Jpeg расшифровка – Object not found!
Декодирование JPEG для чайников / Habr
UPD. Был вынужден убрать моноширинное форматирование. В один прекрасный день хабрапарсер перестал воспринимать форматирование внутри тегов pre и code. Весь текст превратился в кашу. Администрация хабра не смогла мне помочь. Теперь неровно, но хотя бы читабельно.[FF D8]
Вам когда-нибудь хотелось узнать как устроен jpg-файл? Сейчас разберемся! Прогревайте ваш любимый компилятор и hex-редактор, будем декодировать это: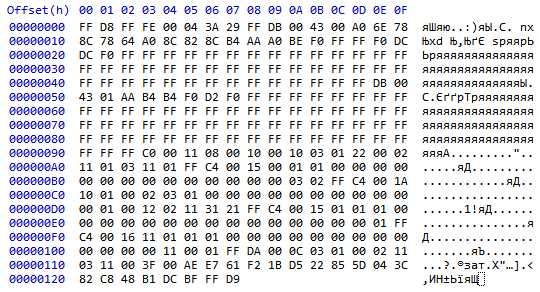
Специально взял рисунок поменьше. Это знакомый, но сильно пережатый favicon Гугла:
Сразу предупреждаю, что описание упрощено, и приведенная информация не полная, но зато потом будет легко понять спецификацию.
Даже не зная, как происходит кодирование, мы уже можем кое-что извлечь из файла.
[FF D8] — маркер начала. Он всегда находится в начале всех jpg-файлов.
Следом идут байты [FF FE]. Это маркер, означающий начало секции с комментарием. Следующие 2 байта
Немного теории
Очень кратко по шагам:
- Обычно изображение преобразуется из цветового пространства RGB в YCbCr.
- Часто каналы Cb и Cr прореживают, то есть блоку пикселей присваивается усредненное значение. Например, после прореживания в 2 раза по вертикали и горизонтали, пиксели будут иметь такое соответствие:
- Затем значения каналов разбиваются на блоки 8×8 (все видели эти квадратики на слишком сжатом изображении).
- Каждый блок подвергается дискретно-косинусному-преобразованию (ДКП), являющемся разновидностью дискретного преобразования Фурье. Получим матрицу коэффициетов 8×8. Причем левый верхний коэффициент называется DC-коффициентом (он самый важный и является усредненным значением всех значений), а оставшиеся 63 — AC-коэффициентами.
- Получившиеся коэффициенты квантуются, т.е. каждый умножается на коэффициент матрицы квантования (каждый кодировщик обычно использует свою матрицу квантования).
- Затем они кодируются кодами Хаффмана.
Напоминаю, что каждый блок Yij, Cbij, Crij — это матрица коэффициентов ДКП, закодированная кодами Хаффмана. В файле они располагаются в таком порядке: Y00Y10Y01Y11Cb00Cr00Y20
Чтение файла
После того, как мы извлекли комментарий, будет легко понять, что:
- Файл поделен на секторы, предваряемые маркерами.
- Маркеры имеют длину 2 байта, причем первый байт [FF].
- Почти все секторы хранят свою длину в следующих 2 байта после маркера.
FF D8 FF FE 00 04 3A 29 FF DB 00 43 00 A0 6E 78
8C 78 64 A0 8C 82 8C B4 AA A0 BE F0 FF FF F0 DC
DC F0 FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF DB 00
43 01 AA B4 B4 F0 D2 F0 FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF C0 00 11 08 00 10 00 10 03 01 22 00 02
11 01 03 11 01 FF C4 00 15 00 01 01 00 00 00 00
00 00 00 00 00 00 00 00 00 00 03 02 FF C4 00 1A
10 01 00 02 03 01 00 00 00 00 00 00 00 00 00 00
00 01 00 12 02 11 31 21 FF C4 00 15 01 01 01 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 01 FF
C4 00 16 11 01 01 01 00 00 00 00 00 00 00 00 00
00 00 00 00 11 00 01 FF DA 00 0C 03 01 00 02 11
03 11 00 3F 00 AE E7 61 F2 1B D5 22 85 5D 04 3C
82 C8 48 B1 DC BF FF D9
Маркер [FF DB]: DQT — таблица квантования.
FF DB 00 43 00 A0 6E 78
8C 78 64 A0 8C 82 8C B4 AA A0 BE F0 FF FF F0 DC
DC F0 FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF
Заголовок секции всегда занимает 3 байта. В нашем случае это [00 43 00]. Заголовок состоит из:
[00 43] Длина: 0x43 = 67 байт
[0_] Длина значений в таблице: 0 (0 — 1 байт, 1 — 2 байта)
[_0] Идентификатор таблицы: 0
Оставшимися 64-мя байтами нужно заполнить таблицу 8×8.
[A0 6E 64 A0 F0 FF FF FF]
[78 78 8C BE FF FF FF FF]
[8C 82 A0 F0 FF FF FF FF]
[8C AA DC FF FF FF FF FF]
[B4 DC FF FF FF FF FF FF]
[F0 FF FF FF FF FF FF FF]
[FF FF FF FF FF FF FF FF]
[FF FF FF FF FF FF FF FF]
Приглядитесь, в каком порядке заполнены значения таблицы. Этот порядок называется zigzag order:
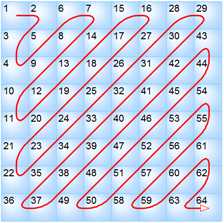
Маркер [FF C0]: SOF0 — Baseline DCT
Этот маркер называется SOF0, и означает, что изображение закодировано базовым методом. Он очень распространен. Но в интернете не менее популярен знакомый вам progressive-метод, когда сначала загружается изображение с низким разрешением, а потом и нормальная картинка. Это позволяет понять что там изображено, не дожидаясь полной загрузки. Спецификация определяет еще несколько, как мне кажется, не очень распространенных методов.
FF C0 00 11 08 00 10 00 10 03 01 22 00 02
11 01 03 11 01
[00 11] Длина: 17 байт.
[00 10] Высота рисунка: 0x10 = 16
[00 10] Ширина рисунка: 0x10 = 16
[03] Количество компонентов: 3. Чаще всего это Y, Cb, Cr.
1-й компонент:
[01] Идентификатор: 1
[2_] Горизонтальное прореживание (H1): 2
[_2] Вертикальное прореживание (V1): 2
[00] Идентификатор таблицы квантования: 0
2-й компонент:
[02] Идентификатор: 2
[1_] Горизонтальное прореживание (H2): 1
[_1] Вертикальное прореживание (V2): 1
3-й компонент:
[03] Идентификатор: 3
[1_] Горизонтальное прореживание (H3): 1
[_1] Вертикальное прореживание (V3): 1
[01] Идентификатор таблицы квантования: 1
Теперь посмотрите, как определить насколько прорежено изображение. Находим Hmax=2 и Vmax=2. Канал i будет прорежен в Hmax/Hi раз по горизонтали и Vmax/Vi раз по вертикали.
Маркер [FF C4]: DHT (таблица Хаффмана)
Эта секция хранит коды и значения полученные кодированием Хаффмана.
FF C4 00 15 00 01 01 00 00 00 00
00 00 00 00 00 00 00 00 00 00 03 02
[00 15] длина: 21 байт.
[0_] класс: 0 (0 — таблица DC коэффициэнтов, 1 — таблица AC коэффициэнтов).
