter указывает имя обработчика безопасности для этого документа; это также обработчик безопасности, который использовался для шифрования документа. В нашем случае это FlateDecode, который кодирует данные методом сжатия zlib/deflate.
В нашем случае длина ключа шифрования составляет 60 бит. Параметр /Filter указывает имя обработчика безопасности для этого документа; это также обработчик безопасности, который использовался для шифрования документа. В нашем случае это FlateDecode, который кодирует данные методом сжатия zlib/deflate.
Мы видим, что другая часть таблицы внешних ссылок сжата, поэтому мы не можем ее прочитать. Мы могли бы, конечно, применить к сжатым данным какой-нибудь алгоритм декомпрессии zlib, но есть вариант получше.Зачем нам писать для этого программу, если инструмент уже существует? С помощью pdftk мы можем восстановить поврежденную таблицу внешних ссылок PDF с помощью следующей команды:
- # pdftk in.pdf output out.pdf
После этого файл out.pdf содержит следующие разделы xref и trailer:
Рис. 14. Внешняя ссылка и трейлер
Понятно, что изменились номера объектов /Root и /Info и другие вещи, но мы получили ключевые слова trailer и xref, которые определяют таблицу xref. Мы видим, что в таблице внешних ссылок 14 объектов.
Мы видим, что в таблице внешних ссылок 14 объектов.
Мы могли бы продолжить и попытаться расшифровать и другие разделы, но это выходит за рамки данной статьи. Далее мы проверим документ, который не закодирован.
Пример 2
Давайте взглянем на образец PDF-документа, который доступен здесь. Некоторые объекты потока зашифрованы, но сейчас это не так важно. Поскольку мы уже знаем, как работать с PDF-документами, мы не будем терять слишком много слов на простых вещах.
Давайте откроем этот PDF-файл в текстовом редакторе, таком как gvim, и просмотрим раздел трейлера.Мы уже должны знать, что все PDF-документы следует читать с конца до начала. Прицеп представлен на картинке ниже:
Рис. 15: Прицеп PDF
Давайте также представим внешнюю ссылку всего несколькими объектами (остальные для ясности отброшены):
Рисунок 16: PDF xref
Мы видим, что /Root документа PDF содержится в объекте с идентификатором 221, а в объекте 222 есть дополнительная информация. Объект 221 — самый важный объект во всем документе, поэтому представим его:
Объект 221 — самый важный объект во всем документе, поэтому представим его:
Рисунок 17: Объект 221
Мы видим, что объект действительно является каталогом документов. Объект дерева страниц — 212, объект Outlines — 213, объект Names — 220, а объект OpenAction — 58. Мы не говорили ни о каких других типах, кроме объекта дерева страниц, поэтому продолжим разговор о дереве страниц. Только.
Объект «Дерево страниц» с ID 212 представлен на рисунке ниже:
Рисунок 18: Объект дерева страниц
Таким образом, объект 212 содержит фактические страницы PDF-документа.Он содержит 10 страниц, что совершенно верно (мы можем проверить это, если откроем PDF-файл в любой программе для чтения PDF-файлов и проверим количество страниц).
Мы знаем, что атрибут Kids определяет все дочерние элементы, непосредственно доступные из текущего узла. В нашем случае есть два прямых дочерних узла с идентификаторами объекта 66 и 135. Объект 66 представлен ниже:
Объект 66 представлен ниже:
Рисунок 19: Объект 66
Объект 66 содержит другие дочерние элементы с идентификаторами 57, 69, 75, 97, 108 и 120.
Рисунок 20: Объект 135
Объект 135 дополнительно определяет объекты 129, 138, 133 и 158.
Если мы посчитаем все элементы, то увидим, что элементов ровно 10, что означает 10 страниц из 10 страниц. Это также означает, что все представленные объекты на самом деле являются фактическими страницами PDF-документа и не содержат никаких дополнительных дочерних узлов.
Все представленные объекты объявляются одинаково, поэтому не будем рассматривать каждый из объектов по очереди.Вместо этого мы просто взглянем на один объект, а именно на объект 57. Объект 57 содержит объявлено следующим образом:
Рисунок 21: Объект 57
Мы видим, что тип объекта — /Page, что прямо подразумевает, что это конечный узел, представляющий одну из страниц PDF-документа. Содержимое этой страницы PDF можно найти в объекте 62:
Содержимое этой страницы PDF можно найти в объекте 62:
Рис. 22: Объект 62
Мы видим, что фактическое содержимое страницы PDF закодировано с помощью FlateDecode, который представляет собой простой алгоритм кодирования zlib.
