Баланс пример ип: Бухгалтерская отчетность ИП — Контур.Бухгалтерия — СКБ Контур
Бухгалтерская отчетность ИП — Контур.Бухгалтерия — СКБ Контур
Какую отчетность сдает ИП
Предприниматель может не вести бухучет и не сдавать бухгалтерскую отчетность в налоговую. Это обязательная задача организаций, но не предпринимателей (пп. 1 п. 2 ст. 6 ФЗ от 06.12.2011 №402-ФЗ “О бухгалтерском учете”).
При этом бухучет со спецсчетами и проводками можно не вести, только если ИП другим способом ведет учет доходов, расходов и прочих объектов налогообложения (ст. 6 402-ФЗ от 06.12.2011). На основе такого учета он формирует отчеты для налоговой. Так что от сдачи бухгалтерских форм отчетности предприниматель освобожден, но обязательно сдает в ФНС налоговую отчетность. Перечень отчетных деклараций и других документов определяется налоговым режимом, на котором работает ИП:
- на ОСНО это декларация 3-НДФЛ, декларация по НДС с книгой покупок и продаж, обязательно ведется КУДиР, утвержденная приказом Минфина от 13.08.2002 № 86н/БГ-3-04/430;
- на УСН — декларация по УСН, обязательно ведется КУДиР, утвержденная приказом Минфина №135н от 22.

- на патенте — обязательно ведется КУД, утвержденная приказом Минфина №135н от 22.10.2012;
- на ЕСХН — декларация по ЕСХН, обязательно ведется КУДиР, утвержденная приказом Минфина №169н от 11.12.2006 (в ред. от 31.12.2008).

А еще ИП-работодатель сдает отчеты по сотрудникам: РСВ, СЗВ-М, СЗВ-ТД, СЗВ-СТАЖ, 4-ФСС, 6-НДФЛ.
Какие документы заменяют бухотчетность у ИП
Есть случаи, когда предпринимателей просят подготовить промежуточную бухгалтерскую отчетность — для получения кредита или участия в тендере. Бухотчетность запрашивают и контрагенты перед заключением серьезных сделок.
Если ИП не ведет бухучет и не составляет бухотчетность, он может представить для этих целей выписку из КУДиР или КУД и декларацию по налогу за истекший период. А еще приложить к этим документам письмо о том, что предприниматель не составляет бухотчетность в соответствии с правом, которое дает ему 402-ФЗ “О бухгалтерском учете”.
В Контур.Бухгалтерии ИП может распечатать КУДиР и налоговую декларацию за истекший период с отметкой ФНС о приеме.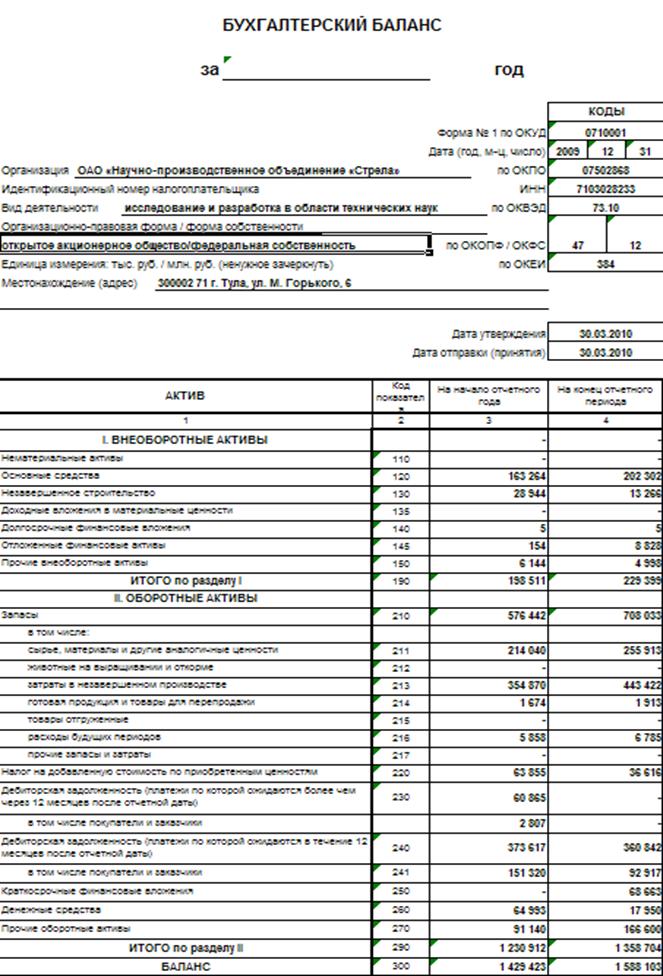
Вот образец сопроводительного письма, которое ИП может вместе с документами предоставить в банк, на тендер или контрагенту:
«Я, ИП Иванов И.И., настоящим письмом уведомляю, что не могу предоставить бухгалтерскую отчетность за указанный период, поскольку не веду бухгалтерский учет. Такая возможность предусмотрена пп.1 п.2 ст.6 Федерального закона “О бухгалтерском учете” №402-ФЗ от 06.12.2011. Взамен предоставляю налоговую отчетность с отметкой ФНС о приеме и/или выписку из Книги учета доходов и расходов».
Какую отчетность сдают ООО и ИП при УСН в 2020 году
Упрощенную систему могут применять предприниматели и организации, которые соответствуют установленным критериям. И те, и другие в большинстве случаев платят только единый налог, а вот учет и отчетность УСН у организаций сложнее. Из этой статьи вы узнаете, какую отчетность сдают упрощенцы.
Она сдается по единой форме независимо от объекта налогообложения: «доходы» или «доходы за минусом расходов», просто для каждого случая в декларации есть свой раздел.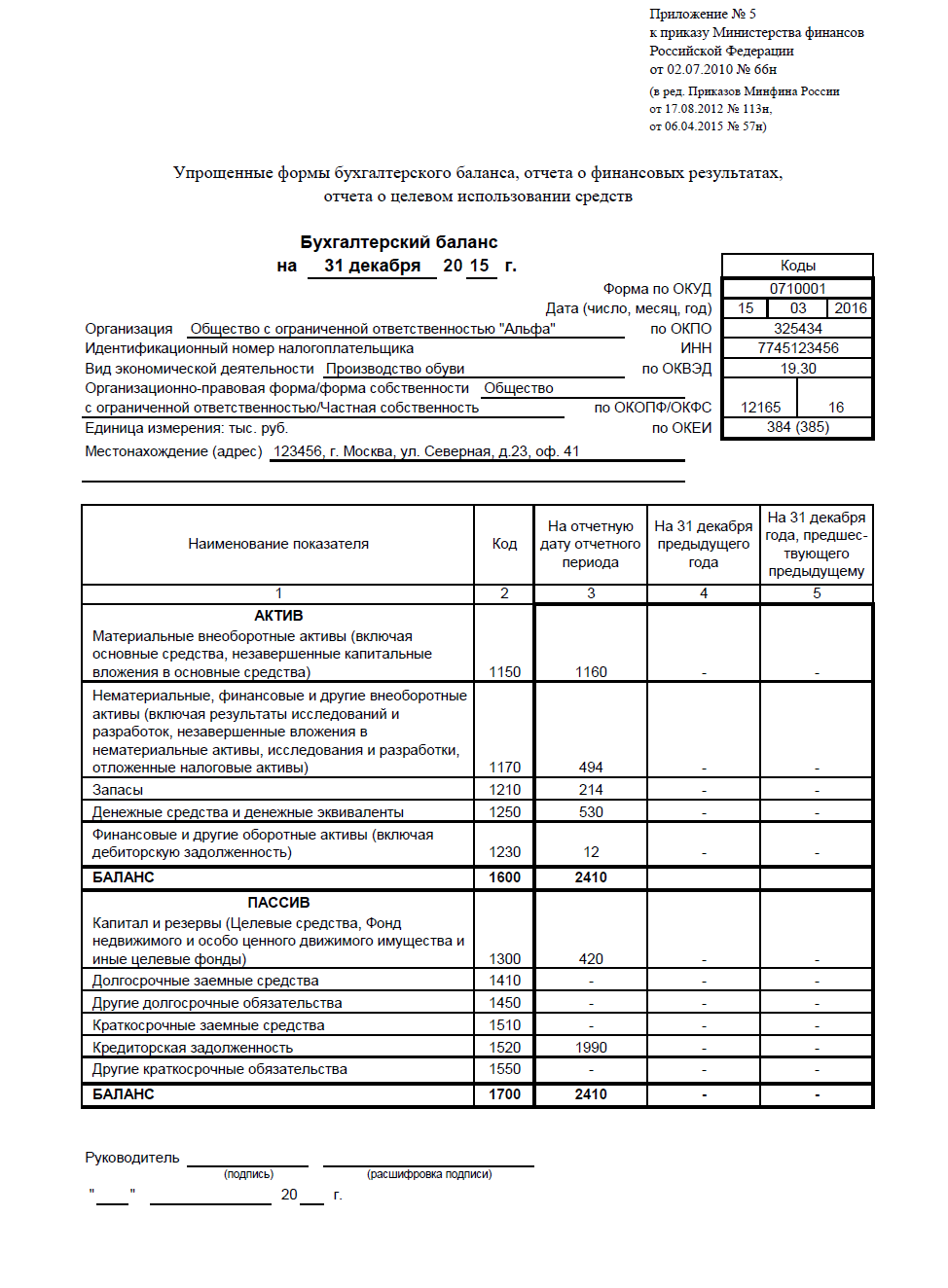 В 2020 году действует форма, утверждённая Приказом ФНС России № ММВ-7-3/99 от 26.02.2016г.
В 2020 году действует форма, утверждённая Приказом ФНС России № ММВ-7-3/99 от 26.02.2016г.
Срок сдачи отчетности УСН для предпринимателей 30 апреля после отчетного года, для организаций – 31 марта.
Заполнять ее можно как в электронном виде, так и в бумажном. Те, у кого в штате меньше 100 сотрудников могут делать как им удобно, а вот если сотрудников больше 100, то вариантов нет – отчет нужно отправить в электронной форме.
В сервисе «Мое дело» декларации формируются с помощью пошагового мастера, который не даст что-то пропустить или ошибиться.
Она тоже обязательна для всех. Информация из КУДиР нужна для заполнения декларации и расчета налогов, а также для налоговых проверок. Актуальную форму можно найти в приложении 1 к Приказу Минфина России от 22.10.2012 № 135н, а порядок заполнения – в приложении 2.
Пользователям сервиса «Мое дело» нет необходимости искать форму и изучать правила заполнения, ведь в системе все формируется автоматически и по действующим правилам.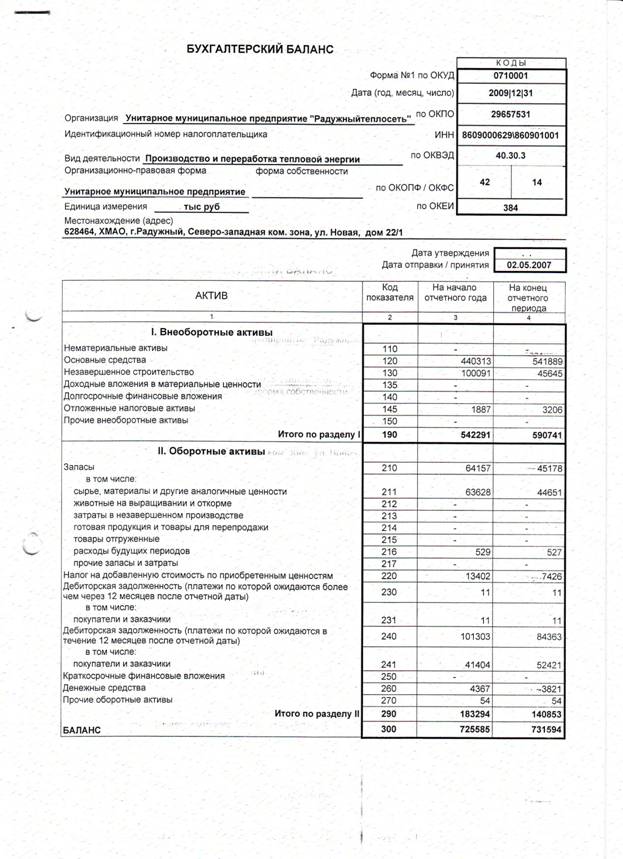
Если вести КУДиР в электронном виде, то после окончания отчетного периода нужно ее распечатать, прошить и подписать. В таком виде она должна храниться, чтобы ее можно было по первому требованию предъявить налоговикам для проверки.