[_0] идентификатор таблицы: 0
Длина кода Хаффмана: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Количество кодов: [01 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00]
Количество кодов означает количество кодов такой длины. Обратите внимание, что секция хранит только длины кодов, а не сами коды. Мы должны найти коды сами. Итак, у нас есть один код длины 1 и один — длины 2. Итого 2 кода, больше кодов в этой таблице нет.
С каждым кодом сопоставлено значение, в файле они перечислены следом. Значения однобайтовые, поэтому читаем 2 байта.
[03]
[02] — значение 2-го кода.
Далее в файле можно видеть еще 3 маркера [FF C4], я пропущу разбор соответствующих секций, он аналогичен вышеприведенному.
Построение дерева кодов Хаффмана
Мы должны построить бинарное дерево по таблице, которую мы получили в секции DHT. А уже по этому дереву мы узнаем каждый код. Значения добавляем в том порядке, в каком указаны в таблице. Алгоритм прост: в каком бы узле мы ни находились, всегда пытаемся добавить значение в левую ветвь. А если она занята, то в правую. А если и там нет места, то возвращаемся на уровень выше, и пробуем оттуда. Остановиться нужно на уровне равном длине кода. Левым ветвям соответствует значение 0, правым — 1.
Замечание:
Не нужно каждый раз начинать с вершины. Добавили значение — вернитесь на уровень выше. Правая ветвь существует? Если да, идите опять вверх. Если нет — создайте правую ветвь и перейдите туда. Затем, с этого места, начинайте поиск для добавления следующего значения.
Деревья для всех таблиц этого примера:
UPD (спасибо anarsoul): В узлах первого дерева (DC, id =0) должны быть значения 0x03 и 0x02
В кружках — значения кодов, под кружками — сами коды (поясню, что мы получили их, пройдя путь от вершины до каждого узла). Именно такими кодами (этой и других таблиц) закодировано само содержимое рисунка.
Маркер [FF DA]: SOS (Start of Scan)
Байт [DA] в маркере означает — «ДА! Наконец-то то мы перешли непосредственно к разбору секции закодированного изображения!». Однако секция символично называется SOS.
03 11 00 3F 00
[00 0C] Длина заголовочной части (а не всей секции): 12 байт.
[03] Количество компонентов сканирования. У нас 3, по одному на Y, Cb, Cr.
1-й компонент:
[01] Номер компонента изображения: 1 (Y)
[0_] Идентификатор таблицы Хаффмана для DC коэффициэнтов: 0
[_0] Идентификатор таблицы Хаффмана для AC коэффициэнтов: 0
2-й компонент:
[02] Номер компонента изображения: 2 (Cb)
[1_] Идентификатор таблицы Хаффмана для DC коэффициэнтов: 1
[_1] Идентификатор таблицы Хаффмана для AC коэффициэнтов: 1
3-й компонент:
[03] Номер компонента изображения: 3 (Cr)
[1_] Идентификатор таблицы Хаффмана для DC коэффициэнтов: 1
[_1] Идентификатор таблицы Хаффмана для AC коэффициэнтов: 1
Данные компоненты циклически чередуются.
[00], [3F], [00] Об этих байтах можно почитать в спецификации.
На этом заголовочная часть заканчивается, отсюда и до конца (маркера [FF D9]) закодированные данные.
[AE] [E7] [61] [F2] [1B]
101011101110011101100001111100100
Нахождение DC-коэффициента.
1. Читаем последовательность битов (если встретим 2 байта [FF 00], то это не маркер, а просто байт [FF]). После каждого бита сдвигаемся по дереву Хаффмана (с соответствующим идентификатором) по ветви 0 или 1, в зависимости от прочитанного бита. Останавливаемся, если оказались в конечном узле.
101011101110011101100001111100100
2. Берем значение узла. Если оно равно 0, то коэффициент равен 0, записываем в таблицу и переходим к чтению других коэффициентов. В нашем случае — 02. Это значение — длина коэффициента в битах. Т. е. читаем следующие 2 бита, это и будет коэффициент.
101011101110011101100001111100100
3. Если первая цифра значения в двоичном представлении — 1, то оставляем как есть: DC_coef = значение. Иначе преобразуем: DC_coef = значение-2длина значения+1. Записываем коэффициент в таблицу в начало зигзага — левый верхний угол.
Нахождение AC-коэффициентов.
1. Аналогичен п. 1, нахождения DC коэффициента. Продолжаем читать последовательность:
101011101110011101100001111100100
2. Берем значение узла. Если оно равно 0, это означает, что оставшиеся значения матрицы нужно заполнить нулями. Дальше закодирована уже следующая матрица. Первые несколько дочитавших до этого места и написавших об этом мне в личку, получат плюс в карму. В нашем случае значение узла: 0x31.
Первый полубайт: 0x3 — именно столько нулей мы должны добавить в матрицу. Это 3 нулевых коэффициэнта.
Второй полубайт: 0x1 — длина коэффициэнта в битах. Читаем следующий бит.
101011101110011101100001111100100
3. Аналогичен п. 3 нахождения DC-коэффициента.
Как вы уже поняли, читать AC-коэффициенты нужно пока не наткнемся на нулевое значение кода, либо пока не заполнится матрица.
В нашем случае мы получим:
101011101110011101100001111100100
и матрицу:
[2 0 3 0 0 0 0 0]
[0 1 2 0 0 0 0 0]
[0 -1 -1 0 0 0 0 0]
[1 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
Вы заметили, что значения заполнены в том же зигзагообразном порядке?
Причина использования такого порядка простая — так как чем больше значения v и u, тем меньшей значимостью обладает коэффициент Svu в дискретно-косинусном преобразовании. Поэтому, при высоких степенях сжатия малозначащие коэффициенты обнуляют, тем самым уменьшая размер файла.
Аналогично получаем еще 3 матрицы Y-канала…
[-4 1 1 1 0 0 0 0] [ 5 -1 1 0 0 0 0 0]
[ 0 0 1 0 0 0 0 0] [-1 -2 -1 0 0 0 0 0]
[ 0 -1 0 0 0 0 0 0] [ 0 -1 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [-1 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[-4 2 2 1 0 0 0 0]
[-1 0 -1 0 0 0 0 0]
[-1 -1 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
Ой, я забыл сказать, что закодированные DC-коэффициенты — это не сами DC-коэффициенты, а их разности между коэффициентами предыдущей таблицы (того же канала)! Нужно поправить матрицы:
DC для 2-ой: 2 + (-4) = -2
DC для 3-ой: -2 + 5 = 3
DC для 4-ой: 3 + (-4) = -1
[-2 1 1 1 0 0 0 0] [ 3 -1 1 0 0 0 0 0] [-1 2 2 1 0 0 0 0]
………
Теперь порядок. Это правило действует до конца файла.
… и по матрице для Cb и Cr:
[-1 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0]
[ 1 1 0 0 0 0 0 0] [1 -1 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [1 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0]
Так как тут только по одной матрице, DC-коэфициенты можно не трогать.
Вычисления
Квантование
Вы помните, что матрица проходит этап квантования? Элементы матрицы нужно почленно перемножить с элементами матрицы квантования. Осталось выбрать нужную. Сначала мы просканировали первый компонент, его компонента изображения = 1. Компонент изображения с таким идентификатором использует матрицу квантования 0 (у нас она первая из двух). Итак, после перемножения:
[320 0 300 0 0 0 0 0]
[ 0 120 280 0 0 0 0 0]
[ 0 -130 -160 0 0 0 0 0]
[140 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
Аналогично получаем еще 3 матрицы Y-канала…
[-320 110 100 160 0 0 0 0] [ 480 -110 100 0 0 0 0 0]
[ 0 0 140 0 0 0 0 0] [-120 -240 -140 0 0 0 0 0]
[ 0 -130 0 0 0 0 0 0] [ 0 -130 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [-140 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[-160 220 200 160 0 0 0 0]
[-120 0 -140 0 0 0 0 0]
[-140 -130 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
… и по матрице для Cb и Cr.