Заключение
Мы видели два примера того, как можно создавать PDF-документы. С полученными знаниями мы можем начать генерировать неправильные PDF-документы и передавать их различным программам для чтения PDF-файлов. В случае, если определенная программа чтения PDF дает сбой при чтении определенного документа PDF, этот документ содержит что-то, с чем программа чтения PDF не может справиться. Это подразумевает возможность уязвимости, которую необходимо изучить дополнительно.
В конце концов, если окажется, что уязвимость присутствует, мы можем даже написать PDF-документ, содержащий вредоносный код, который выполняется, когда жертва открывает PDF-документ с помощью уязвимой программы для чтения PDF-файлов на целевой машине. В таких случаях вся машина может быть скомпрометирована, поскольку произвольный вредоносный код может быть запущен, просто открыв вредоносный PDF-документ.
В таких случаях вся машина может быть скомпрометирована, поскольку произвольный вредоносный код может быть запущен, просто открыв вредоносный PDF-документ.
Источники
Статистика уязвимостей, подробности CVE
Политики поддержки Adobe: поддерживаемые версии продуктов, Adobe
Управление документами. Формат переносимых документов. Часть 1: PDF 1.7, Adobe (Archive.org)
Каталожные номера:
[1]: формат файла PDF, доступный по адресу: http://wwwimages.adobe.com/www.adobe.com/content/dam/Adobe/en/devnet/pdf/pdfs/PDF32000_2008.pdf.
PDF по сравнению с другими форматами файлов
Существует ряд других форматов файлов, которые позволяют добиться того же, что и PDF. Ниже я перечислил некоторые из них и попытался объяснить различия или сходства этих альтернатив. Это сравнения, которые сделаны:
PDF по сравнению с XPS
XPS пока что является самой серьезной альтернативой PDF, появившейся на рынке. Дополнительную информацию о XPS можно найти здесь.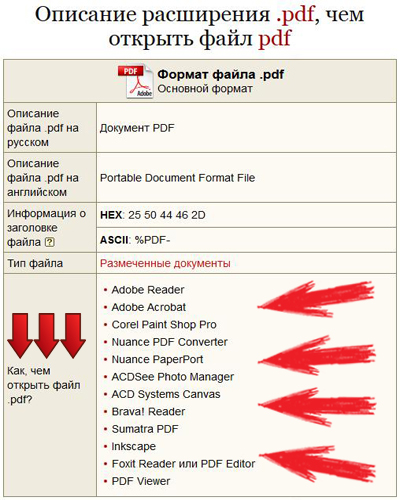 Эта страница также содержит сравнение обоих форматов файлов.
Эта страница также содержит сравнение обоих форматов файлов.
PDF по сравнению с PostScript
PDF был разработан Adobe, компанией, которая также создала PostScript. Фактически, PDF основан на PostScript. Он использует набор инструкций самого PostScript, но по-другому: хотя PostScript на самом деле является языком программирования, который можно использовать даже для написания шахматной программы или текстового процессора, PDF более ограничен в своих целях. Он описывает макет документа (с использованием операторов PostScript).Таким образом, PDF больше напоминает базу данных, чем язык программирования.
Основные преимущества PDF перед PostScript:
- Файлы PDF имеют тенденцию быть меньше из-за более эффективных алгоритмов сжатия, которые можно использовать. Такие алгоритмы, как JBIG2 и Jpeg2000, недоступны в PostScript.
- Файлы PDF можно легко визуализировать с помощью Adobe Reader, Adobe Acrobat или других инструментов.
- Файлы PDF легче модифицировать, если у вас есть соответствующие инструменты.
- PDF поддерживает прозрачность и управление цветом на основе ICC.
- Файлы PDF более независимы от устройства. Файлы PostScript часто создаются для определенного устройства и будут генерировать ошибки PostScript при отправке на другое устройство.
- Файлы PDF могут быть более универсальными, чем файлы PostScript: они могут содержать ссылки на другие данные, а также интерактивные элементы (мультимедиа, формы, 3D и т. д.).
PDF по сравнению с HTML
PDF часто сравнивают с HTML, форматом данных, используемым для создания веб-страниц.Изначально HTML был ориентирован на описание структуры документа, а не его внешнего вида. Внешний вид веб-страницы определяется браузером, а не создателем документа. С ростом популярности Всемирной паутины новые версии HTML больше сосредоточились на визуальном аспекте веб-страниц, а не на их содержании. Таким образом, в некотором смысле HTML приблизился к целям, которых пытается достичь PDF.