Если деятельность не велась, книгу все равно нужно сформировать с нулевыми показателями и распечатать, ее отсутствие карается штрафом.
А вот этот раздел только для организаций, предприниматели могут его пропустить, потому что освобождены от необходимости вести бухгалтерский учет.
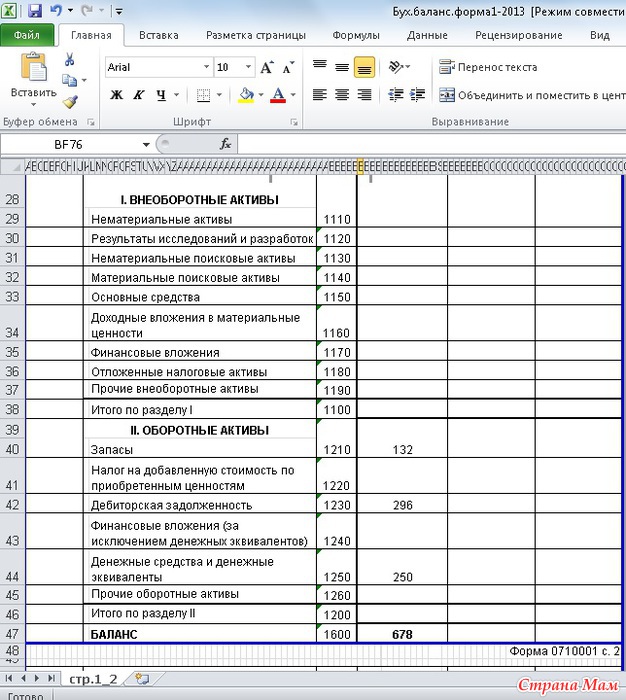
Каждый год до 31 марта ООО на УСН должны сформировать и сдать бухгалтерский баланс.
Упрощенцы в силу ограничений по количеству работников и доходам относятся к малым предприятиям, поэтому имеют право использовать сокращенный план счетов и сдавать не полный набор бухотчетности, а только баланс и отчет о финансовых результатах, причем тоже в упрощенной форме. Это право, а не обязанность, и организации могут выбрать вариант, который им удобен.
Если будет решено воспользоваться привилегиями, нужно закрепить план счетов и форму отчетов в Учетной политике.
Формы упрощенных отчетов можно найти в приложении 5 к Приказу Минфина № 66н от 02.07.2010г.
Все ООО до 31 марта отправляют бухотчетность не только в налоговую инспекцию, но и в Росстат.
Другие формы статистического наблюдения предприятия и ИП сдают в том случае, если попадут в ежегодную выборку Росстата.
Если это произойдет, из органов статистики придет уведомление по почте. Там будет указано, какой именно отчет нужно сдать и когда.
Есть еще один способ узнать это: посмотреть списки на сайте регионального отделения Росстата или сформировать уведомление на сайте http://statreg.gks.ru/.
Последний способ самый удобный – не надо искать списки, а затем себя в списках, нужно просто ввести свои данные и получить информацию.
Статистическую отчетность тоже можно заполнить и сразу отправить в сервисе «Мое дело».
Раздел касается всех организаций и тех индивидуальных предпринимателей, у которых есть наемные сотрудники.
Отчитываться нужно в налоговую инспекцию, Пенсионный Фон и ФСС.
В ИФНС подаются:
— Сведения о среднесписочной численности до 20 января.
— Расчет по страховым взносам до 30 апреля, июля, октября и января.
— 6-НДФЛ до 30 апреля, 31 июля, 31 октября и 1 апреля за год.
— 2-НДФЛ на каждого наемного сотрудника до 1 апреля.
В ПФР:
— Сведения о застрахованных лицах по форме СЗВ-М до 15 числа ежемесячно;
— Информация о стаже по форме СЗВ-стаж и ОДВ-1 до 1 марта по истечении года.
В ФСС отправляется только один отчет 4-ФСС в течение 20 дней после каждого квартала или 25 дней, если отчет сдается в электронной форме.
Задач немало несмотря на то, что режим называется упрощенным. Все перечисленное в статье – головная боль бухгалтеров, если они есть. Но для небольших предприятий, и уж тем более ИП держать в штате бухгалтеров – непосильная нагрузка, а порой и нецелесообразные траты. Хорошему бухгалтеру нужно платить много, а плохой может обойтись еще дороже, если наделает ошибок.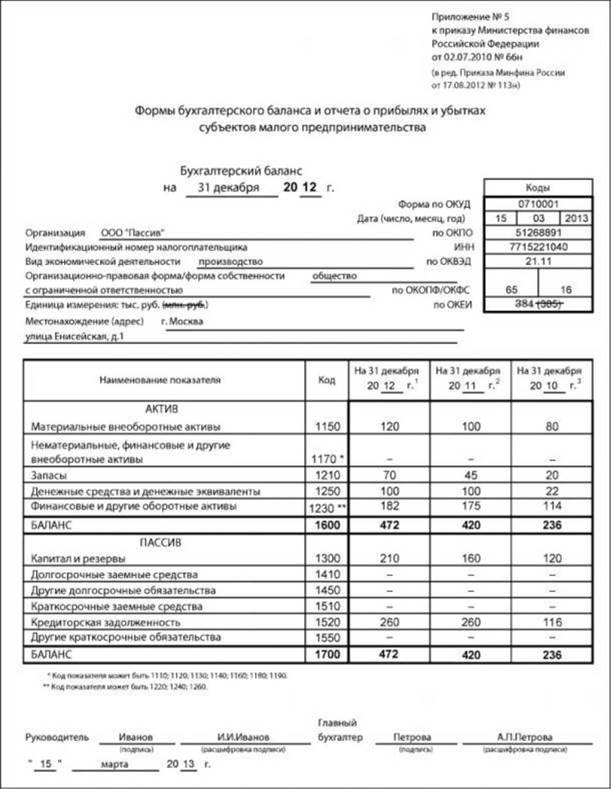
Оптимальный вариант – вести бухгалтерию в сервисе «Мое дело». Даже если есть бухгалтер, его работа «в паре» с интернет-бухгалтерий будет быстрее и эффективнее.
Вы заносите свои данные, а система подставляет их куда следует. Не нужно искать актуальные бланки, правила заполнения отчетов, изучать формулы для расчета налогов и самим подсчитывать что и куда вы должны. Все делается в автоматическом режиме.
Заполненные отчеты можно будет скачать, распечатать, или сразу отправить в нужную инстанцию в электронной форме прямо из личного кабинета. Электронную подпись для своих пользователей мы делаем бесплатно.
Статус отправленного отчета также отслеживается в личном кабинете. Если у налоговой имеются к нему нарекания – вы узнаете об этом вовремя и успеете исправить ситуацию до того, как начнутся штрафы.
Сервис интегрирован с банками, поэтому рассчитанные налоги можно сразу оплатить.
Еще одно преимущество наших клиентов – возможность получать бесплатные консультации экспертов в любое время дня и ночи.
А теперь загляните в раздел «Тарифы» и удивитесь, как мало нужно заплатить за все эти возможности.
А чтобы попробовать, даже и платить не нужно – просто зарегистрируйтесь и воспользуйтесь бесплатной демо-версией.
Узнать подробнее про:
3 важных отчета для бизнеса. Организация и ведение финансового бухгалтерского учета
Финансы в бизнесе — это не пустые цифры в Excel, а данные, на основании которых предприниматель принимает решения. Чтобы понять, успешен ли бизнес, сколько реальной прибыли он приносит, почему появляется кассовый разрыв и как исправить положение в случае убытка, важно разобраться, как правильно вести финансовый учет. В этом помогут три главных отчета. Фактически, финансовый учет и есть совокупность этих отчетов: отчет о движении денежных средств (ДДС), отчет о прибылях и убытках (ПиУ) и отчет по балансу. В этой статье мы разберем, как вести финансовый учет в бизнесе эффективно и с минимальными временными затратами.
В этой статье мы разберем, как вести финансовый учет в бизнесе эффективно и с минимальными временными затратами.
Содержание:
Расскажем, как вести финансовый учет в бизнесе, а также возьмем на себя кадровые и бухгалтерские вопросы. Вы сможете заняться развитием бизнеса, ни о чем не беспокоясь!
1. Отчет о движении денег (ДДС)
Показывает, количество поступивших и ушедших денег на расчетных счетах.
Помогает предсказать кассовый разрыв: критическую точку, когда вам не хватит денег на оплату аренды, покупку товара или выплату зарплаты сотрудникам.
Отчет о движении денежных средств показывает:
-
С какой суммой на счету фирма начала месяц.
-
Сколько получили и потратили в течении месяца.
-
Сколько осталось в конце.

Остаток — это переходящее сальдо.
Важно, чтобы в отчете отражались все счета: расчетные счета в банке, электронные кошельки, наличная касса, сейф, а также фиксировались все расходы по трём направлениям деятельности:
-
операционная: покупка и продажа товаров, зарплаты сотрудников, аренда офиса, лизинг авто;
-
инвестиционная: покупка и продажа оборудования или автомобилей доставки, разработка интернет-магазина;
-
финансовая: кредиты и выплата дивидендов.
Дополнительно можно разбить каждое направление на статьи расходов. Это позволит более детально отслеживать, куда компания тратит деньги.
Не обязательно дробить слишком подробно, можно объединить по категориям. Например, канцелярия, вода, чай и кофе в офис могут быть списаны «на нужды офиса», а топливо, техобслуживание автомобилей и мелкий ремонт — на «транспорт».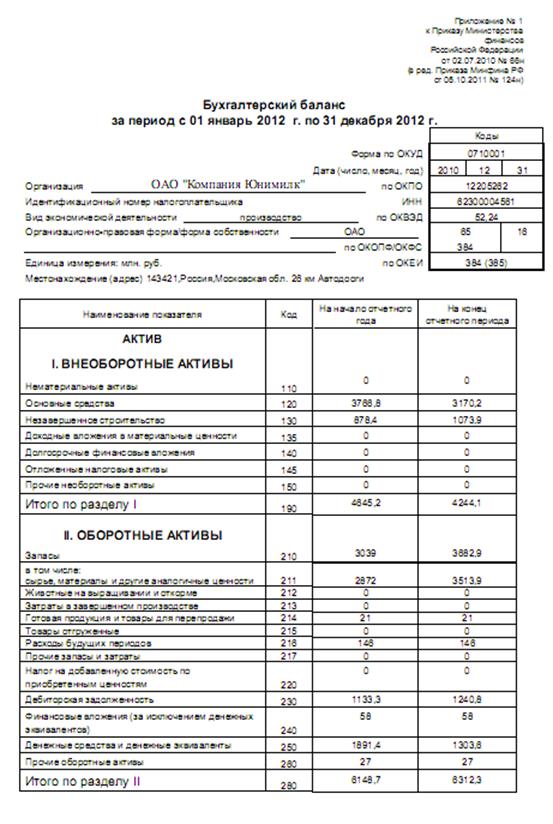
Частоту, с которой необходимо сверять отчет и реальное положение дел, каждый предприниматель определяет для себя сам. Можно делать это в конце каждого рабочего дня, можно раз в неделю или месяц.
2. Отчет о прибылях и убытках предприятия (ПиУ)
Отчет о прибылях и убытках предприятия показывает результат деятельности компании за отчетный период. Он содержит данные о выручке и расходах бизнеса, которые основываются на закрывающих документах. Анализ отчета о прибылях и убытках помогает оценить чистую прибыль: доход – расход. Формула простая, но большинство бизнесменов считает прибыль неправильно.
Рассмотрим пример.
У Егора бизнес по производству крафтовой упаковки — пик продаж приходится на праздники, когда люди массово покупают и упаковывают подарки. Дела идут хорошо, заказов много, деньги на счете есть. Но когда приходит время платить зарплату и закупать новую бумагу для производства, хватает только на оплату аренды. Регулярно приходится брать в долг, покупать материалы в рассрочку. Основные деньги на счетах — кредитные деньги. Егор составил отчет о прибылях и убытках предприятия и понял, что сумма на счету не является прибылью. Он уже полгода работает в минус, нужно менять финмодель или закрывать компанию.