[-170 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 180 210 0 0 0 0 0 0] [180 -210 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [240 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
Обратное дискретно-косинусное преобразование
Формула не должна доставить сложностей*. Svu — наша полученная матрица коэффициентов. u — столбец, v — строка. syx — непосредственно значения каналов.
*Вообще говоря, это не совсем правда. Когда я смог декодировать и отобразить на экране рисунок 16×16, я взял изображение размером 600×600 (кстати, это была обложка любимого альбома Mind.In.A.Box — Lost Alone). Получилось не сразу — всплыли различные баги. Вскоре я мог любоваться корректно загруженной картинкой. Только очень огорчала скорость загрузки. До сих пор помню, она занимала 7 секунд. Но это и неудивительно, если бездумно пользоваться приведенной формулой, то для вычисления одного канала одного пикселя потребуется нахождения 128 косинусов, 768 умножений, и сколько-то там сложений. Только вдумайтесь — почти тысяча непростых операций только на один канал одного пиксела! К счастью, тут есть простор для отимизации (после долгих экспериментов уменьшил время загрузки до предела точности таймера 15мс, и после этого сменил изображение на фотографию в 25 раз большей площадью. Возможно, напишу об этом отдельной статьей).
Напишу результат вычисления только первой матрицы канала Y (значения округлены):
[138 92 27 -17 -17 28 93 139]
[136 82 5 -51 -55 -8 61 111]
[143 80 -9 -77 -89 -41 32 86]
[157 95 6 -62 -76 -33 36 86]
[147 103 37 -12 -21 11 62 100]
[ 87 72 50 36 37 55 79 95]
[-10 5 31 56 71 73 68 62]
[-87 -50 6 56 79 72 48 29]
и 2-х оставшихся:
Cb Cr
[ 60 52 38 20 0 -18 -32 -40] [ 19 27 41 60 80 99 113 120]
[ 48 41 29 13 -3 -19 -31 -37] [ 0 6 18 34 51 66 78 85]
[ 25 20 12 2 -9 -19 -27 -32] [-27 -22 -14 -4 7 17 25 30]
[ -4 -6 -9 -13 -17 -20 -23 -25] [-43 -41 -38 -34 -30 -27 -24 -22]
[ -37 -35 -33 -29 -25 -21 -18 -17] [-35 -36 -39 -43 -47 -51 -53 -55]
[ -67 -63 -55 -44 -33 -22 -14 -10] [ -5 -9 -17 -28 -39 -50 -58 -62]
[ -90 -84 -71 -56 -39 -23 -11 -4] [ 32 26 14 -1 -18 -34 -46 -53]
[-102 -95 -81 -62 -42 -23 -9 -1] [ 58 50 36 18 -2 -20 -34 -42]
А теперь… мини-тест!
Что делать дальше?
- О, пойду-ка поем!
- Да я вообще не въезжаю, о чем речь.
- Раз значение цветов YCbCr получены, осталось преобразовать в RGB, типа так: YCbCrToRGB(Yij, Cbij, Crij), Yij, Cbij, Crij — наши полученные матрицы.
- 4 матрицы Y, и по одной Cb и Cr, так как мы прореживали каналы и 4 пикселям Y соответствует по одному Cb и Cr. Поэтому вычислять так: YCbCrToRGB(Yij, Cb[i/2][j/2], Cr[i/2][j/2])
YCbCr в RGB
R = Y + 1.402 * Cr
G = Y — 0.34414 * Cb — 0.71414 * Cr
B = Y + 1.772 * Cb
Не забудьте прибавить по 128. Если значения выйдут за пределы интервала [0, 255], то присвоить граничные значения. Формула простая, но тоже отжирает долю процессорного времени.
Вот полученные таблицы для каналов R, G, B для левого верхнего квадрата 8×8 нашего примера:
255 248 194 148 169 215 255 255
255 238 172 115 130 178 255 255
255 208 127 59 64 112 208 255
255 223 143 74 77 120 211 255
237 192 133 83 85 118 184 222
177 161 146 132 145 162 201 217
56 73 101 126 144 147 147 141
0 17 76 126 153 146 127 108
231 185 117 72 67 113 171 217
229 175 95 39 28 76 139 189
254 192 100 31 15 63 131 185
255 207 115 46 28 71 134 185
255 241 175 125 112 145 193 230
226 210 187 173 172 189 209 225
149 166 191 216 229 232 225 220
72 110 166 216 238 231 206 186
255 255 249 203 178 224 255 255
255 255 226 170 140 187 224 255
255 255 192 123 91 138 184 238
255 255 208 139 103 146 188 239
255 255 202 152 128 161 194 232
255 244 215 200 188 205 210 227
108 125 148 172 182 184 172 167
31 69 122 172 191 183 153 134
Конец
Вообще я не специалист по JPEG, поэтому вряд ли смогу ответить на все вопросы. Просто когда я писал свой декодер, мне часто приходилось сталкиваться с различными непонятными проблемами. И когда изображение выводилось некорректно, я не знал где допустил ошибку. Может неправильно проинтерпретировал биты, а может неправильно использовал ДКП. Очень не хватало пошагового примера, поэтому, надеюсь, эта статья поможет при написании декодера. Думаю, она покрывает описание базового метода, но все-равно нельзя обойтись только ей. Предлагаю вам ссылки, которые помогли мне:
ru.wikipedia.org/JPEG — для поверхностного ознакомления.
en.wikipedia.org/JPEG — гораздо более толковая статья о процессах кодирования/декодирования.
JPEG Standard (JPEG ISO/IEC 10918-1 ITU-T Recommendation T.81) — не обойтись без 186-страничной спецификации. Но нет повода для паники — три четверти занимают блок-схемы и приложения.
impulseadventure.com/photo — Хорошие подробные статьи. По примерам я разобрался как строить деревья Хаффмана и использовать их при чтении соответствующей секции.
JPEGsnoop — На том же сайте есть отличная утилита, которая вытаскивает всю информацию jpeg-файла.
[FF D9]
habr.com
JPEG — Википедия
JPEG (произносится «джейпег»[1], англ. Joint Photographic Experts Group, по названию организации-разработчика) — один из популярных графических форматов, применяемый для хранения фотоизображений и подобных им изображений. Файлы, содержащие данные JPEG, обычно имеют расширения (суффиксы) .jpg, .jfif, .jpe или .jpeg. Однако из них .jpg является самым популярным на всех платформах. MIME-типом является image/jpeg. Фотография заката в формате JPEG с уменьшением степени сжатия слева направо
Фотография заката в формате JPEG с уменьшением степени сжатия слева направоАлгоритм JPEG позволяет сжимать изображение как с потерями, так и без потерь (режим сжатия lossless JPEG). Поддерживаются изображения с линейным размером не более 65535 × 65535 пикселей.
Область применения[править]
Алгоритм JPEG в наибольшей степени пригоден для сжатия фотографий и картин, содержащих реалистичные сцены с плавными переходами яркости и цвета. Наибольшее распространение JPEG получил в цифровой фотографии и для хранения и передачи изображений с использованием сети Интернет.