В то же время Adobe вкладывает в PDF все больше веб-функций. Мы получили возможность добавлять интернет-ссылки в PDF-документы. Стал доступен подключаемый модуль Adobe Reader для веб-браузеров, таких как Netscape Navigator или Internet Explorer, а в Acrobat 4 есть возможность конвертировать веб-сайт или часть веб-сайта в документ PDF. Adobe также предоставила механизм потоковой передачи байтов в PDF, поэтому вам не нужно загружать весь файл PDF, чтобы увидеть первую страницу документа.
Мы получили возможность добавлять интернет-ссылки в PDF-документы. Стал доступен подключаемый модуль Adobe Reader для веб-браузеров, таких как Netscape Navigator или Internet Explorer, а в Acrobat 4 есть возможность конвертировать веб-сайт или часть веб-сайта в документ PDF. Adobe также предоставила механизм потоковой передачи байтов в PDF, поэтому вам не нужно загружать весь файл PDF, чтобы увидеть первую страницу документа.
Таким образом, PDF и HTML становятся конкурентоспособными стандартами. В настоящее время PDF по-прежнему лучше подходит для описания внешнего вида документов, в то время как HTML лучше подходит для низкоскоростного доступа в Интернет.Но вполне возможно использовать PDF на веб-сайтах и использовать HTML для электронного каталога на компакт-диске.
PDF по сравнению с XML
XML, расширяемый язык разметки, представляет собой формат данных, который можно использовать для описания содержимого документов (аналогично SGML). В последнее время ему уделяется много внимания, главным образом потому, что его гибкость позволяет легко интегрироваться с базами данных, а также публиковать данные в Интернете и обмениваться данными. XML на самом деле не конкурирует с PDF, а улучшает его. В то время как XML описывает содержимое документа, PDF описывает его внешний вид.Вы не можете легко извлечь содержимое документа из PDF, по крайней мере, не без большого количества ручной работы, потому что вся структура документа теряется во время создания документа PDF.
XML на самом деле не конкурирует с PDF, а улучшает его. В то время как XML описывает содержимое документа, PDF описывает его внешний вид.Вы не можете легко извлечь содержимое документа из PDF, по крайней мере, не без большого количества ручной работы, потому что вся структура документа теряется во время создания документа PDF.
Интересно, что в PDF 1.3 появился механизм (дерево структуры), который может содержать XML-подобные данные. Таким образом, теоретически можно создать PDF-документ, содержащий как структурированный обзор содержания документа, так и точное представление его макета. К сожалению, программное обеспечение (т.г. подключаемый модуль XPress) для встраивания XML-данных в файл PDF (с использованием pdfmarks) пока недоступен. Подключаемые модули Acrobat для извлечения данных из дерева структуры и их экспорта в файл, совместимый с XML, также все еще находятся в зачаточном состоянии. Если вам нужны и XML, и PDF, единственный выход сейчас — создать два отдельных файла из приложения макета или из системы публикации баз данных.
В 2006 году Adobe Labs опубликовала первые спецификации для Mars, способа представления PDF-файлов в файле XML. В Acrobat 8 была включена поддержка Mars, но по какой-то причине этот новый подход так и не прижился.
PDF по сравнению с Acrobat
Некоторые люди, кажется, путают PDF, формат данных, с Acrobat, программным пакетом, который Adobe продает для создания, визуализации и обработки PDF-документов. Эта путаница, по-видимому, связана с тем, что до Acrobat 8 каждая новая версия Acrobat приносила новую версию спецификаций PDF. В Acrobat 3 появилась версия 1.2 спецификаций PDF, в Acrobat 4 появился PDF 1.3 и так далее.
Сохранить как или преобразовать публикацию в формат .pdf или .xps с помощью Publisher
Если вы создали публикацию, которой хотите поделиться с другими пользователями, у которых нет Publisher, вы можете сохранить ее в виде файла PDF (формат переносимого документа) или XPS (спецификация бумаги XML). Коммерческие типографии часто предпочитают получать PDF-файл для печати.
Сохраните публикацию в формате PDF или XPS
Выберите PDF, если хотите сохранить публикацию в формате, которым можно легко поделиться и который используется многими коммерческими типографиями.Выберите XPS, если хотите сохранить публикацию с еще большим сжатием, чем в формате PDF. Узнайте больше о форматах PDF и XPS.
Щелкните Файл > Экспорт > Создать документ PDF/XPS > Создать PDF/XPS .
Для Имя файла введите имя публикации.
Для Сохранить как тип выберите PDF или X PS Document .