Регулярно приходится брать в долг, покупать материалы в рассрочку. Основные деньги на счетах — кредитные деньги. Егор составил отчет о прибылях и убытках предприятия и понял, что сумма на счету не является прибылью. Он уже полгода работает в минус, нужно менять финмодель или закрывать компанию.
3. Баланс
Анализ балансового отчета помогает оценить чистую стоимость капитала, понять, становится ли бизнес прибыльнее и из чего состоит прибыль. Балансовый отчет состоит из активов и пассивов компании. Активы — все имущество, которое находится в компании и обеспечивает ее работу: техника, мебель, служебный автомобиль, оборудование для производства и даже дебиторская задолженность. Нематериальные активы — ценность бренда, товарный знак, патент. Ценность всех активов в способности генерировать прибыль. Пассивы — это средства, на которые куплены активы: личные средства собственника, накопленная прибыль или кредитные деньги.
Балансовый отчет на конец года может отличаться от других периодов. Например, Антон ведет бизнес по продаже подарков на Пасху и Рождество. Минимальный запас материалов на производство придется на март и ноябрь, так как всю продукцию заберут оптовики и розничные магазины для начала продаж. На балансе предприятия в активах будет минус, а в пиковый сезон подготовки к отгрузке товаров, напротив, большой запас.
Например, Антон ведет бизнес по продаже подарков на Пасху и Рождество. Минимальный запас материалов на производство придется на март и ноябрь, так как всю продукцию заберут оптовики и розничные магазины для начала продаж. На балансе предприятия в активах будет минус, а в пиковый сезон подготовки к отгрузке товаров, напротив, большой запас.
Как вести финансовый учёт просто, затрачивая минимум времени?
Не спешите гуглить, чтобы узнать, как вести финансовый учет в Excel. Для этой цели есть более подходящие сервисы!
Отчет о движении денежных средств и отчет о прибылях и убытках предприятия — столпы управленческого учета. Оба отчета просто и удобно готовить в сервисе Seeneco, чтобы не ломать голову над тем, как вести финансовый учет в Excel.
Отчет о движении денежных средств формируется на основе фактических выплат и поступлений по всем счетам и кассам бизнеса и показывает остатки денег на начало и конец периода, денежные потоки по операционной, финансовой и инвестиционной деятельности.
Отчет о прибылях и убытках предприятия формируется на основе доходов и расходов, показывает прибыль в разрезе денежных потоков: по месяцам, по кварталу и году.
В Seeneco любую ячейку каждого отчета можно раскрыть: увидеть, какие операции составили ее результат, как деньги распределились по контрагентам.
Отчет можно скачать в Excel, чтобы продолжить работу в привычном инструменте, показать инвесторам или кредиторам.
Теперь вы знаете, как вести финансовый учет в бизнесе и понимаете, зачем составлять отчет о прибылях и убытках предприятия, отчет о движении денежных средств и отчет по балансу. Эти знания помогут предотвратить кассовый разрыв и минимизировать потери, если он все же наступил. О том, как вести финансовый учет в Excel, забудьте — есть более удобные современные сервисы для этих целей.
С пониманием того, как правильно вести финансовый учет, вы убережете свой бизнес от многих проблем. Отслеживайте ключевые показатели и будьте успешны!
Отслеживайте ключевые показатели и будьте успешны!
Финансовая отчетность | ООО «СМАРТ Партнер»
ООО «СМАРТ Партнер» согласно Инструкции об объеме и порядке раскрытия информации о лизинговой деятельности и финансовом состоянии лизинговых организаций, включенных в реестр лизинговых организаций, утвержденной Постановлением Правления Национального банка Республики Беларусь от 01.08.2014г. №495 представляет следующую информацию:
ООО «СМАРТ Партнер» зарегистрировано Минским городским исполнительным комитетом 05 октября 2012 года в Едином государственном регистре юридических лиц и индивидуальных предпринимателей за № 191766663. ООО «СМАРТ Партнер» 16 сентября 2014 года включен в реестр лизинговых организаций с присвоением идентификационного кода 10007.Уставный фонд ООО «СМАРТ Партнер» сформирован в размере 93000 BYN.
Свидетельство о включении в реестр лизинговых организаций — Смотреть.
Свидетельство о государственной регистрации — Смотреть.
Устав ООО «СМАРТ Партнер» — Смотреть.
Годовая финансовая отчетность ООО «СМАРТ Партнер»:
За 2013 год:
За 2014 год:
За 2015 год:
За 2016 год:
За 2017 год:
За 2018 год:
За 2019 год:
За 2020 год:
За 2021 год:
Декларация о присоединении к кодексу добросовестного поведения и профессиональной этики лизинговых организаций Республики Беларусь
Смотреть.
Уведомление о смене юридического адреса
Смотреть.
Изменение реквизитов
Смотреть.
Уведомление о смене главного бухгалтера.
С 08 января 2019 года Индивидуальный предприниматель Шуста Елена Александровна, действующая на основании Свидетельства о государственной регистрации 0156124 от 10. 07.2008г оказывает бухгалтерские услуги и ведет бухгалтерский учет ООО «СМАРТПартнер».
07.2008г оказывает бухгалтерские услуги и ведет бухгалтерский учет ООО «СМАРТПартнер».
Смотреть свидетельство.
Юридическим лицам и индивидуальным предпринимателям ООО «СМАРТ Партнер» предоставляет услуги финансового лизинга.
Договор финансового лизинга – это соглашение между лизингодателем и лизингополучателем об установлении прав и обязанностей по поводу приобретения лизингодателем в собственность указанного лизингополучателем предмета лизинга у определенного последним продавца (поставщика) и предоставления лизингополучателю объекта лизинга за плату во временное владение и пользование с правом или без права выкупа либо предоставления лизингодателем лизингополучателю ранее приобретенного предмета лизинга за плату во временное владение и пользование с правом или без права выкупа.
ООО «СМАРТ Партнер» оказывает следующие услуги:
- Финансовый лизинг
- Лизинг автомобилей;
- Лизинг строительной техники;
- Лизинг оборудования;
- Лизинг недвижимости;
- Валютный лизинг — возможность приобретения предмета лизинга за границей и заключение внешнеэкономических контрактов;
- Микролизинг – лизинг офисной мебели,компьютеров, ноутбуков, принтеров, сотовых телефонов, любой другой оргтехники и т. д.
 д.
д.Порядок осуществления расчетов:
- расчеты производятся платежными поручениями в безналичном порядке на расчетный счет ООО «СМАРТ Партнер»;
- по соглашению сторон, расчеты могут быть произведены в иных не запрещенных законодательством РБ формах;
- уплата лизинговых платежей производится в белорусских рублях и в иностранной валюте, если использование иностранной валюты для проведения расчетов по договору лизинга разрешено законодательством.
Условия проведения сделок:
- Авансовый платеж: от 20% до 40%.
- Срок лизинга: от 1 до 4-х лет.
- Лизинговые платежи осуществляются ежемесячно. В состав лизингового платежа входит возмещение стоимости предмета лизинга и вознаграждение (доход) лизингодателя.
- Размер выкупной стоимости предмета лизинга определяется по соглашению сторон и может составлять от 10% до 1% от стоимости предмета лизинга.
- Валюта договора лизинга: в белорусских рублях, долларах США (евро) с оплатой в белорусских рублях по курсу НБ РБ.
- Договор купли-продажи предмета лизинга заключается лизингодателем.
- В рамках реализации договора лизинга лизингодателем и/или лизингополучателем могут при необходимости заключаться договора добровольного страхования предмета лизинга, договора поручительства. С целью финансирования договора лизинга лизингодателем могут привлекаться кредитные (заемные) ресурсы, что предполагает заключение кредитного договора (договора займа), договоров залога, поручительства (при необходимости).

*Данные условия не являются публичной офертой и могут изменяться. Окончательные условия устанавливаются в договоре лизинга
Порядок и условия определения вознаграждения (дохода) за осуществление лизинговой сделки:
Размер вознаграждения (дохода) ООО «СМАРТ Партнер» определяется по соглашению сторон Договора лизинга в виде денежной суммы и указывается в Графике лизинговых платежей, который является отдельным приложением и неотъемлемой частью Договора лизинга. Вознаграждение (доход) входит в состав лизинговых платежей.
Вознаграждение (доход) входит в состав лизинговых платежей.
Лизинговая компания ООО «СМАРТ Партнер» предлагает юридическим лицам и индивидуальным предпринимателям заключить договор лизинга, в который входит ГИБКИЙ ГРАФИК лизинговых платежей. Каждый клиент для нас индивидуален.
Мы УЧИТЫВАЕМ СЕЗОННОСТЬ вашего бизнеса в течение календарного года и делаем размер лизинговых платежей удобным и соразмерными вашим ежемесячным приходам. ООО «СМАРТ Партнер» для всех клиентов без исключения предлагает возможность БЕСПЛАТНОГО ДОСРОЧНОГО ПОГАШЕНИЯ лизинговых платежей с пересчетом лизинговой ставки.
Заявку на услуги лизинговой компании «СМАРТ Партнер» можно заполнить на сайте www.smartpartner.by либо связаться с нами по телефонам:
- +375 29 190-96-79 Velcom
- +375 17 326-96-79
Мы находимся по адресу: г. Минск, ул. Некрасова 7, к. 219
Время работы:
Понедельник-пятница: 9.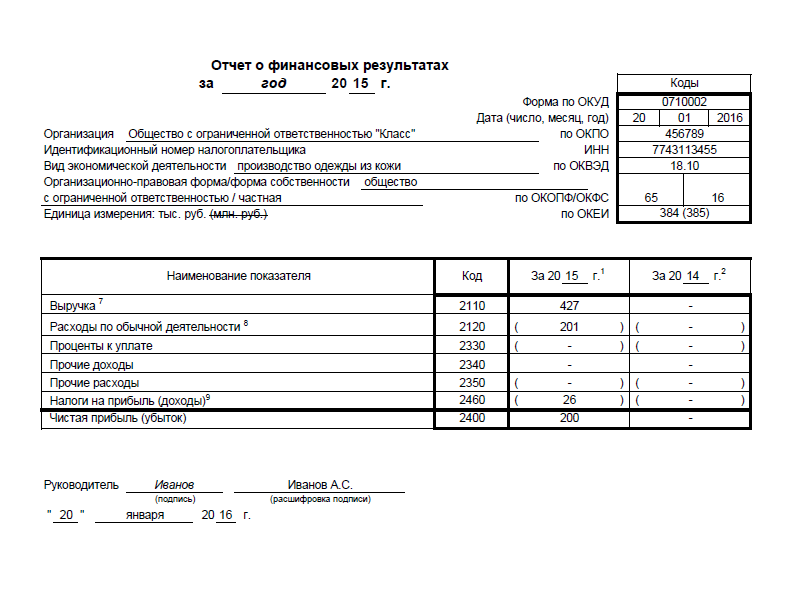 30-17.00
30-17.00
суббота-воскресенье: Выходной
Бухгалтерская отчетность по РСБУ — ПАО «Транснефть»
Бухгалтерская отчетность по РСБУ, опубликованная в соответствии с требованиями законодательства о раскрытии информации на рынке ценных бумаг.