Формат JPEG в режиме сжатия с потерями малопригоден для сжатия чертежей, текстовой и знаковой графики, где резкий контраст между соседними пикселями приводит к появлению заметных артефактов. Такие изображения целесообразно сохранять в форматах без потерь, таких как JPEG-LS, TIFF, GIF, PNG или использовать режим сжатия Lossless JPEG.
JPEG (как и другие форматы сжатия с потерями) не подходит для сжатия изображений при многоэтапной обработке, так как искажения в изображения будут вноситься каждый раз при сохранении промежуточных результатов обработки.
JPEG не должен использоваться и в тех случаях, когда недопустимы даже минимальные потери, например, при сжатии астрономических или медицинских изображений. В таких случаях может быть рекомендован предусмотренный стандартом JPEG режим сжатия Lossless JPEG (который, однако, не поддерживается большинством популярных кодеков) или стандарт сжатия JPEG-LS.
При сжатии изображение преобразуется из цветового пространства RGB в YCbCr. Следует отметить, что стандарт JPEG (ISO/IEC 10918-1) никак не регламентирует выбор именно YCbCr, допуская и другие виды преобразования (например, с числом компонентов[2], отличным от трёх), и сжатие без преобразования (непосредственно в RGB), однако спецификация JFIF (JPEG File Interchange Format, предложенная в 1991 году специалистами компании C-Cube Microsystems, и ставшая в настоящее время стандартом де-факто) предполагает использование преобразования RGB->YCbCr.
После преобразования RGB->YCbCr для каналов изображения Cb и Cr, отвечающих за цвет, может выполняться «прореживание» (subsampling[3]), которое заключается в том, что каждому блоку из 4 пикселов (2х2) яркостного канала Y ставятся в соответствие усреднённые значения Cb и Cr (схема прореживания «4:2:0»[4]). При этом для каждого блока 2х2 вместо 12 значений (4 Y, 4 Cb и 4 Cr) используется всего 6 (4 Y и по одному усреднённому Cb и Cr). Если к качеству восстановленного после сжатия изображения предъявляются повышенные требования, прореживание может выполняться лишь в каком-то одном направлении — по вертикали (схема «4:4:0») или по горизонтали («4:2:2»), или не выполняться вовсе («4:4:4»).
Стандарт допускает также прореживание с усреднением Cb и Cr не для блока 2х2, а для четырёх расположенных последовательно (по вертикали или по горизонтали) пикселов, то есть для блоков 1х4, 4х1 (схема «4:1:1»), а также 2х4 и 4х2 (схема «4:1:0»). Допускается также использование различных типов прореживания для Cb и Cr, но на практике такие схемы применяются исключительно редко.
Далее яркостный компонент Y и отвечающие за цвет компоненты Cb и Cr разбиваются на блоки 8х8 пикселов. Каждый такой блок подвергается дискретному косинусному преобразованию (ДКП). Полученные коэффициенты ДКП квантуются (для Y, Cb и Cr в общем случае используются разные матрицы квантования) и пакуются с использованием кодирования серий и кодов Хаффмана. Стандарт JPEG допускает также использование значительно более эффективного арифметического кодирования, однако из-за патентных ограничений (патент на описанный в стандарте JPEG арифметический QM-кодер принадлежит IBM) на практике оно используется редко. В популярную библиотеку libjpeg последних версий включена поддержка арифметического кодирования, но с просмотром сжатых с использованием этого метода изображений могут возникнуть проблемы, поскольку многие программы просмотра не поддерживают их декодирование.
Матрицы, используемые для квантования коэффициентов ДКП, хранятся в заголовочной части JPEG-файла. Обычно они строятся так, что высокочастотные коэффициенты подвергаются более сильному квантованию, чем низкочастотные. Это приводит к огрублению мелких деталей на изображении. Чем выше степень сжатия, тем более сильному квантованию подвергаются все коэффициенты.
При сохранении изображения в JPEG-файле указывается параметр качества, задаваемый в некоторых условных единицах, например, от 1 до 100 или от 1 до 10. Большее число обычно соответствует лучшему качеству (и большему размеру сжатого файла). Однако даже при использовании наивысшего качества (соответствующего матрице квантования, состоящей из одних только единиц) восстановленное изображение не будет в точности совпадать с исходным, что связано как с конечной точностью выполнения ДКП, так и с необходимостью округления значений Y, Cb, Cr и коэффициентов ДКП до ближайшего целого. Режим сжатия Lossless JPEG, не использующий ДКП, обеспечивает точное совпадение восстановленного и исходного изображений, однако его малая эффективность (коэффициент сжатия редко превышает 2) и отсутствие поддержки со стороны разработчиков программного обеспечения не способствовали популярности Lossless JPEG.
Разновидности схем сжатия JPEG[править]
Стандарт JPEG предусматривает два основных способа представления кодируемых данных.
Наиболее распространённым, поддерживаемым большинством доступных кодеков, является последовательное (sequential JPEG) представление данных, предполагающее последовательный обход кодируемого изображения разрядностью 8 бит на компоненту (или 8 бит на пиксель для чёрно-белых полутоновых изображений) поблочно слева направо, сверху вниз. Над каждым кодируемым блоком изображения осуществляются описанные выше операции, а результаты кодирования помещаются в выходной поток в виде единственного «скана», то есть массива кодированных данных, соответствующего последовательно пройденному («просканированному») изображению. Основной или «базовый» (baseline) режим кодирования допускает только такое представление (и хаффменовское кодирование квантованных коэффициентов ДКП). Расширенный (extended) режим наряду с последовательным допускает также прогрессивное (progressive JPEG) представление данных, кодирование изображений разрядностью 12 бит на компоненту/пиксель (сжатие таких изображений спецификацией JFIF не поддерживается) и арифметическое кодирование квантованных коэффициентов ДКП.
В случае progressive JPEG сжатые данные записываются в выходной поток в виде набора сканов, каждый из которых описывает изображение полностью с всё большей степенью детализации. Это достигается либо путём записи в каждый скан не полного набора коэффициентов ДКП, а лишь какой-то их части: сначала — низкочастотных, в следующих сканах — высокочастотных (метод «spectral selection» то есть спектральных выборок), либо путём последовательного, от скана к скану, уточнения коэффициентов ДКП (метод «successive approximation», то есть последовательных приближений). Такое прогрессивное представление данных оказывается особенно полезным при передаче сжатых изображений с использованием низкоскоростных каналов связи, поскольку позволяет получить представление обо всём изображении уже после передачи незначительной части JPEG-файла.
Обе описанные схемы (и sequential, и progressive JPEG) базируются на ДКП и принципиально не позволяют получить восстановленное изображение абсолютно идентичным исходному. Однако стандарт допускает также сжатие, не использующее ДКП, а построенное на основе линейного предсказателя (lossless, то есть «без потерь», JPEG), гарантирующее полное, бит-в-бит, совпадение исходного и восстановленного изображений. При этом коэффициент сжатия для фотографических изображений редко достигает 2, но гарантированное отсутствие искажений в некоторых случаях оказывается востребованным. Заметно большие степени сжатия могут быть получены при использовании не имеющего, несмотря на сходство в названиях, непосредственного отношения к стандарту JPEG ISO/IEC 10918-1 (ITU T.81 Recommendation) метода сжатия JPEG-LS, описываемого стандартом ISO/IEC 14495-1 (ITU T.87 Recommendation).