Нажмите Параметры и выберите вариант публикации, который лучше всего подходит для онлайн-просмотра или просмотра в печати:
Минимальный размер Используйте этот параметр для просмотра в Интернете в виде одной страницы
Стандартный Используйте этот параметр для онлайн-распространения, например по электронной почте, когда получатель может распечатать публикацию на настольном принтере
Высококачественная печать Используйте этот параметр для настольной или копировальной печати
Коммерческая печатная машина Этот параметр создает файлы самого большого размера и самого высокого качества для коммерческой печати
Нажмите OK и нажмите Опубликовать.

Щелкните Файл > Сохранить и отправить > Создать документ PDF/XPS > Создать PDF/XPS .
Для Имя файла введите имя публикации.
Для Сохранить как тип выберите PDF или X PS Document .
Нажмите Параметры и выберите вариант публикации, который лучше всего подходит для онлайн-просмотра или просмотра в печати:
Минимальный размер Используйте этот параметр для просмотра в Интернете в виде одной страницы
Стандартный Используйте этот параметр для онлайн-распространения, например по электронной почте, когда получатель может распечатать публикацию на настольном принтере
Высококачественная печать Используйте этот параметр для настольной или копировальной печати
Коммерческая печатная машина Этот параметр создает файлы самого большого размера и самого высокого качества для коммерческой печати
Нажмите OK и нажмите Опубликовать.
В меню Файл щелкните Опубликовать как PDF или XPS .
В списке Сохранить как тип выберите либо PDF , либо XPS .
По умолчанию ваша публикация будет сохранена с расширением .pdf для расширения .xps, и он будет оптимизирован для высококачественной печати.
Вы можете выбрать другой параметр, нажав Изменить , чтобы открыть диалоговое окно Параметры публикации . Найдите ссылки на дополнительные сведения о диалоговом окне Параметры публикации в разделе См. также .
Щелкните Опубликовать .
Примечание. Вы также можете сохранить файл в формате .pdf с помощью диалогового окна Сохранить как .
Вы также можете сохранить файл в формате .pdf с помощью диалогового окна Сохранить как .
О форматах PDF и XPS
Оба формата файлов предназначены для предоставления документов только для чтения с оптимальным качеством печати. Они также включают все необходимые шрифты, сохраняют метаданные и могут включать гиперссылки.
Получателям требуется программа просмотра, соответствующая формату файлов, прежде чем они смогут просматривать ваши файлы.
Примечание. Эти форматы позволяют другим пользователям просматривать только вашу публикацию. Полученные файлы нельзя изменить в Publisher.
Формат файла | Преимущества | Примечания |
|---|---|---|
PDF (. |
| Требуется Adobe Acrobat Reader. |
XPS (.xps) |
| Требуется правильное средство просмотра, доступное в виде загружаемой надстройки от Microsoft. |
 pdf)
pdf)

PDF-файлы — сколько существует типов? — Юридическая техника — Casedo
Восемь видимо или все-таки три? В наши дни PDF-файлы распространены повсеместно, но, как и Интернет, они существуют недолго.Формат PDF впервые появился в 1993 году, и сейчас для большинства людей это де-факто способ обмена цифровыми документами. Для тех из нас, кто использует PDF-файлы или создает продукты, которые их используют, стоит знать, что скромный PDF-файл вовсе не скромен, их существует множество, и все они соответствуют заданным стандартам.
Этот «диапазон» примерно соответствует различным способам классификации самих PDF-файлов: технические и повседневные. Технически PDF-файлы имеют стандарты ISO и тому подобное, стандарты для различных секторов бизнеса и архивирования, для проектирования и печати.Существуют точечные выпуски (вы слышали о PDF 2.0?) и подмножества (наверняка вы знаете PDF/VT?), ни один из которых, как любой хороший ISO, не затрагивает нашу повседневную жизнь, но является ее скрытой основой.
Технически PDF-файлы имеют стандарты ISO и тому подобное, стандарты для различных секторов бизнеса и архивирования, для проектирования и печати.Существуют точечные выпуски (вы слышали о PDF 2.0?) и подмножества (наверняка вы знаете PDF/VT?), ни один из которых, как любой хороший ISO, не затрагивает нашу повседневную жизнь, но является ее скрытой основой.
Большинству из нас больше интересно, что такое PDF-файлы в повседневном языке, это гораздо проще понять. В зависимости от того, как был создан файл, PDF-документы можно разделить на 3 различных типа . Способ первоначального создания PDF-файла определяет, можно ли получить доступ к содержимому PDF-файла (текст, изображения, таблицы) или оно «заблокировано» в изображении страницы.