2021
Промежуточная бухгалтерская отчетность на 30.09.2021
2020
Аудиторское заключение по бухгалтерской отчетности ПАО «Транснефть» за 2020 год
Бухгалтерский баланс на 31 декабря 2020 года
Отчет о финансовых результатах за 2020 год
Отчет об изменениях капитала за 2020 год
Отчет о движении денежных средств за 2020 год
Пояснения к бухгалтерскому балансу и отчету о финансовых результатах ПАО «Транснефть» за 2020 год
Промежуточная бухгалтерская отчетность на 30.09.2020
Промежуточная бухгалтерская отчетность на 30.06.2020
Промежуточная бухгалтерская отчетность на 31.03.2020
2019
Аудиторское заключение по бухгалтерской отчетности ПАО «Транснефть» за 2019 год
Бухгалтерский баланс на 31 декабря 2019 года
Отчет о финансовых результатах за 2019 год
Отчет об изменениях капитала за 2019 год
Отчет о движении денежных средств за 2019 год
Пояснения к бухгалтерскому балансу и отчету о финансовых результатах ПАО «Транснефть» за 2019 год
Промежуточная бухгалтерская отчетность на 30.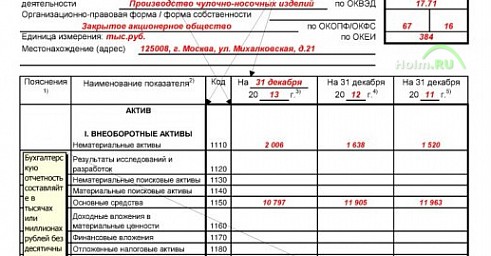 09.2019
09.2019
Промежуточная бухгалтерская отчетность на 30.06.2019
Промежуточная бухгалтерская отчетность на 31.03.2019
2018
Аудиторское заключение по бухгалтерской отчетности ПАО «Транснефть» за 2018 год
Бухгалтерский баланс на 31 декабря 2018 года
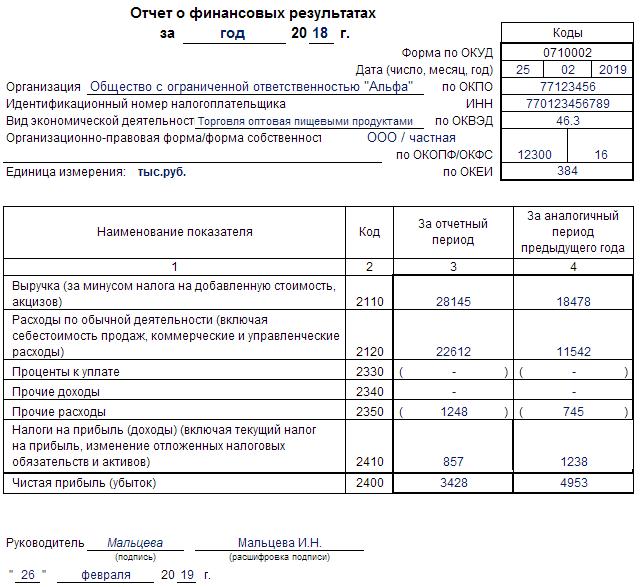
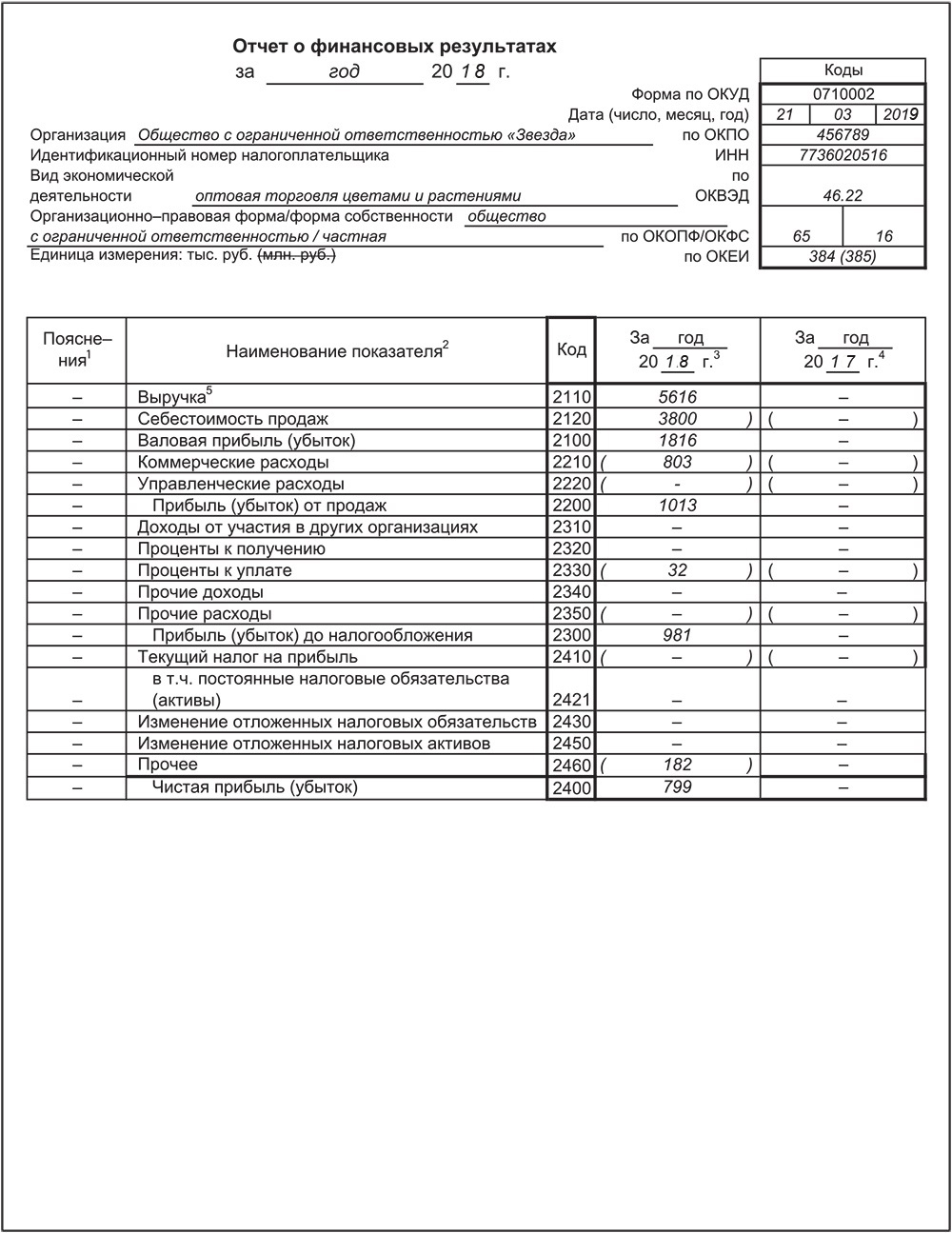
Отчет о финансовых результатах за 2018 год
Отчет об изменениях капитала за 2018 год
Отчет о движении денежных средств за 2018 год
Пояснения к бухгалтерскому балансу и отчету о финансовых результатах ПАО «Транснефть» за 2018 год
Промежуточная бухгалтерская отчетность на 30.09.2018
Промежуточная бухгалтерская отчетность на 30.06.2018
Промежуточная бухгалтерская отчетность на 31.03.2018
2017
Аудиторское заключение по бухгалтерской отчетности ПАО «Транснефть» за 2017 год
Бухгалтерский баланс на 31 декабря 2017 года
Отчет о финансовых результатах за 2017 год
Отчет об изменениях капитала за 2017 год
Отчет о движении денежных средств за 2017 год
Пояснения к бухгалтерскому балансу и отчету о финансовых результатах ПАО «Транснефть» за 2017 год
Промежуточная бухгалтерская отчетность на 30. 09.2017
09.2017
Промежуточная бухгалтерская отчетность на 30.06.2017
2016
Аудиторское заключение по бухгалтерской отчетности ПАО «Транснефть» за 2016 год
Бухгалтерский баланс на 31 декабря 2016 года
Отчет о финансовых результатах за 2016 год
Отчет об изменениях капитала за 2016 год
Отчет о движении денежных средств за 2016 год
Пояснения к бухгалтерскому балансу и отчету о финансовых результатах ПАО «Транснефть» за 2016 год
2015
Аудиторское заключение по бухгалтерской отчетности ОАО «АК «Транснефть» за 2015 год
Бухгалтерский баланс на 31 декабря 2015 года
Отчет о финансовых результатах за 2015 год
Отчет об изменениях капитала за 2015 год
Отчет о движении денежных средств за 2015 год
Пояснения к бухгалтерскому балансу и отчету о финансовых результатах ОАО «АК «Транснефть» за 2015 год
2014
Аудиторское заключение по бухгалтерской отчетности ОАО «АК «Транснефть» за 2014 год
Бухгалтерский баланс на 31 декабря 2014 года
Отчет о финансовых результатах за 2014 год
Отчет об изменениях капитала за 2014 год
Отчет о движении денежных средств за 2014 год
Пояснения к бухгалтерскому балансу и отчету о финансовых результатах ОАО «АК «Транснефть» за 2014 год
2013
Аудиторское заключение по бухгалтерской отчетности ОАО «АК «Транснефть» за 2013 год
Бухгалтерский баланс на 31 декабря 2013 года
Отчет о финансовых результатах за 2013 год
Отчет об изменениях капитала за 2013 год
Отчет о движении денежных средств за 2013 год
Пояснения к бухгалтерскому балансу и отчету о финансовых результатах ОАО «АК «Транснефть» за 2013 год
2012
Аудиторское заключение по бухгалтерской отчетности ОАО «АК «Транснефть» за 2012 год
Бухгалтерский баланс на 31 декабря 2012 года
Отчет о финансовых результатах за 2012 год
Отчет об изменениях капитала за 2012 год
Отчет о движении денежных средств за 2012 год
Пояснения к бухгалтерскому балансу и отчету о финансовых результатах ОАО «АК «Транснефть» за 2012 год
2011
Аудиторское заключение по бухгалтерской отчетности ОАО «АК «Транснефть» за 2011 год
Бухгалтерский баланс на 31 декабря 2011 года
Отчет о прибылях и убытках за 2011 год
Отчет об изменениях капитала за 2011 год
Отчет о движении денежных средств за 2011 год
Пояснительная записка к годовой бухгалтерской отчетности ОАО «АК «Транснефть» за 2011 год
Расшифровка расчётного счёта: что означают цифры в номере
При открытии расчётного счёта в банке вы получаете комбинацию из цифр, которая по сути является индивидуальным шифром для хранения средств. В целом вам необязательно знать все особенности расшифровки — банки действуют строго в рамках закона, а комбинация из цифр формируется вычислительной системой. Однако знать матчасть все же стоит: ошибка в двух цифрах при отправке платежа на счёт юридического лица может стоить вам времени и денег. Вы также будете больше знать о ваших партнерах по бизнесу, внимательно изучив их расчетный счет.
В целом вам необязательно знать все особенности расшифровки — банки действуют строго в рамках закона, а комбинация из цифр формируется вычислительной системой. Однако знать матчасть все же стоит: ошибка в двух цифрах при отправке платежа на счёт юридического лица может стоить вам времени и денег. Вы также будете больше знать о ваших партнерах по бизнесу, внимательно изучив их расчетный счет.
Структура банковского счёта
Расчётный счёт состоит из 20 цифр, каждая из которых имеет свое значение. Все числа, входящие в номер, разделены на группы, которые отражает определенные характеристики счёта.
Отметим, что счёт физического лица всегда начинается с цифр 408. Эта комбинация едина для всех российских банков. При этом ИП, хоть и являются формально физлицами, их счета начинаются так же, как и юридических: с 407.
Теперь расшифровываем значение счёта, разбив номер на группы: 111.22.333.4.5555.6666666:
111 — счёт первого порядка банковского баланса, по которому можно узнать, кто открыл счёт и с какой целью.
22 — счёт второго порядка, и эти цифры указывают на специфику деятельности владельца счёта.
333 — валюта, в которой хранятся средства на счету.
4 — проверочный код.
5555 — комбинация, означающая отделение банка, в котором открыт счёт.
6666666 — порядковый номер счёта в вашем банке.
Как расшифровать цифры?
Для начала выясним, что означает расшифровка первых пяти цифр в расчётном счёте, которые составляют определенную группу счетов баланса банка. Эти счета утверждены Центробанком и включают два раздела.
Первый состоит из трех цифр и означает специфику расчётов. Например, эти комбинации имеют разную расшифровку:
от 102 до 109 — счета фондов, а также хранение капитала, учёт прибыли и убытков;
203 и 204 — счета для учёта драгметаллов;
с 301 по 329 — счета для проведения операций между банками;
401 и 402 — счета для переводов в бюджет;
403 — управление деньгами, находящимся в ведении Минфина;
404 — внебюджетные фонды;
405 и 406 — счета государственных компаний;
407 — юридические компании и ИП;
408 — физлица;
с 411 по 419 — вклады, открытые государственными структурами;
с 420 по 422 — хранение средств юридических лиц;
423 — вклад открыт физическим лицом-резидентом;
424 — средства иностранных компаний;
425 — средства на вкладе принадлежат физическому лицу-нерезиденту;
430 — средства банков;
с 501 по 526 — счета, необходимые для учета ценных бумаг.