Синтаксис и структура[править]
Файл JPEG содержит последовательность маркеров, каждый из которых начинается с байта 0xFF, свидетельствующего о начале маркера, и байта-идентификатора. Некоторые маркеры состоят только из этой пары байтов, другие же содержат дополнительные данные, состоящие из двухбайтового поля с длиной информационной части маркера (включая длину этого поля, но за вычетом двух байтов начала маркера, то есть 0xFF и идентификатора) и собственно данных. Такая структура файла позволяет быстро отыскать маркер с необходимыми данными (например, с длиной строки, числом строк и числом цветовых компонентов сжатого изображения).
| Маркер | Байты | Длина | Назначение | Комментарии |
|---|---|---|---|---|
| SOI | 0xFFD8 | нет | Начало изображения | |
| SOF0 | 0xFFC0 | переменный размер | Начало фрейма (базовый, ДКП) | Показывает, что изображение кодировалось в базовом режиме с использованием ДКП и кода Хаффмана. Маркер содержит число строк и длину строки изображения (двухбайтовые поля со смещением соответственно 5 и 7 относительно начала маркера), количество компонентов (байтовое поле со смещением 9 относительно начала маркера), число бит на компонент — строго 8 (байтовое поле со смещением 4 относительно начала маркера), а также соотношение компонентов (например, 4:2:0). |
| SOF1 | 0xFFC1 | переменный размер | Начало фрейма (расширенный, ДКП, код Хаффмана) | Показывает, что изображение кодировалось в расширенном (extended) режиме с использованием ДКП и кода Хаффмана. Маркер содержит число строк и длину строки изображения, количество компонентов, число бит на компонент (8 или 12), а также соотношение компонентов (например, 4:2:0). |
| SOF2 | 0xFFC2 | переменный размер | Начало фрейма (прогрессивный, ДКП, код Хаффмана) | Показывает, что изображение кодировалось в прогрессивном режиме с использованием ДКП и кода Хаффмана. Маркер содержит число строк и длину строки изображения, количество компонентов, число бит на компонент (8 или 12), а также соотношение компонентов (например, 4:2:0). |
| DHT | 0xFFC4 | переменный размер | Содержит таблицы Хаффмана | Задает одну или более таблиц Хаффмана. |
| DQT | 0xFFDB | переменный размер | Содержит таблицы квантования | Задает одну или более таблиц квантования. |
| DRI | 0xFFDD | 4 байта | Указывает длину рестарт-интервала | Задает интервал между маркерами RST n в макроблоках. При отсутствии DRI появление в потоке кодированных данных маркеров RSTn недопустимо и считается ошибкой. Если при кодировании маркеры RST n не применяются, маркер DRI либо не используется вовсе, либо интервал повторений в нём указывается равным 0. |
| SOS | 0xFFDA | переменный размер | Начало сканирования | Начало первого или очередного скана изображения с направлением обхода слева направо сверху вниз. Если использовался базовый режим кодирования, используется один скан. При использовании прогрессивных режимов используется несколько сканов. Маркер SOS является разделяющим между информативной (заголовком) и закодированной (собственно сжатыми данными) частями изображения. |
| RSTn | 0xFFDn | нет | Перезапуск | Маркеры перезапуска используются для сегментирования кодированных энтропийным кодером данных. В каждом сегменте данные декодируются независимо, что позволяет распараллелить процедуру декодирования. При повреждении кодированных данных в процессе передачи или хранения JPEG-файла использование маркеров перезапуска позволяет ограничить потери (макроблоки из неповреждённых сегментов будут восстановлены правильно). Вставляется в каждом r-м макроблоке, где r — интервал перезапуска DRI маркера. Не используется при отсутствии DRI маркера. n, младшие 3 бита маркера кода, циклы от 0 до 7. |
| APPn | 0xFFEn | переменный размер | Задаётся приложением | Например, в EXIF JPEG-файла используется маркер APP1 для хранения метаданных, расположенных в структуре, основанной на TIFF. |
| COM | 0xFFFE | переменный размер | Комментарий | Содержит текст комментария. |
| EOI | 0xFFD9 | нет | Конец закодированной части изображения. |
Достоинства и недостатки[править]
К недостаткам сжатия по стандарту JPEG следует отнести появление на восстановленных изображениях при высоких степенях сжатия характерных артефактов: изображение рассыпается на блоки размером 8×8 пикселей (этот эффект особенно заметен на областях изображения с плавными изменениями яркости), в областях с высокой пространственной частотой (например, на контрастных контурах и границах изображения) возникают артефакты в виде шумовых ореолов. Следует отметить, что стандарт JPEG (ISO/IEC 10918-1, Annex K, п. K.8) предусматривает использование специальных фильтров для подавления блоковых артефактов, но на практике подобные фильтры, несмотря на их высокую эффективность, практически не используются. Однако, несмотря на недостатки, JPEG получил очень широкое распространение из-за достаточно высокой (относительно существовавших во время его появления альтернатив) степени сжатия, поддержке сжатия полноцветных изображений и относительно невысокой вычислительной сложности.
Производительность сжатия по стандарту JPEG[править]
Для ускорения процесса сжатия по стандарту JPEG традиционно используется распараллеливание вычислений, в частности — при вычислении ДКП. Исторически одна из первых попыток ускорить процесс сжатия с использованием такого подхода описана в опубликованной в 1993 г. статье Касперовича и Бабкина [6], в которой предлагалась оригинальная аппроксимация ДКП, делающая возможным эффективное распараллеливание вычислений с использованием 32-разрядных регистров общего назначения процессоров Intel 80386. Появившиеся позже более производительные вычислительные схемы использовали SIMD-расширения набора инструкций процессоров архитектуры x86. Значительно лучших результатов позволяют добиться схемы, использующие вычислительные возможности графических ускорителей (технологии NVIDIA CUDA и AMD FireStream) для организации параллельных вычислений не только ДКП, но и других этапов сжатия JPEG (преобразование цветовых пространств, run-level, статистическое кодирование и т.п.), причём для каждого блока 8х8 кодируемого или декодируемого изображения. В статье [7] была представлена реализация распараллеливания всех стадий алгоритма JPEG по технологии CUDA, что значительно ускорило производительность сжатия и декодирования по стандарту JPEG.