9
Повседневные виды PDF:
1.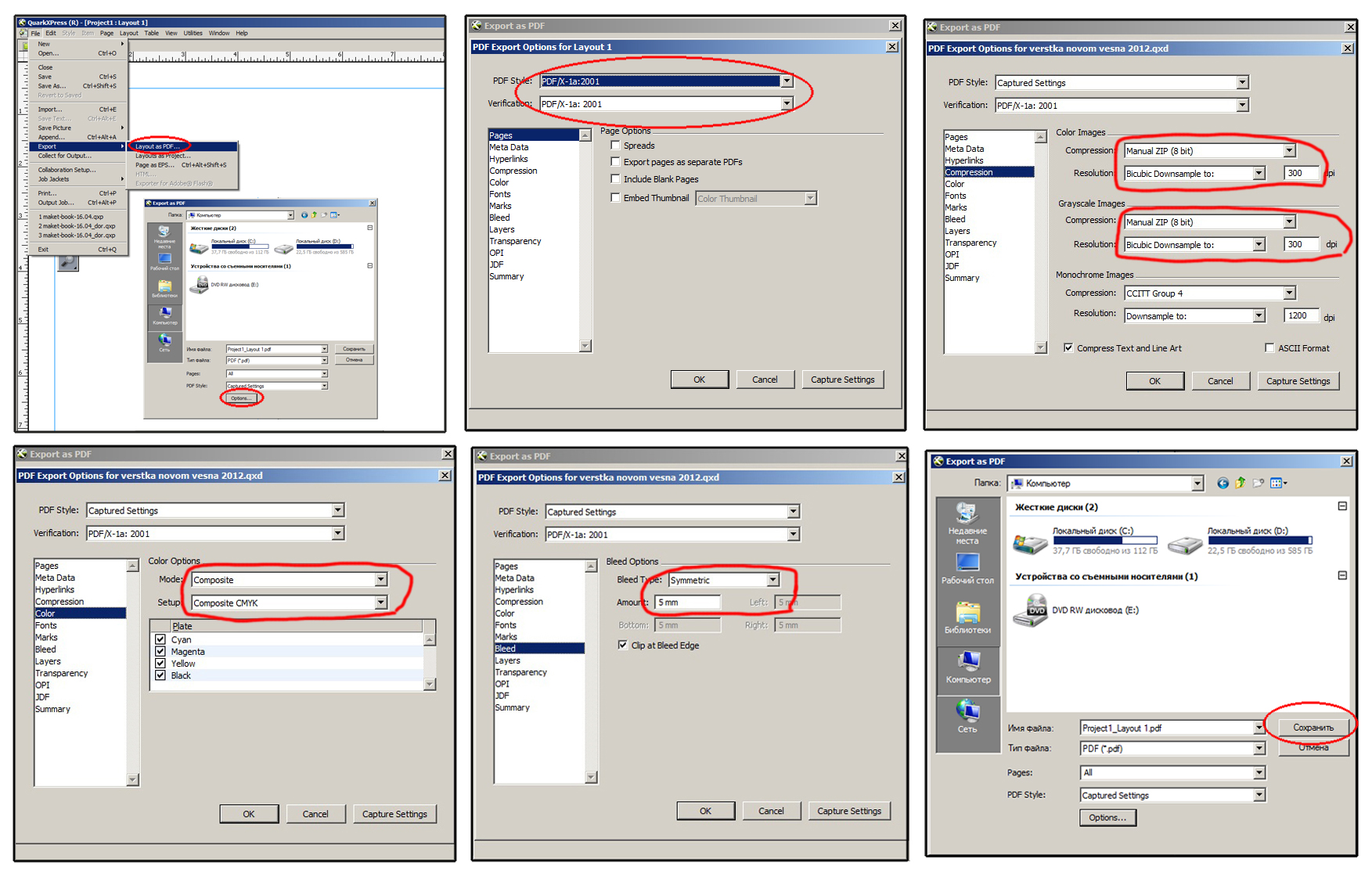 Real PDFS:
Real PDFS:
Real PDF, также известные как цифровые созданные PDF-файлы идеально подходят для большинства приложений. Обычно это идеальный PDF-файл, который позволяет пользователям размечать, комментировать, искать и копировать/вставлять без необходимости делать дополнительные шаги. Их можно легко создать в приложении или с помощью функции «распечатать».Эти типы PDF-файлов можно искать по умолчанию, а содержимое, такое как текст и изображения, можно копировать/вставлять в файлы других форматов.
Как метаинформация, так и символы в тексте содержат обозначение электронного символа. С помощью редакторов PDF и других программ для чтения документов вы можете выполнять поиск в этих PDF-файлах, а также редактировать, выбирать или удалять любой содержащийся в нем контент, если только сам документ не защищен паролем.