Следующие две цифры в расчётном счёте дополняют три предыдущие и трактуются вместе с ними. Теперь давайте разберем их на примере юридических компаний. Напоминаем, счета юрлиц начинаются с 407.
40701 — организация имеет отношение к финансовому сектору;
40702 — открытые и закрытые общества;
40703 — счета некоммерческих объединений;
40704 — средства, выделенные для проведения выборов или общественных собраний.
Следующие три цирфы счёта означают валюту, в которой открыт счет. А именно:
810 — счет открыт в рублях;
840 — в долларах США;
978 — в евро.
Затем следует проверочная цифра — ключ, который позволяет выяснить, правильно ли обозначен счёт при помощи обработки автоматической системы.
Следующие четыре цифры означают номер отделения, в котором открыт счёт. Если вместо них указаны нули, то банк либо не владеет отделениями, либо же счёт был открыт в головном офисе.
Последние семь цифр — это порядковый регистр счёта в банке. Отметим, что по закону любой банк вправе применять свою классификацию этих цифр.
Напоминаем, что в ДелоБанке вы можете открыть бесплатно расчётный счёт буквально за 10 минут. Просто оставьте свой телефон в заявке и наш оператор свяжется с вами в самое ближайшее время. На счёт можно получать деньги после резервирования, и номер можно указывать в любых документах – он не изменится после активации.
Финансовая отчетность на практическом примере
Финансовая отчетность – информация о финансовом положении, результатах деятельности и изменениях в финансовом положении индивидуального предпринимателя или организации. Составить ее правильно и без ошибок поможет эксперт.
Целью бухгалтерского учета и финансовой отчетности является обеспечение заинтересованных лиц полной и достоверной информацией о финансовом положении, результатах деятельности и изменениях в финансовом положении индивидуальных предпринимателей (ИП) и организаций.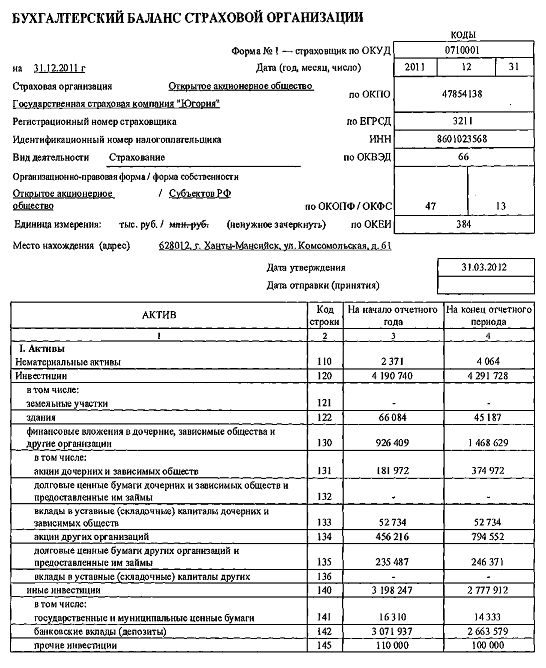
Отчетным периодом для годовой финансовой отчетности является календарный год начиная с 1 января по 31 декабря. Первый отчетный год для вновь созданной организации начинается с момента ее государственной регистрации по 31 декабря того же года.
Систему бухгалтерского учета и финансовой отчетности в РК регулирует Закон РК «О бухгалтерском учете и финансовой отчетности» от 28 февраля 2007 года № 234-III (далее – Закон о бухгалтерском учете).
Законом о бухгалтерском учете установлена обязанность всех ИП и юридических лиц вести бухгалтерский учет и составлять финансовую отчетность, за исключением ИП, соответствующих одновременно следующим условиям:
1) применяют в соответствии с налоговым законодательством РК специальные налоговые режимы на основе патента, упрощенной декларации;
2) не состоят на регистрационном учете по НДС;
3) не являются субъектами естественных монополий.
В Казахстане утверждены три стандарта, регламентирующих правила составления финансовой отчетности, которым должны следовать организации: Национальный стандарт финансовой отчетности (НСФО) либо по выбору: Международные стандарты финансовой отчетности (МСФО), Международные стандарты финансовой отчетности для предприятий малого и среднего бизнеса (МСФО для МСБ).
Финансовая отчетность, за исключением отчетности государственных учреждений, включает в себя:
1) бухгалтерский баланс;
2) отчет о прибылях и убытках;
3) отчет о движении денежных средств;
4) отчет об изменениях в капитале;
5) пояснительную записку.
Для того чтобы финансовая отчетность обеспечивала достижение своей главной цели – представление информации о финансовом положении, финансовых результатах и денежных потоках организации, она должна быть достоверной.
На практике составление финансовой отчетности начинается с проверки бухгалтерской оборотно-сальдовой ведомости за период. Необходимо убедиться, что все сальдо на постоянных счетах не имеют кредитовых остатков на активных счетах и дебетовых остатков на пассивных счетах на конец отчетного периода. Также необходимо проверить, что транзитные счета не имеют сальдо в конце отчетного периода и перенесены на постоянные счета.
Финансовая отчетность составляется на основе оборотно-сальдовой ведомости.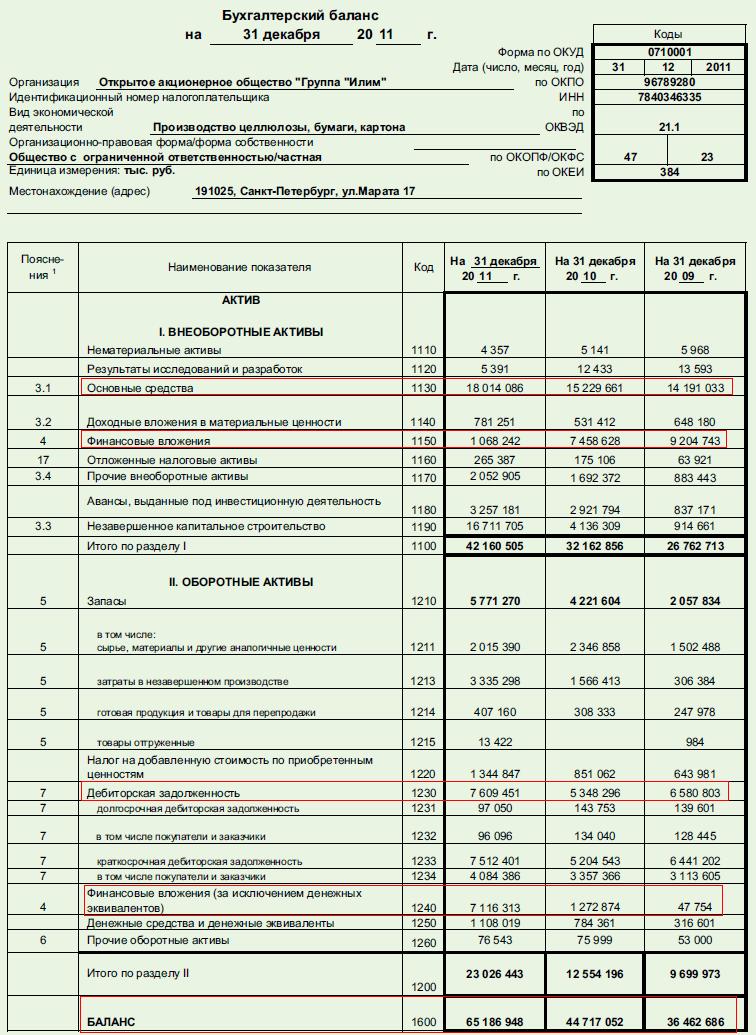 За основу соответствия конкретных счетов статьям «Бухгалтерский баланс» и «Отчет о прибылях и убытках» (ОПУ) возможно взять пояснения к заполнению финансовой отчетности, утвержденные приказом министра финансов РК от 28 июня 2017 года № 404.
За основу соответствия конкретных счетов статьям «Бухгалтерский баланс» и «Отчет о прибылях и убытках» (ОПУ) возможно взять пояснения к заполнению финансовой отчетности, утвержденные приказом министра финансов РК от 28 июня 2017 года № 404.
Пример
ТОО «А» является субъектом малого предпринимательства и составляет финансовую отчетность в соответствии с НСФО. Следует составить финансовую отчетность.
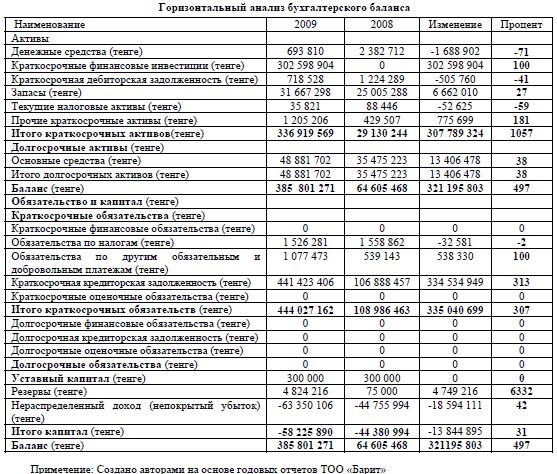
Оборотно-сальдовая ведомость ТОО «А» за 2018 год
тенге
Составим баланс с учетом соответствия счетов оборотно-сальдовой ведомости строкам финансовой отчетности.
Бухгалтерский баланс ТОО «А» на 31 декабря 2018 года
тенге
Отчет о прибылях и убытках составляем в соответствии транзитных счетов оборотно-сальдовой ведомости строкам финансовой отчетности.
Отчет о прибылях и убытках ТОО «А» за 2018 год
тенге
При составлении отчета о движении денежных средств необходимо проконтролировать соответствие сумм по строкам:
– сумма в строке 140 за предыдущий период в отчете о движении денежных средств должна соответствовать строке 010 баланса на начало отчетного периода;
– сумма в строке 150 за отчетный период в отчете о движении денежных средств должна соответствовать строке 010 баланса на конец отчетного периода.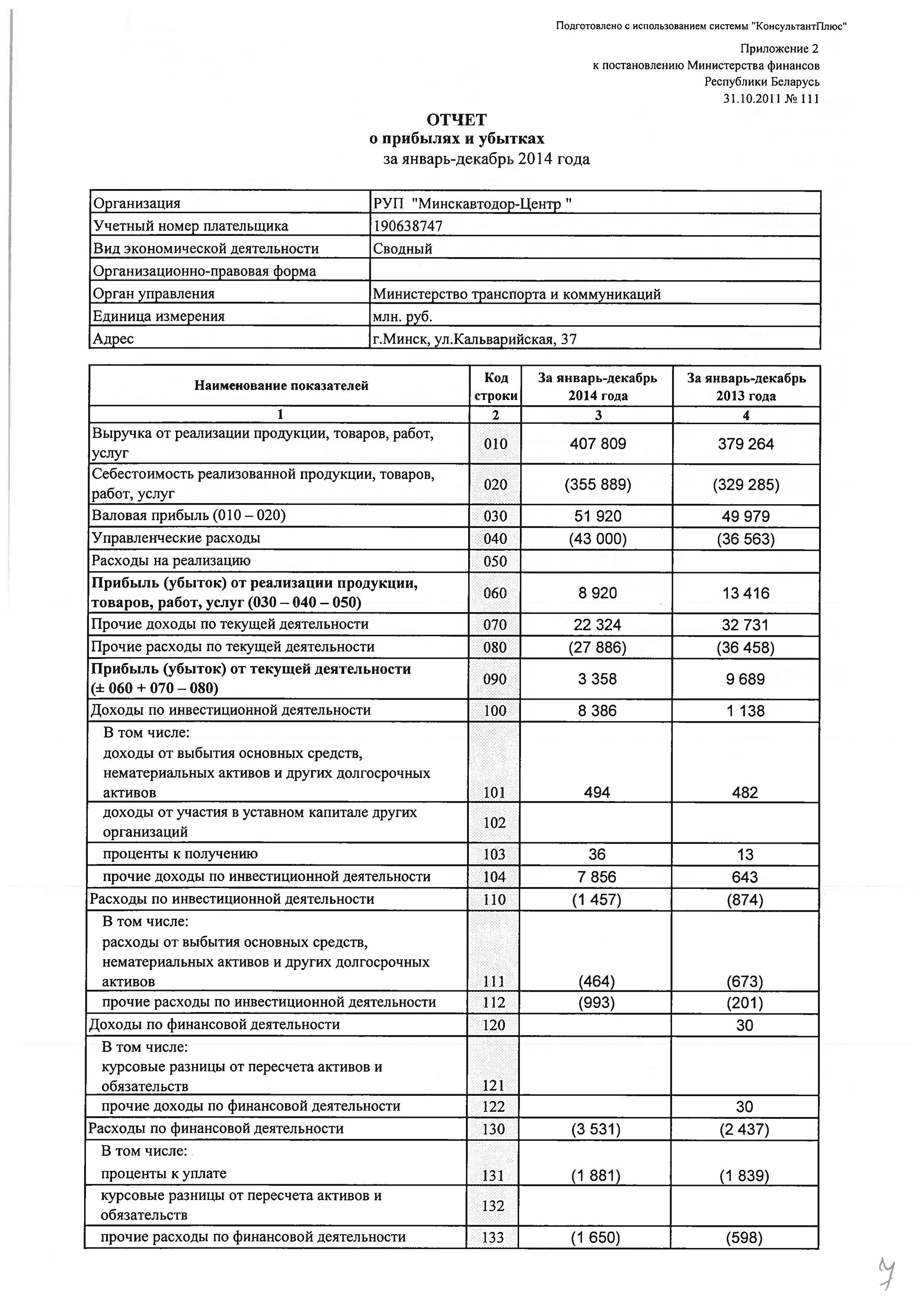
Отчет о движении денежных средств ТОО «А» за 2018 год (прямой метод)
тенге
Для контроля правильности составления отчета об изменениях в капитале необходимо сверить суммы уставного капитала и нераспределенной прибыли в отчете и балансе на начало и конец отчетного периода.