Интересные факты[править]
В 2010 году ученые из проекта PLANETS поместили инструкции по чтению формата JPEG в специальную капсулу, которую поместили в специальный бункер в швейцарских Альпах. Сделано это было с целью сохранения для потомков информации о популярных в начале XXI века цифровых форматах.[8]
wp.wiki-wiki.ru
|
История создания и область применения Что такое JPEG? Началось все в 1986 году, когда под эгидой международной организации по стандартизации (ISO) и международной электротехнической комиссиии (IEC) была создана рабочая группа — ISO/IECJTC1/SC29/WG1, в которую вошли ведущие специалисты в области фотографии со всего мира. Именно тогда мир услышал слово JPEG, которое на самом деле является аббревиатурой от Joint Photographic Experts Group. Теперь рабочая группа ISO/IECJTC1/SC29/WG1 имела куда более благозвучное название — JPEG Сommittee. Основной целью Joint Photographic Experts Group было создание метода сжатия изображений фотографического качества, до размеров, приемлемых для передачи по компьютерным сетям. И уже в августе 1990 года ISO стандартизовал метод сжатия графических изображений с потерями, созданный Joint Photographic Experts Group. Данный метод получил название JPEG (официальное название стандарта ISO/IEC IS 10918-1 | ITU-T Recommendation T.81). Впервые был реализовал новый принцип сжатия с потерями информации. Он основан на удалении из изображения той части информации, которая слабо воспринимается человеческим глазом. Лишенное избыточной информации изображение занимает гораздо меньше места, чем исходное. Степень сжатия, а, следовательно, и количество удаляемой информации, плавно регулируется. Низкие степени сжатия дают лучшее качество изображения, а высокие могут существенно его ухудшить. В дальнейшем, стандарт улучшали и добавляли новые возможности. В частности, было добавлено прогрессивное чередование. Данная версия стандарта получила название p-JPEG (Progressive JPEG). JPEG-LS После того, как был создан алгоритм компрессии JPEG, описанный выше, в комитет стали поступать некоторые критические отзывы о существующем стандарте. Чаше всего высказывались претензии к плохому качеству JPEG изображений, сохраненных без потерь (параметр сжатия равен нулю). Комитет принимает решение пересмотреть стандарт – добавить режим кодирования без потерь. По сути, требовалась интеграция двух видов компрессии: с потерями и без потерь. Традиционно был устроен конкурс алгоритмов сжатия, на котором проводилось численное и визуальное сравнение результатов работы различных программ. Лучшие результаты показал алгоритм LOCO от HP Labs. Он и был выбран в качестве основы для нового стандарта. Так появился новый стандарт JPEG-LS – ISO/IEC IS 14495-1 | ITU-T Recommendation T.87. JPEG2000 JPEG в целом оказался достаточно удачным стандартом. Он обеспечивает высокую эффективность сжатия при приемлемом уровне потерь. Несмотря на огромную популярность стандарта JPEG, по прошествии нескольких лет естественным образом возникла необходимость в появлении нового, усовершенствованного стандарта. Так как были разработаны более эффективные методы сжатия, и приложения требовали от форматов хранения видеоданных все больше и больше функциональности. Стандарт JPEG часто не удовлетворял новым требованиям и должен был быть заменен. Название нового стандарта JPEG2000 изначально указывало на год его ожидаемого выхода, но к 2000 году стандарт так и не был завершен. На сегодняшний день документация на JPEG2000 состоит из 12 частей. Первая ее часть содержит основную информацию – ядро, и имеет официальный статус международного стандарта. Она описывает основные моменты, которые должны быть в обязательном порядке соблюдены в любой реализации стандарта. Вторая часть содержит расширения основной части, которые не являются обязательными. Так как в процессе разработки поступало большое количество различных предложений, было принято решение часть из них внести в базовый вариант стандарта, а часть рассматривать как дополнение. Данный подход выгоден тем, что, во-первых, учитывает большое количество различных предложений и обеспечивает гибкость, а во-вторых, позволяет получать достаточно непритязательные в плане вычислительных ресурсов реализации, совместимые со стандартом. Остальные 10 частей содержат множество дополнительных функций, все эти части можно найти на официальном сайте JPEG2000. Отправной точкой для стандарта JPEG2000 стало предложение М. Болиека 1996 года. Разработанный Болиеком алгоритм участвовал в конкурсе для стандарта сжатия изображений без потерь JPEG-LS, но был отвергнут в пользу более перспективного алгоритма LOCO. Алгоритм Болиека, тем не менее, обладал рядом очень привлекательных возможностей, что послужило причиной создания нового стандарта JPEG2000. Объявление о начале разработки нового стандарта датируется мартом 1997 года. Алгоритм также был отобран путем конкурса нескольких алгоритмов. Программа -победитель (ею стала разработка аризонского университета, алгоритм WTCQ) была выбрана за основу первой версии стандарта. В ноябре 1998 года с подачи Д. Таубмана в стандарт было внесено существенное изменение. Таубман предложил решение, позволившее сделать стандарт существенно более гибким и менее требовательным к ресурсам вычислительной системы. Алгоритм Таубмана (алгоритм EBCOT) в результате составил основу финальной версии стандарта. JPEG форматы — JFIF, SPIFF В августе 1990 года ISO стандартизовал метод сжатия графических изображений с потерями, созданный Joint Photographic Experts Group (он же ISO/IECJTC1/SC29/WG1). Данный метод получил название JPEG. Уже в 1991 году появились первые приложения, использующие этот алгоритм. Впервые был реализовал новый принцип сжатия с потерями информации. Он основан на удалении из изображения той части информации,которая слабо воспринимается человеческим глазом. Лишенное избыточной информации изображение занимает гораздо меньше места, чем исходное. Степень сжатия, а, следовательно, и количество удаляемой информации, плавно регулируется. Низкие степени сжатия дают лучшее качество изображения, а высокие могут существенно его ухудшить. Создав метод компрессии, JPEG комитет не создал формат файлов, использующих этот метод сжатия. Официально, причиной того, что данный формат не был создан, было заявлено следующее: руководитель JPEG комитета понимал, что существует огромное множество всевозможных групп, которые создают свои собственные форматы файлов для множества различных приложений. И каждая из этих групп по своему использовала JPEG компрессию, в соответствии с устройством формата. Поэтому было решено, что невозможно создать формат, который бы полностью удовлетворял всех. Имеется также и неофициальная версия, которая утверждает, что комитет находился под сильным давлением, нужно было выпустить стандарт, так что брать на себя еще одну крупную задачу, такую как создание формата, комитет не мог. Данный метод сжатия давал возможность передавать изображения высокого качества по сети, ввиду их маленького размера. Однако, данные сжатые методом JPEG, нуждались в сопровождении какой-то дополнительной информацией. В результате возникла острая потребность в формате, который был бы переносим для многих операционных систем. Именно такой формат создали Эрик Гамильтон (Eric Hamilton) из C-Cube Microsystems, а также ряд других разработчиков. В октябре 1991 года IJG (Independent JPEG Group) представила этот графический формат файлов, назвав его JFIF (JPEG File Interchange Format), то есть формат для обмена файлами с использованием компрессии JPEG. JFIF устроен очень просто, он содержит небольшое количество заголовков следующих за JPEG данными. Благодаря IJG, в частности Тому Лейну (Tom Lane), формат быстро стал стандартом де-факто для изображений сжатых методом JPEG. Их, так называемый Open Source, способствовал тому, что многие компании включали поддержку формата в свои графические редакторы и веб-браузеры. Однако, пятью годами позже, в 1995, JPEG комитет восполнил данный пробел выпустив стандарт графического формата под названием SPIFF(Still Picture Interchange File Format). SPIFF является официальным, международным стандартом, использующим JPEG компрессию. Он является официальной заменой формата JFIF. Когда Гамильтон стал руководителем WG1 ( JPEG и JBIG комитетов), он стал работать над полным определением формата файлов с компрессией JPEG. Необходимость в новом формате он обосновывал тем, что до сих пор существуют огромные сложные форматы с огромными наборами различных возможностей, в то время как большинству пользователей требовался простой формат для обмена файлами. Обмен сжатыми изображениями входил в задачи проекта ISO под названием JTC 1.29.04 ( JPEG), и, следовательно, замечал Гамильтон, комитет может начать работу над SPIFF без бюрократических проволочек по созданию нового рабочего плана. Почему же понадобился новый формат? Ведь уже существовал JFIF – малых объемов, простой, распространенный, и практически любое ПО для работы с изображениями поддерживало этот формат. Во-первых, SPIFF намного тщательнее