2. Отсканированные PDF-файлы:
Отсканированные PDF-файлы представляют собой просто изображение фактического текста, поэтому содержимое «заперто» в образе, похожем на снимок. Это то же самое, что и преобразование изображения с камеры, снимка экрана, jpg или tiff в PDF. Эти файлы PDF, содержащие только изображения, не доступны для поиска, и их текст обычно нельзя изменить или легко разметить. Это связано с тем, что они представляют собой отсканированные/сфотографированные изображения страниц и, следовательно, не имеют основного текстового слоя.
Это то же самое, что и преобразование изображения с камеры, снимка экрана, jpg или tiff в PDF. Эти файлы PDF, содержащие только изображения, не доступны для поиска, и их текст обычно нельзя изменить или легко разметить. Это связано с тем, что они представляют собой отсканированные/сфотографированные изображения страниц и, следовательно, не имеют основного текстового слоя.
Эти типы PDF-файлов, содержащих только изображения, могут быть преобразованы из нечитаемого текста в читаемый текст, и это делается с помощью механизма оптического распознавания символов (OCR).Этот движок добавляет базовый текстовый слой в PDF-файл, похожий на изображение. Следует отметить, что это не то же самое, что просто создание текстового вывода, в результате которого будет создан текстовый документ, возможно, сильно отличающийся по макету от исходного PDF-файла, подробнее см. ниже.
Доступный для поиска PDF-файл является результатом применения функции оптического распознавания символов (OCR) к нечитаемому PDF-файлу или PDF-файлу, похожему на изображение. В процессе распознавания текста анализируются и «читаются» символы и структура документа.Это приводит к тому, что файл PDF имеет 2 слоя: один слой, содержащий изображение, и второй слой, содержащий распознанный текст, который можно искать, комментировать, размечать и копировать/вставлять так же, как в реальном PDF. Такие PDF-файлы практически неотличимы от исходных документов.
В процессе распознавания текста анализируются и «читаются» символы и структура документа.Это приводит к тому, что файл PDF имеет 2 слоя: один слой, содержащий изображение, и второй слой, содержащий распознанный текст, который можно искать, комментировать, размечать и копировать/вставлять так же, как в реальном PDF. Такие PDF-файлы практически неотличимы от исходных документов.
Начиная с версии 1.1.0, Casedo имеет встроенную функцию распознавания текста. Для получения дополнительной информации следуйте этой ССЫЛКЕ .
Ссылки:
- Еще раз о «трех типах PDF-файлов» см. статью на веб-сайте Abbyy
- . для pdf-файлов у Marconet есть хорошее объяснение ЗДЕСЬ
- Iceni Technology кратко рассказывает о «смешанных» pdf-файлах ЗДЕСЬ
- Более в Investintech.com есть еще одна более техническая статья, которая помещает PDF-файлы в историческую перспективу, ЗДЕСЬ
Форматы файлов
EPS — инкапсулированный PostScript
Back to top EPS можно использовать для изображений, созданных приложениями векторного рисования, такими как Adobe Illustrator или CorelDraw. Однако EPS, как правило, является громоздким форматом файла по сравнению с PDF, который является более современным и компактным функциональным эквивалентом EPS, поэтому рекомендуется представлять рисунки в формате PDF.
Однако EPS, как правило, является громоздким форматом файла по сравнению с PDF, который является более современным и компактным функциональным эквивалентом EPS, поэтому рекомендуется представлять рисунки в формате PDF.
Изображения EPS должны быть обрезаны с использованием того же программного обеспечения, которое использовалось для их создания (см. документацию производителя).
Если возникают проблемы с кадрированием изображения EPS, в крайнем случае рассмотрите возможность его растрирования (преобразования из векторного формата в растровый) с помощью Photoshop, обрезки растрового изображения (снова с помощью Photoshop) и отправки полученного растрового изображения в формате TIFF или JPEG. . Однако растеризация обычно увеличивает размер файла и снижает качество по сравнению с векторным изображением.
PDF — переносимый формат документов
Back to top PDF (Portable Document Format)
PDF — превосходный современный формат изображений, который может содержать как векторные, так и растровые элементы.
Чтобы обеспечить высокое качество, очень важно выбрать правильные настройки при создании PDF-файлов. Независимо от того, используете ли вы Adobe Acrobat Distiller или другие инструменты для создания PDF-файлов, авторы должны выбрать соответствующие параметры для создания PDF-файлов с высоким разрешением, подходящих для печати.Это означает, что все графические изображения в PDF-файле должны иметь подходящее разрешение (300 dpi или более при предполагаемом конечном размере рисунка) и что любые нестандартные шрифты встроены.