Отчет об изменениях в собственном капитале ТОО «А» за 2018 год
тенге
Для того чтобы отчетность, составленная в соответствии с требованиями законодательства РК, соответствовала нормам МСФО, необходимо внести корректировки.
Возможных корректировок, связанных с различием требований МСФО и законодательства РК, огромное множество. Рассмотрим некоторые из них:
Перечень и формы годовой финансовой отчетности для публикации организациями публичного интереса разрабатываются и утверждаются уполномоченным органом (приказ министра финансов РК от 28 июня 2017 года № 404).
В соответствии с пунктом 7 статьи 19 Закона о бухгалтерском учете, организации публичного интереса обязаны сдавать в депозитарий финансовую отчетность в порядке, установленном Правительством РК, в срок до 31 августа года, следующего за отчетным.
Объем, формы и порядок составления финансовой отчетности государственных учреждений, за исключением Национального Банка РК, устанавливаются бюджетным законодательством РК.
Постоянство клиентского IP-адреса или исходный IP-хэш Балансировка нагрузки
Ну это примерно то же самое! Зависит от людей, среды, продуктов и т. д. В этой статье я могу использовать оба из них, но имейте в виду, что оба они указывают на IP-адрес, который используется для подключения к службе, для которой выполняется балансировка нагрузки.
Балансировка нагрузки — это возможность распределять запросы между пулом серверов, которые предоставляют одну и ту же услугу. По определению это означает, что любой запрос может быть отправлен на любой сервер в пуле.
Некоторым приложениям требуется липкость между клиентом и сервером: это означает, что все запросы от клиента должны быть отправлены на один и тот же сервер. В противном случае сеанс приложения может быть прерван, что может негативно сказаться на клиенте.
У нас может быть много способов привязать пользователя к серверу, которые уже обсуждались в этом блоге (прочитайте балансировку нагрузки, сходство, постоянство, закрепленные сеансы: что вам нужно знать) (и многие другие статьи могут последовать).
Тем не менее, иногда единственной информацией, на которую мы можем «полагаться» для выполнения прилипания, является IP-адрес клиента (или источника).
Обратите внимание, что это не оптимально, потому что:
* многие клиенты могут быть «спрятаны» за одним IP-адресом (брандмауэр, прокси и т. д.)
* клиент может изменить свой IP-адрес во время сеанса
* клиент может использовать несколько IP-адресов адреса
* и т.д…
Существует два способа выполнения сопоставления исходного IP-адреса:
1. Использование специального алгоритма балансировки нагрузки: хэш на исходном IP-адресе
2. Использование флеш-таблицы в памяти (и циклического алгоритма балансировки нагрузки)
На самом деле, основная цель этой статьи состояла в том, чтобы представить оба метода, которые довольно часто неправильно понимают, и показать плюсы и минусы каждого, чтобы люди могли принять правильное решение при настройке своего Load-Balancer.
Алгоритм балансировки нагрузки хэша IP-адреса источника
Этот алгоритм является детерминированным . Это означает, что если никакие элементы не участвуют в вычислении хэша, то результат будет таким же. 2 могут применять один и тот же хэш, следовательно, балансировка нагрузки выполняется одинаково, что делает аварийное переключение балансировщика нагрузки прозрачным.
К исходному IP-адресу входящего запроса применена хэш-функция. Хэш должен учитывать количество серверов и вес каждого сервера.
Следующие события могут привести к изменению хэша и, таким образом, могут по-разному перенаправлять трафик с течением времени:
* сервер в пуле выходит из строя
* сервер в пуле поднимается вверх
* изменение веса сервера
Основная проблема с алгоритмом балансировки хеш-нагрузки исходного IP заключается в том, что каждое изменение может перенаправить ВСЕХ на другой сервер!!!
Вот почему некоторые хорошие балансировщики нагрузки внедрили согласованный метод хеширования, который гарантирует, что, например, в случае сбоя сервера перенаправляются только клиенты, подключенные к этому серверу.
Обратной стороной последовательного хеширования является то, что оно не обеспечивает идеального хеширования, поэтому в ферме из 4 серверов одни могут получать больше клиентов, чем другие.
Обратите внимание, что когда отказавший сервер возвращается, его «застрявшие» пользователи (определяемые хэшем) будут перенаправлены на него.
При использовании такого алгоритма нет накладных расходов на ЦП или память.
Пример конфигурации в HAProxy или в ALOHA Load-Balancer:
источник баланса согласованный хеш-тип
Сохранение исходного IP-адреса с использованием флеш-таблицы
Балансировщик нагрузки создает таблицу в памяти для хранения исходного IP-адреса и затронутого сервера из пула.
Мы можем положиться на любой недетерминированный алгоритм балансировки нагрузки, такой как циклический алгоритм или наименьшее соединение (обычно это зависит от типа приложения, для которого выполняется балансировка нагрузки).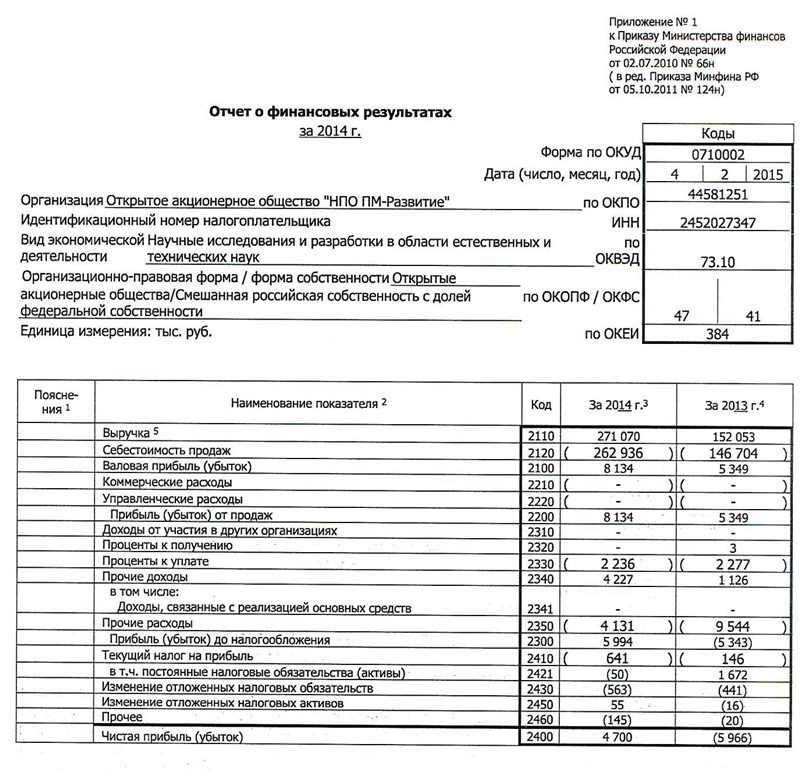
После того, как клиент привязан к серверу, он остается привязанным до тех пор, пока не истечет срок действия записи в таблице ИЛИ сервер не выйдет из строя.
В памяти есть служебные данные для хранения информации о закреплении. В HAProxy накладные расходы довольно низкие: 40 МБ для 1 000 000 адресов IPv4.
Одним из основных преимуществ использования флеш-таблицы является то, что при восстановлении отказавшего сервера никакие существующие сеансы не будут перенаправлены на него.До него могут добраться только новые входящие IP-адреса. Так что никакого влияния на пользователей.
Также можно синхронизировать таблицы в памяти между несколькими HAProxy или ALOHA Load-Balancers , что делает аварийное переключение LB прозрачным.
Пример конфигурации в HAProxy или в ALOHA Load-Balancer :
тип палки-таблицы размер IP 1 м срок действия 1 час придерживаться источника
Балансировка нагрузки HTTP | НГИНКС Плюс
Балансировка нагрузки HTTP-трафика между веб-группами или группами серверов приложений с несколькими алгоритмами и расширенными функциями, такими как медленный запуск и сохранение сеанса.
Обзор
Балансировка нагрузки между несколькими экземплярами приложения — это широко используемый метод оптимизации использования ресурсов, увеличения пропускной способности, уменьшения задержки и обеспечения отказоустойчивости конфигураций.
Посмотрите вебинар NGINX Plus для балансировки нагрузки и масштабирования по запросу, чтобы подробно изучить методы, которые пользователи NGINX используют для создания крупномасштабных высокодоступных веб-сервисов.
NGINX и NGINX Plus можно использовать в различных сценариях развертывания в качестве очень эффективного балансировщика нагрузки HTTP.
Проксирование HTTP-трафика на группу серверов
Чтобы начать использовать NGINX Plus или NGINX Open Source для балансировки нагрузки HTTP-трафика на группу серверов, сначала необходимо определить группу с помощью директивы upstream . Директива находится в контексте http .
Серверы в группе настраиваются с помощью директивы server (не путать с блоком server , который определяет виртуальный сервер, работающий на NGINX). Например, следующая конфигурация определяет группу с именем backend и состоит из трех конфигураций серверов (которые могут разрешаться более чем в трех фактических серверах):
Например, следующая конфигурация определяет группу с именем backend и состоит из трех конфигураций серверов (которые могут разрешаться более чем в трех фактических серверах):
http {
восходящий сервер {
сервер backend1.example.com вес=5;
сервер backend2.example.com;
резервная копия сервера 192.0.0.1;
}
}
Для передачи запросов к группе серверов имя группы указывается в директиве proxy_pass (или fastcgi_pass , memcached_pass , scgi_pass , или директиве uws8gi_passives protocols.) В следующем примере виртуальный сервер, работающий на NGINX, передает все запросы в группу backend upstream, определенную в предыдущем примере:
сервер {
место расположения / {
прокси_пасс http://бэкэнд;
}
}
В следующем примере объединены два приведенных выше фрагмента и показано, как проксировать HTTP-запросы к группе внутренних серверов . Группа состоит из трех серверов, на двух из которых запущены экземпляры одного и того же приложения, а третий является сервером резервного копирования.Поскольку в восходящем блоке
Группа состоит из трех серверов, на двух из которых запущены экземпляры одного и того же приложения, а третий является сервером резервного копирования.Поскольку в восходящем блоке не указан алгоритм балансировки нагрузки, NGINX использует алгоритм по умолчанию, Round Robin:
http {
восходящий сервер {
сервер backend1.example.com;
сервер backend2.example.com;
резервная копия сервера 192.0.0.1;
}
сервер {
место расположения / {
прокси_пасс http://бэкэнд;
}
}
}
Выбор метода балансировки нагрузки
NGINX Open Source поддерживает четыре метода балансировки нагрузки, а NGINX Plus добавляет еще два метода:
Round Robin — запросы равномерно распределяются по серверам с учетом веса серверов.Этот метод используется по умолчанию (нет директивы для его включения):
восходящий сервер { # для циклического перебора не указан метод балансировки нагрузки сервер backend1. example.com;
сервер backend2.example.com;
}
Наименьшее количество подключений — запрос отправляется на сервер с наименьшим количеством активных подключений, опять же с учетом весов серверов:
восходящий сервер { наименьшее_соединение; сервер backend1.example.ком; сервер backend2.example.com; }IP Hash — сервер, на который отправляется запрос, определяется по IP-адресу клиента. В этом случае для вычисления хеш-значения используются либо первые три октета адреса IPv4, либо весь адрес IPv6. Метод гарантирует, что запросы с одного и того же адреса попадают на один и тот же сервер, если он недоступен.