проработан, точнее определен, и лучше продуман чем JFIF. SPIFF подвергся более доскональному анализу. Во-вторых, SPIFF более гибкий, чем JFIF. Он содержит набор дополнительных возможностей. Дополнительные опции включают поддержку многих цветовых пространств, и предоставляет определение гамма-изображений. JFIF разрабатывался как минимальный формат, поддерживающий JPEG компрессию, поэтому значение гаммы выставлялось — 1.0. Многие исходные изображения имели другое, технически более высокое, значение гаммы, чаще всего около 0.4 — 0.5. Изменение значений гамма означало, что JFIF изображения часто получались или слишком темными, или слишком светлыми, в зависимости от исходного изображения и системы просмотра. SPIFF же предполагает маркировку файлов их значением гамма. После зритель может откорректировать яркость, если это необходимо для его оборудования. SPIFF часть стандарта JPEG и следовательно очень хорошо определен и протестирован на совместимость. Предполагается, что SPIFF в конечном счете заменит JFIF. SPIFF также полностью поддерживается IJG, следовательно вы можете использовать SPIFF в своих приложениях, оперируя досконально документированной, качественно написанной, свободно распространяемой библиотекой исходного кода, что и делают сотни программ. Спецификация SPIFF не определяет стандартное расширение файлов. IJG рекомендует следующие расширения: «.JPG» и «.JPEG» — для SPIFF фалов, использующих JPEG-компрессию с потерями, и «.SPF» для всех других вариантов SPIFF. Расширение файлов .JPG уже широко используется для формата JFIF (JPEG files). Однако, написанное должным образом, JFIF-совместимое ПО, должно читать SPIFF-JPEG файлы без проблем. Такая совместимость тщательно продумывалась при создании SPIFF формата. Для того, чтобы это было возможным, SPIFF заголовок устроен как набор JPEG APPn маркеров, которые игнорируются старыми декодерами. Предполагается так же и обратная совместимость. То есть SPIFF-JPEG-совместимое ПО должно корректно обрабатывать JFIF файлы. Именно потому, что JFIF и SPIFF-JPEG форматы корректно обрабатываются этими двумя видами ПО, нет необходимости вводить новое расширение для SPIFF файлов, создавая тем самым путаницу. Стоит отметить, что существуют варианты формата SPIFF, использующие отличную от JPEG компрессию. Такие форматы, несовместимы с любым существующим JPEG-совместимым ПО. Для таких файлов, конечно же, необходимы другие расширения. Использование расширений «.JPG» и «.SPF» даст четкое разграничение SPIFF файлов на файлы использующие сжатие с потерями и без потерь. Что, в свою очередь, поможет пользователям точно определить тип компрессии и исключить непреднамеренную порчу данных. На сегодняшний день GIF и JFIF являются самыми популярными графическими форматами в мире компьютерных сетей. Эти форматы не являются взаимозаменяемыми, они служат для разных целей. Например, для оформления сайта (под оформлением я подрозумеваю логотип сайта, кнопочки, стрелочки, черточки и пр.) идеально подходит GIF. Он имеет малый размер, обладает прозрачностью и самое интересное, позволяет создавать анимированые картинки. Но GIF обладает палитрой в 256 цветов, такого каличества вполне достаточно для оформления, а если нам необходимо разсместить на сайте изображение фотографического качества? Для передачи по сети изображений фотографического качества идеально подходят форматы JPEG. Этот формат лучше всего подходит для изображений реальной жизни в сети — отсканированных картинок или цифровых фотографий. |
cs.usu.edu.ru
Формат JPG: особенности, преимущества и недостатки. | Блог о создании лого и дизайне
JPG является одним из наиболее узнаваемых, популярных и понятных растровых форматов изображения. Об отличиях растра и вектора мы говорили в этой статье.
Появился этот формат, как результат работы группы фото экспертов «Joint Photographic Experts Group». Основной задачей этой группы разработчиков было выработать оптимальный алгоритм сжатия изображения. На сегодня эта задача решена успешно.

Фото Cargocollective.com
Вкратце о формате мы уже писали в этой статье «Форматы графических файлов — JPG, PNG, SVG, PDF», теперь разберем плюсы и минусы формата более подробно:
Преимущества и недостатки.
Плюсы:
— высокая и управляемая степень сжатия. Пользователь сам выбирает соотношение качество/размер файла;
— небольшой размер файла;
— узнаваемость всеми браузерами, графическими и текстовыми редакторами, совместимость и правильное отображение на всех компьютерах, планшетах и мобильных устройствах;
— правильная работа с полноцветными реалистичными изображениями, где много цветовых и контрастных переходов;
— при небольшой степени сжатия качество изображения остается достаточно высоким.
Все это обеспечивает колоссальную популярность формата.
Минусы:
— при сильном сжатии изображение может «рассыпаться» на отдельные квадратики – блоки пикселей размером 8х8. Это происходит потому, что алгоритм сжатия предполагает анализ соседних пикселей, вычисление их цвета и усреднение, за счет этого плавные цветовые переходы могут стать ступенчатыми или пропасть вовсе;
— хуже других форматов подходит для работы с текстами или монохромными графическими изображениями с четкими границами;
— не поддерживает прозрачность. В случае отрисовки шаблонов, логотипов, кнопок — это критично;
— восстановленный после сжатия файл править и/или пересохранять не рекомендуют — каждый такой шаг ухудшает качество изображения.
Где используется?
Применяется .jpg чаще всего для обработки и хранения полноцветных картинок с реалистичными изображениями, где неотъемлемо присутствуют переходы яркости и цвета. Также .jpg формат используют для хранения и передачи графического цифрового контента (фотографии, скан-копии, оцифрованные картинки). Он наиболее удобен и при размещении и передаче сжатых изображений по сети, потому что занимает мало места, по сравнению с другими форматами.
Оптимальные форматы для логотипов, рисунков с несколькими приоритетными цветами и четкими границами, визиток и т.п. мы рассмотрим в следующих статьях. А для бытового хранения фотографий, передачи через интернет или при размещении на сайтах идеально подходит .jpg.
Статьи по теме:
www.logaster.ru
Формат JPG
JPG является самым известным и универсальным графическим форматом файлов. В настоящее время формат JPG имеет широкое распространение, пользуется широкой популярностью, а также поддерживается большим количеством программного обеспечения по редактированию и просмотру растровой графики. Данный формат хорошо подходит для небольших фотореалистических полноцветных изображений, полученных с помощью цифровой камеры. В силу своего малого размера при относительно приемлимом качестве цвета файлы формата JPG пригодны для использования в Интернете или пересылки по электронной почте. Аббревиатура JPG (JPEG) расшифровыается как Join Photographic Experts Group (Объединенная группа экспертов-фотографов) — организация разработчик этого формата. Наряду с JPG(JPEG) файлы данного типа имеют расширения .jpeg, .jfif, .JPE. Однако они встречаются значительно реже, чем JPG. Формат файла JPG имеет глубину цвета в 24 бит (16,7 млн цветов), в то время как GIF ограничен 256 цветами. Отличительной чертой JPG от других графических форматов является его алгоритм компрессии данных с потерями, благодаря которому оригинал изображения можно сжать до 2% от исходного размера с достаточно быстрой скоростью. Однако маленький размер файла не означает сохранение качества изображения. При максимальной степени компрессии детали картинки стираются и она превращается в серый блок. При средних уровнях сжатия сохраняется приблизительная информация о цвете соответствующего участка изображения. Чем выше сжатие, тем больше такая приблизительность. В этом заключается отличие JPG от других форматов, которые сохраняют изображение поточечно. Степень сжатия задается условным числом Q, которое изменяется от 1 до 100 (или от 1 до 10). Большее число соответствует лучшему качеству, но приводит к увеличению размера файла. Если необходимо соблюсти баланс между уровнем качества изображения и его размером, то рекомендуется варьировать степень сжатия до получения оптимального результата. Рассмотрим использование параметра Q на примере фотографии размером 215×145. В случае Q=1 появились характерные артефакты, изображение рассыпалось на блоки размерами 8×8 пискелей.Достоинства формата JPG
- хорошая степень сжатия изображения;
- невысокая вычислительная сложность и быстрая скорость алгоритма компрессии;
- широкое распространение;
- поддержка многими приложениями для компьютера и портативных устройств;
- относительно высокая глубина цвета, 24бит (16,7 млн)
Недостатки формата JPG
- потеря качества изображения при сжатии;
- дополнительные потери при пересохранении;
- не поддерживает альфа-канал;
- отсутствие возможности смены кадров при просмотре;
- невозможность восстановления качества оригинала
www.afino.ru
Форматы записи изображения > OzPhoto.ru
Как Вы уже поняли из названия статьи, речь сегодня пойдет о трех, самых распространенных форматов в фотосъемке. Это JPEG, TIFF и RAW.