PDF-файлы должны быть совместимы с Acrobat 5.0 и более поздних версий (т. е. PDF версии 1.4).
Авторы должны убедиться, что рисунки в формате PDF не защищены паролем, так как это препятствует работе BMC с рисунком и может сделать такие рисунки несовместимыми с более ранними версиями Adobe Acrobat.
Файлы PDF можно легко обрезать с помощью полной версии Adobe Acrobat.Выберите «Обрезать страницы» в меню «Документ». Появится диалоговое окно Обрезка страниц. Измените поля страницы, используя клавиши со стрелками вверх и вниз для каждого поля (левого, правого, верхнего, нижнего).
Измените поля страницы, используя клавиши со стрелками вверх и вниз для каждого поля (левого, правого, верхнего, нижнего).
В качестве альтернативы обрезку можно выполнить, выбрав инструмент обрезки на панели инструментов. Здесь границы обрезки устанавливаются путем выбора маркера в углу прямоугольника обрезки и перетаскивания его до нужного размера.
Если возникают проблемы с кадрированием изображения PDF, в крайнем случае рассмотрите возможность его растрирования (преобразования из векторного формата в растровый) с помощью Photoshop, обрезки растрового изображения (снова с помощью Photoshop) и отправки полученного растрового изображения в формате TIFF или JPEG. .Однако растеризация обычно увеличивает размер файла и снижает качество по сравнению с векторным изображением.
ДОКУМЕНТ — Microsoft Word
Back to top DOC (Microsoft Word)
Word подходит для отправки рисунков, содержащих как векторные, так и растровые элементы, для авторов, не имеющих доступа к специализированному пакету чертежей. Диаграммы Excel можно загружать, встраивая их в файл Word.
Диаграммы Excel можно загружать, встраивая их в файл Word.
Рисунки должны быть подготовлены в Word 5 или более поздней версии и быть на одной странице.
Файл DOC должен быть непосредственно загружен в систему отправки. Не конвертируйте в JPEG или другой растровый формат, так как это ухудшит качество. Убедитесь, что все встроенные иллюстрации имеют подходящее разрешение (примерно 300 dpi при масштабировании до ожидаемого размера рисунка в окончательном PDF-файле).
Чтобы обрезать файл DOC, выберите Макет печати в раскрывающемся меню Вид. Затем нажмите «Параметры страницы» в раскрывающемся меню «Файл» и уменьшите поля страницы (вкладка «Поля») до нуля, затем измените размеры страницы (щелкните вкладку «Размер бумаги»), чтобы они соответствовали размеру изображения.
РРТ — PowerPoint
Back to top PPT (Microsoft PowerPoint)
Powerpoint — еще один хороший вариант отправки рисунков, содержащих как векторные, так и растровые элементы, для авторов, не имеющих доступа к специализированному пакету для рисования.
Рисунки должны быть на одном слайде. Не должно быть никакого фонового цвета, если только это не является строго необходимым для фигуры. Название или номер слайда не должны быть включены. Файлы PPT следует загружать непосредственно на сайт, а не преобразовывать в JPEG или другой формат, качество которого может быть снижено.Убедитесь, что все встроенные иллюстрации имеют подходящее разрешение (примерно 300 dpi при масштабировании до ожидаемого размера рисунка в окончательном PDF-файле).
Чтобы обрезать файл PPT, откройте раскрывающееся меню «Вид», убедитесь, что выбран параметр «Линейка», и измерьте размеры изображения. Выберите все элементы на слайде и вырежьте эти элементы. Затем в раскрывающемся меню «Файл» выберите «Параметры страницы» и измените размеры слайда, чтобы они соответствовали размерам изображения. Вставьте элементы обратно в слайд.
TIFF — Формат файла изображения тега
Back to top TIFF (Tagged Image File Format)
TIFF — это растровый формат, который подходит для фотографических/отсканированных изображений и т. д. Он поддерживает сжатие без потерь (сжатие LZW), которое особенно хорошо подходит для плоских цветных изображений, таких как штриховые рисунки и скриншоты.
д. Он поддерживает сжатие без потерь (сжатие LZW), которое особенно хорошо подходит для плоских цветных изображений, таких как штриховые рисунки и скриншоты.
Мы рекомендуем сохранять файлы TIFF со сжатием LZW, так как это обеспечивает более высокое разрешение для данного размера файла. Если загружается несжатый файл TIFF, система BMC автоматически сжимает его.По этой причине размер файла TIFF, сообщаемый после загрузки, может быть меньше размера загружаемого несжатого файла.