восходящий сервер { ip_хэш; сервер backend1.example.com; серверная часть2.пример.com; }Если один из серверов необходимо временно исключить из ротации балансировки нагрузки, его можно пометить параметром down, чтобы сохранить текущее хеширование клиентских IP-адресов.
Запросы, которые должны были быть обработаны этим сервером, автоматически отправляются на следующий сервер в группе:восходящий сервер { сервер backend1.example.com; сервер backend2.example.com; сервер backend3.example.com не работает; }Generic Hash — сервер, на который отправляется запрос, определяется определяемым пользователем ключом, который может быть текстовой строкой, переменной или их комбинацией.Например, ключ может быть парой исходного IP-адреса и порта или URI, как в этом примере:
.восходящий сервер { хеш $request_uri согласован; сервер backend1.example.com; сервер backend2.example.com; }Дополнительный согласованный параметр директивы
hashвключает балансировку нагрузки ketama с согласованным хэшем. Запросы равномерно распределяются по всем вышестоящим серверам на основе заданного пользователем значения хешированного ключа. Если вышестоящий сервер добавляется в вышестоящую группу или удаляется из нее, переназначаются только несколько ключей, что сводит к минимуму промахи в кэше в случае кэш-серверов с балансировкой нагрузки или других приложений, накапливающих состояние.Наименьшее время (только NGINX Plus) — для каждого запроса NGINX Plus выбирает сервер с наименьшей средней задержкой и наименьшим количеством активных соединений, где наименьшая средняя задержка рассчитывается на основе одного из следующих параметров
наименьшего_времени. включена директива:-
заголовок— Время получения первого байта от сервера -
last_byte— Время получения полного ответа от сервера -
last_byte inflight— Время получения полного ответа от сервера с учетом незавершенных запросов
восходящий сервер { заголовок наименьшее_время; серверная часть1.пример.com; сервер backend2. example.com;
}
-
Random — каждый запрос будет передан на случайно выбранный сервер. Если указан параметр
two, то сначала NGINX случайным образом выбирает два сервера с учетом весов серверов, а затем выбирает один из этих серверов указанным методом:-
less_conn— Наименьшее количество активных подключений -
less_time=header(NGINX Plus) — наименьшее среднее время получения заголовка ответа от сервера ($upstream_header_time) -
наименьшее_время=последний_байт(NGINX Plus) — наименьшее среднее время получения полного ответа от сервера ($upstream_response_time)
восходящий сервер { случайные два наименьшее_время=последний_байт; серверная часть1.пример.com; сервер backend2.example.com; сервер backend3.example.com; сервер backend4.example.com; }Метод балансировки нагрузки Random следует использовать для распределенных сред, в которых несколько балансировщиков нагрузки передают запросы одному и тому же набору серверных частей.
Для сред, в которых балансировщик нагрузки имеет полное представление обо всех запросах, используйте другие методы балансировки нагрузки, такие как циклический перебор, наименьшее количество подключений и наименьшее время.-
 example.com;
сервер backend2.example.com;
}
example.com;
сервер backend2.example.com;
}
 Запросы, которые должны были быть обработаны этим сервером, автоматически отправляются на следующий сервер в группе:
Запросы, которые должны были быть обработаны этим сервером, автоматически отправляются на следующий сервер в группе: Если вышестоящий сервер добавляется в вышестоящую группу или удаляется из нее, переназначаются только несколько ключей, что сводит к минимуму промахи в кэше в случае кэш-серверов с балансировкой нагрузки или других приложений, накапливающих состояние.
Если вышестоящий сервер добавляется в вышестоящую группу или удаляется из нее, переназначаются только несколько ключей, что сводит к минимуму промахи в кэше в случае кэш-серверов с балансировкой нагрузки или других приложений, накапливающих состояние. example.com;
}
example.com;
}
 Для сред, в которых балансировщик нагрузки имеет полное представление обо всех запросах, используйте другие методы балансировки нагрузки, такие как циклический перебор, наименьшее количество подключений и наименьшее время.
Для сред, в которых балансировщик нагрузки имеет полное представление обо всех запросах, используйте другие методы балансировки нагрузки, такие как циклический перебор, наименьшее количество подключений и наименьшее время.Примечание: При настройке любого метода, кроме Round Robin, поместите соответствующую директиву (
hash,ip_hash,last_conn,last_timeилиrandom 90s 9083 директивы server) над списком директив server .восходящий блок {}.
Вес сервера
По умолчанию NGINX распределяет запросы между серверами в группе в соответствии с их весами, используя метод Round Robin. Параметр weight директивы server задает вес сервера; по умолчанию 1 :
восходящий сервер {
сервер backend1.example.com вес=5;
сервер backend2. example.com;
резервная копия сервера 192.0.0.1;
}
 example.com;
резервная копия сервера 192.0.0.1;
}
example.com;
резервная копия сервера 192.0.0.1;
}
В примере backend1.example.com имеет вес 5 ; два других сервера имеют вес по умолчанию ( 1 ), но один с IP-адресом 192.0.0.1 помечен как резервный сервер и не получает запросы, если оба других сервера недоступны. При такой конфигурации весов из каждых 6 запросов 5 отправляются на backend1.example.com и 1 на backend2.example.com .
Медленный старт сервера
Функция медленного запуска сервера предотвращает перегрузку недавно восстановленного сервера соединениями, что может привести к истечению времени ожидания и повторной пометке сервера как неисправного.
В NGINX Plus медленный запуск позволяет вышестоящему серверу постепенно восстанавливать свой вес с 0 до номинального значения после того, как он был восстановлен или стал доступным.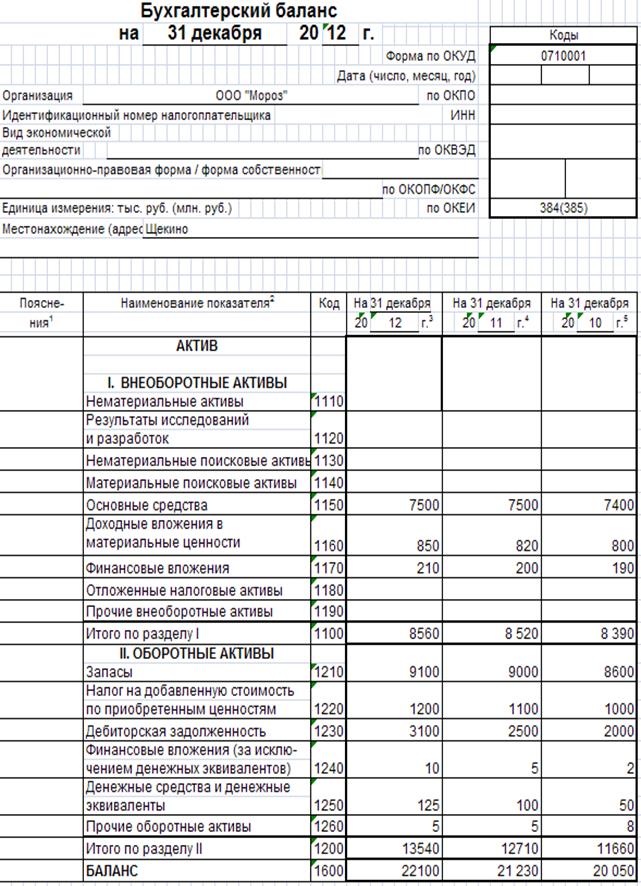 Это можно сделать с помощью параметра
Это можно сделать с помощью параметра slow_start в директиве server :
восходящий сервер {
сервер backend1.example.com slow_start=30s;
сервер backend2.example.com;
резервная копия сервера 192.0.0.1;
}
Значение времени (здесь 30 секунды) устанавливает время, в течение которого NGINX Plus увеличивает количество подключений к серверу до полного значения.
Обратите внимание, что если в группе только один сервер, параметры max_fails , fail_timeout и slow_start директивы server игнорируются, и сервер никогда не считается недоступным.
Включение сохранения сеанса
Сохранение сеанса означает, что NGINX Plus идентифицирует сеансы пользователей и направляет все запросы в данном сеансе на один и тот же вышестоящий сервер.
NGINX Plus поддерживает три метода сохранения сеанса.Методы задаются директивой sticky . (Для сохранения сеанса с NGINX с открытым исходным кодом используйте директиву
(Для сохранения сеанса с NGINX с открытым исходным кодом используйте директиву hash или ip_hash , как описано выше.)
Sticky cookie — NGINX Plus добавляет сеансовый cookie к первому ответу от вышестоящей группы и идентифицирует сервер, отправивший ответ. Следующий запрос клиента содержит значение cookie, и NGINX Plus направляет запрос на вышестоящий сервер, ответивший на первый запрос:
.восходящий сервер { серверная часть1.пример.com; сервер backend2.example.com; sticky cookie srv_id expires=1h domain=.example.com path=/; }В примере параметр
srv_idзадает имя файла cookie. Необязательный параметрexpiresзадает время, в течение которого браузер сохраняет файл cookie (здесь1час). Необязательный параметрdomainопределяет домен, для которого устанавливается файл cookie, а необязательный параметрpathопределяет путь, для которого устанавливается файл cookie. Это самый простой метод сохранения сеанса.Sticky route — NGINX Plus назначает «маршрут» клиенту при получении первого запроса. Все последующие запросы сравниваются с параметром
routeдирективыserverдля идентификации сервера, на который проксируется запрос. Информация о маршруте берется либо из файла cookie, либо из URI запроса.восходящий сервер { сервер backend1.example.com route=a; серверная часть2.маршрут example.com=b; фиксированный маршрут $route_cookie $route_uri; }Метод фиксированного обучения — NGINX Plus сначала находит идентификаторы сеансов, проверяя запросы и ответы. Затем NGINX Plus «узнает», какой восходящий сервер соответствует какому идентификатору сеанса. Как правило, эти идентификаторы передаются в файле cookie HTTP. Если запрос содержит уже «выученный» идентификатор сеанса, NGINX Plus перенаправляет запрос на соответствующий сервер:
.восходящий сервер { серверная часть1.пример.com; сервер backend2.example.com; липкое обучение создать=$upstream_cookie_examplecookie lookup=$cookie_examplecookie зона = client_sessions: 1 м таймаут=1ч; }В этом примере один из вышестоящих серверов создает сеанс, устанавливая файл cookie
EXAMPLECOOKIEв ответе.Обязательный параметр
createзадает переменную, указывающую, как создается новый сеанс. В этом примере новые сеансы создаются из файла cookieEXAMPLECOOKIE, отправленного вышестоящим сервером.Обязательный параметр поиска
EXAMPLECOOKIE, отправленном клиентом.Обязательный параметр
zoneуказывает зону общей памяти, в которой хранится вся информация о закрепленных сеансах. В нашем примере зона называется client_sessions и имеет размер1мегабайт.Это более сложный метод сохранения сеанса, чем два предыдущих, поскольку он не требует хранения файлов cookie на стороне клиента: вся информация хранится на стороне сервера в зоне общей памяти.