Начнем пожалуй с JPEG.
Формат JPEG (аббревиатура, в расшифровке звучащая так- «Joint Photographic Expert Group») – это формат оптимизированный для передачи изображений по каналам различным каналам (будь то дискета, диск, флеш или локальная сеть). В связи с этим, основная задача формата- сжимать информацию кадра. Ну а происходит это сжатие за счет качества снимка ( в основном ухудшается цветовая палитра, а яркость и контрастность остаются почти неизменными). Таким образом JPEG- это не графический формат, а алгоритм сжатия графических данных за счет палитры цветов.
Если Вы все же решили снимать в формате JPEG, то в первую очередь Вам нужно определиться со степенью сжатия снимка. Если Вам важна цветопередача, а занимаемый объем памяти снимком, не имеет значения, то лучше установить минимальное сжатие, ну а если поджимает место на карте, а снимок очень нужен, придется смериться с максимальным уровнем сжатия снимка, ну а если, Вы просто экономите место на карте, но качество нужно хорошее, можно настроить на средний уровень сжатия снимка. Как правило эти настройки можно изменить, покопавшись в меню фотокамеры.
«Одним словом»: JPEG плохо справляется с плавностью тоновых переходов и отображением верной цветопередачи, внося цветовые искажения и артефакты, «загрубляя» тоновые переходы на снимке.
Продолжим с TIFF форматом.
Формат TIFF (аббревиатура, в расшифровке звучащая так- «Tagged linage File Format») в компьютерной графике имеет широкий спектр использования. Он позволяет, без потери данных о яркости и цвете, хранить изображения с глубиной резкости до 48 бит. В его основе лежит обратимый алгоритм сжатия без потерь качества снимка.
Но как же без недостатков. В связи с тем, что TIFF несет в себе множество данных о снимке, то уровень сжатия снимка особо не велик.
На 90 %, алгоритм у JPEG’а и TIFF’а один (то есть этапы: «интерполяцию цвета», «повышение резкости» и «цветокоррекция»), отличающийся лишь последним этапом, этапом сжатия снимка. Таким образом, при минимальной степени сжатия, снимок в форматах TIFF и JPEG будут мало различимы (даже для взгляда эксперта).
Ну и наконец-то формат RAW.
Формат RAW (его так же, с перевода на Русский называют «сырой») является родным для цифровых фотоаппаратов. Этот формат представляет собой массив данных, попавших на матрицу фотоаппарата при съемке (оцифрованные данные, полученные с матрицы, c минимальной их обработкой). Параметрами данного массива являются: размер (в px (пикселях)) и глубина оцифровки (или уровень тона; измеряется в битах), которые определяют в свою очередь, информационную емкость фотоснимка. Глубина оцифровки зависти от параметров АЦП фотоаппарата (аналого- цифрового преобразователя), а глубина оцифровки, напрямую зависит от интенсивности света. При изменении экспозиции на 1-ну ступень, вдвое меняет уровень тона каждого пикселя.
16-ти битное кодирование снимков, обеспечивает полноценный охват снимка.
По объему занимаемой памяти, RAW имеет промежуточную между JPEG (он имеет меньший вес) и TIFF форматом (который занимает многим больше места). Данную позицию RAW занимает, благодаря тому, что он кодирует не цветной, а черно-белый вариант фотоснимка.
И на последок.
Все современные цифровые фотоаппараты, позволяют снимать в формате RAW + JPEG. В этом случае, нажав на кнопку спуска, Мы получаем два кадра, в формате RAW и JPEG.Это позволяет нам с легкостью корректировать снимок, сделанный в формате RAW (резкости и контраста снимка, цветовую модель и насыщенность цветов, баланса белого цвета и многое другое), смотрев на то, как это должно выглядеть (подглядывая в JPEG снимок).
ozphoto.ru
JPEG — Изображение в формате JPEG
Расширение JPEG
Чем открыть файл JPEG
В Windows: Microsoft Windows Photo Viewer, Microsoft Paint, Adobe Photoshop CS5, Adobe Photoshop Elements 10, Adobe Illustrator CS5, CorelDRAW Graphics Suite X5, Corel PaintShop Pro X4, ACDSee Photo Manager 14, ACD Systems Canvas 12, Laughingbird The Logo Creator, Roxio Creator 2012, Axel Rietschin FastPictureViewer, Zoner Photo Studio, IrfanView, Adobe Fireworks, PhotoOnWeb, Artweaver, Ability Photopaint, любой другой графический редактор, любой другой вэб-браузер
В Mac OS: Apple Preview, Adobe Photoshop CS5, Adobe Photoshop Elements 10, Adobe Illustrator CS5, ACDSee Pro for Mac, Laughingbird The Logo Creator, Roxio Toast 11, Fireworks for Mac, Adobe Creative Suite for Mac, Flare for Mac, любой другой графический редактор, любой другой вэб-браузер
В Linux: GIMP, Gwenview
Кроссплатформенное ПО: XnView, Paint.NET, Google Picasa, GIMP, Easy-PhotoPrint EX
Описание JPEG
Популярность:
Раздел: Растровая графика
Разработчик: Joint Photographic Experts Group
Термин JPEG на самом деле – это сокращение от «Совместная группа экспертов фотографии» (Joint Photographic Experts Group), потому что это название комитета, который разработал формат. Но Вы не обязаны это помнить, т.к. редко кто об этом знает. Вместо этого, помните, что JPEG представляет собой сжатый формат файла изображения. JPEG изображения не ограничены определенным количеством цветов, как GIF формат. Таким образом, формат JPEG лучше для сжатия фотографий. Так что, если вы увидите большое, красочное изображение в Интернете, то, скорее всего файла в формате JPEG.
JPEG основан на 24-битной цветовой палитре и поддерживает 16,7 млн. цветов. Однако это формат сжатия с потерями, а это значит, что часть информации теряется при сжатии. Степень сжатия может быть в диапазоне от 10:1 до 20:1, и большинство графических прикладных программ (например, Adobe Photoshop) позволяют выбрать степень сжатия.
Формат JPEG файлов лучше всего подходит для цифровой фотографии, где типичная скорость сжатия с очень низким уровнем потери качества составляет около 10:1. Как GIF, JPEG, это кроссплатформенный формат, то есть тот же файл будет выглядеть так же, как на Mac и PC.
Mime тип: image/jpeg, image/jpg, application/jpg, application/x-jpg
fileext.ru