TIFF и другие растровые изображения можно обрезать с помощью любого пакета для редактирования фотографий или графики, как правило, выбирая интересующую область, а затем выбирая в меню пункт «Обрезать». Обратитесь к документации по программному обеспечению для получения дополнительной информации». Это также должно быть указано в последнем предложении этого раздела и следующих двух разделов (PNG и Bitmap).
JPEG — Объединенная группа экспертов по фотографии
Back to top JPEG (Объединенная группа экспертов по фотографии)
JPEG — это растровый формат с потерями: для сохранения небольшого размера файла некоторая информация в изображении отбрасывается. Чтобы сохранить максимально возможное качество изображения, файлы JPEG следует сохранять с максимальным качеством. См. рисунок ниже для сравнения настроек качества.
Чтобы сохранить максимально возможное качество изображения, файлы JPEG следует сохранять с максимальным качеством. См. рисунок ниже для сравнения настроек качества.
Предоставлено Bates et al., BMC Developmental Biology 2006, 6:33
Изображение JPEG максимального качества
Предоставлено Bates et al., BMC Developmental Biology 2006, 6:33
Изображение JPEG низкого качества повторное сохранение изображений JPEG низкого качества с более высокими настройками качества не рекомендуется, так как это только увеличит размер файла без улучшения качества изображения
JPEG — хороший выбор для фотографий, микрофотографий, радиоавтографов и т. д.поскольку сжатие позволяет отправлять изображения с гораздо более высоким разрешением для данного размера файла с очень небольшим ухудшением качества при условии, что выбран параметр «Максимальное качество».
JPEG — плохой выбор для плоских цветных изображений, штриховых рисунков и скриншотов, поскольку острые края создают видимые артефакты даже при максимальных настройках качества. Такие изображения лучше отправлять в формате TIFF или PNG.
Такие изображения лучше отправлять в формате TIFF или PNG.
Авторы должны свести к минимуму количество сохранений измененной версии изображения в формате JPEG, поскольку при каждом сохранении измененного изображения в формате JPEG происходит некоторое ухудшение качества.По возможности работу следует сохранять в формате JPEG только в конце любого процесса редактирования рисунка.
JPEG и другие растровые изображения можно обрезать с помощью любого пакета для редактирования фотографий или графики, как правило, выбирая интересующую область, а затем выбирая в меню пункт «Обрезать». Обратитесь к документации вашего программного обеспечения для получения дополнительной информации.
PNG — Портативная сетевая графика
Back to top PNG (Portable Networks Graphics)
PNG — это современный формат растрового изображения, который подходит для фотографических/отсканированных изображений и т. д.Он поддерживает сжатие без потерь, что особенно хорошо работает для плоских цветных изображений, таких как штриховые рисунки и скриншоты. Одним из преимуществ PNG по сравнению с TIFF является то, что изображения PNG могут отображаться в современных веб-браузерах.
Одним из преимуществ PNG по сравнению с TIFF является то, что изображения PNG могут отображаться в современных веб-браузерах.
Изображения в формате PNG можно обрезать с помощью большинства пакетов для редактирования фотографий или графики, обычно выбирая интересующую область, а затем выбирая в меню пункт «Обрезать». Обратитесь к документации вашего программного обеспечения для получения дополнительной информации.
BMP — растровое изображение
Back to top BMP (Bitmap)
BMP — это растровый формат Microsoft, который подходит для фотографических/отсканированных изображений и т. д., но менее стандартен и менее компактен, чем TIFF, PNG или JPEG, и поэтому не является предпочтительным форматом, хотя и поддерживается.
Изображения BMP можно обрезать с помощью большинства пакетов для редактирования фотографий или графики, как правило, выбирая интересующую область, а затем выбирая в меню пункт «Обрезать». Обратитесь к документации вашего программного обеспечения для получения дополнительной информации.
CDX-ChemDraw
Back to top CDX (ChemDraw)
CDX — это формат файла для сохранения схем химических реакций, подготовленных с помощью ChemDraw. Предлагаемые настройки ChemDraw:
- Угол цепи 120°
- Расстояние между связями 18%
- Фиксированная длина 0.406 см (11,5 pt)
- Ширина полужирного шрифта 0,056 см (1,6 pt)
- Ширина строки 0,018 см (0,5 pt)
- Ширина поля 0,046 см (1,3 pt)
- Решетка 0,071 см (2 pt)
TGF — ISIS или Draw
Back to topTGF — это формат файла для сохранения схем химических реакций, подготовленных с помощью ISIS/Draw.
.