При наличии в кластере нескольких экземпляров NGINX, использующих метод «липкого обучения», возможна синхронизация содержимого их зон общей памяти при следующих условиях:
- зоны имеют одинаковое имя
- функциональность
zone_syncнастроена для каждого экземпляра - указан параметр синхронизации
липкое обучение создать=$upstream_cookie_examplecookie lookup=$cookie_examplecookie зона = client_sessions: 1 м таймаут=1ч синхронизировать; }Дополнительные сведения см. в разделе Совместное использование состояний среды выполнения в кластере.
 Это самый простой метод сохранения сеанса.
Это самый простой метод сохранения сеанса.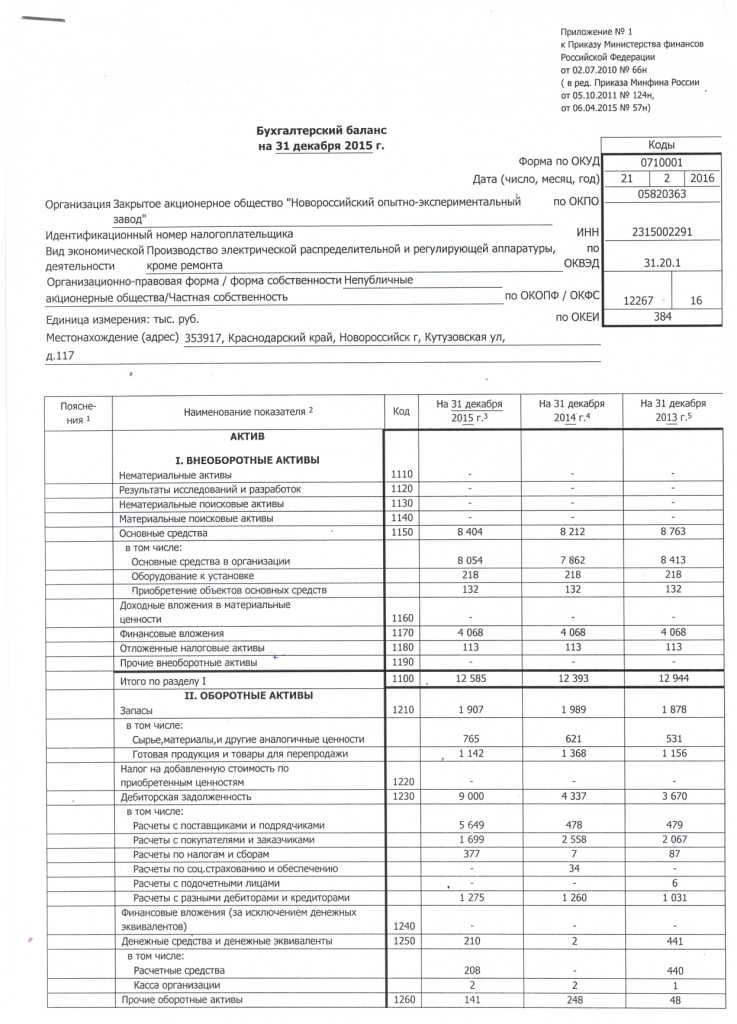
Ограничение количества подключений
В NGINX Plus можно ограничить количество активных подключений к вышестоящему серверу, указав максимальное количество с помощью параметра max_conns .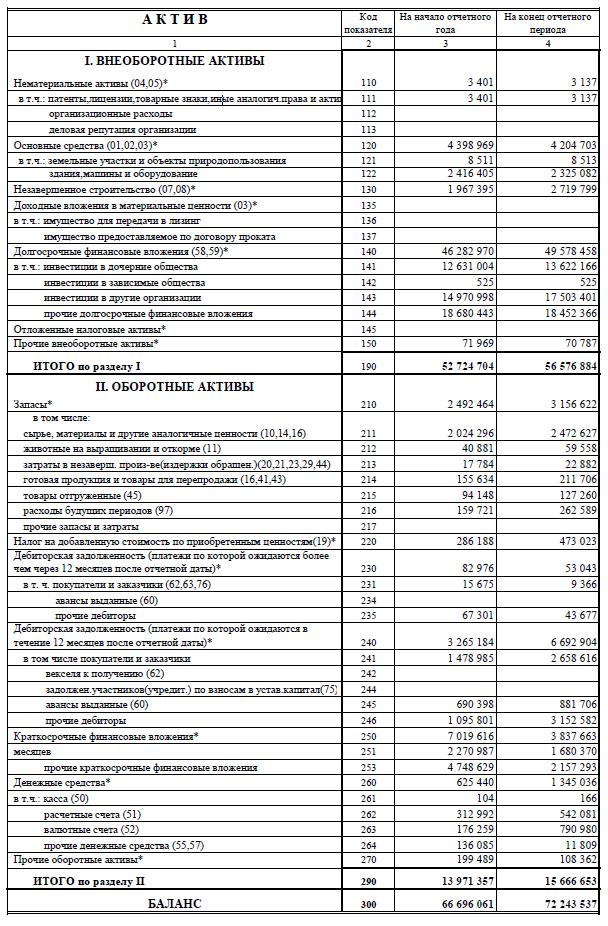
Если достигнут предел max_conns , запрос помещается в очередь для дальнейшей обработки при условии, что также включена директива queue для установки максимального количества запросов, которые могут одновременно находиться в очереди:
восходящий сервер {
серверная часть1.пример.com max_conns=3;
сервер backend2.example.com;
очередь 100 тайм-аут=70;
}
Если очередь заполнена запросами или вышестоящий сервер не может быть выбран в течение времени ожидания, указанного необязательным параметром timeout , клиент получает сообщение об ошибке.
Обратите внимание, что ограничение max_conns игнорируется, если в других рабочих процессах открыты незанятые keepalive соединения. В результате общее количество подключений к серверу может превысить значение max_conns в конфигурации, в которой память совместно используется несколькими рабочими процессами.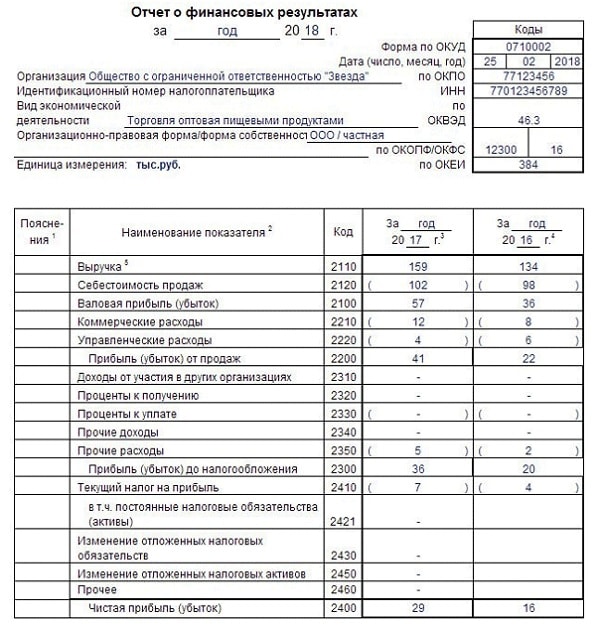
Настройка проверок работоспособности
NGINX может постоянно тестировать вышестоящие HTTP-серверы, избегать отказавших серверов и корректно добавлять восстановленные серверы в группу с балансировкой нагрузки.
Инструкции по настройке проверки работоспособности для HTTP см. в разделе Проверка работоспособности HTTP.
Совместное использование данных с несколькими рабочими процессами
Если вышестоящий блок не включает директиву зоны , каждый рабочий процесс сохраняет свою собственную копию конфигурации группы серверов и собственный набор связанных счетчиков.Счетчики включают текущее количество подключений к каждому серверу в группе и количество неудачных попыток передать запрос на сервер. В результате конфигурация группы серверов не может быть изменена динамически.
Если директива зоны включена в блок восходящего потока , конфигурация группы восходящего потока хранится в области памяти, совместно используемой всеми рабочими процессами.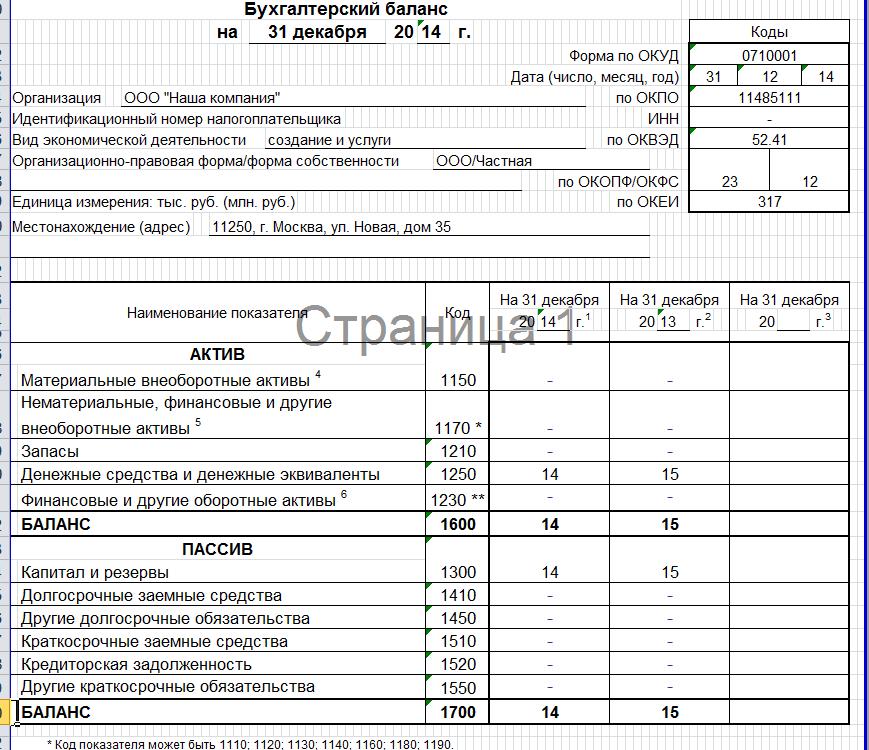 Этот сценарий динамически настраивается, поскольку рабочие процессы получают доступ к одной и той же копии конфигурации группы и используют одни и те же связанные счетчики.
Этот сценарий динамически настраивается, поскольку рабочие процессы получают доступ к одной и той же копии конфигурации группы и используют одни и те же связанные счетчики.
Директива зоны является обязательной для активных проверок работоспособности и динамической реконфигурации вышестоящей группы. Однако другие функции вышестоящих групп также могут выиграть от использования этой директивы.
Например, если конфигурация группы не используется совместно, каждый рабочий процесс ведет собственный счетчик неудачных попыток передать запрос на сервер (устанавливается параметром max_fails). В этом случае каждый запрос попадает только к одному рабочему процессу. Когда рабочий процесс, выбранный для обработки запроса, не может передать запрос на сервер, другие рабочие процессы ничего об этом не знают.В то время как некоторые рабочие процессы могут считать сервер недоступным, другие могут по-прежнему отправлять запросы на этот сервер. Чтобы сервер окончательно считался недоступным, количество неудачных попыток за время, заданное параметром fail_timeout , должно равняться max_fails , умноженному на количество рабочих процессов. С другой стороны, директива
С другой стороны, директива зоны гарантирует ожидаемое поведение.
Точно так же метод балансировки нагрузки с наименьшими подключениями может не работать должным образом без директивы зоны , по крайней мере, при низкой нагрузке.Этот метод передает запрос на сервер с наименьшим количеством активных подключений. Если конфигурация группы не используется совместно, каждый рабочий процесс использует собственный счетчик количества подключений и может отправить запрос на тот же сервер, на который только что отправил запрос другой рабочий процесс. Однако вы можете увеличить количество запросов, чтобы уменьшить этот эффект. При высокой нагрузке запросы распределяются между рабочими процессами равномерно, и метод Least Connections работает как положено.
Установка размера зоны
Невозможно порекомендовать идеальный размер зоны памяти, поскольку модели использования сильно различаются. Требуемый объем памяти определяется тем, какие функции (такие как сохранение сеанса, проверки работоспособности или повторное разрешение DNS) включены, а также тем, как идентифицируются вышестоящие серверы.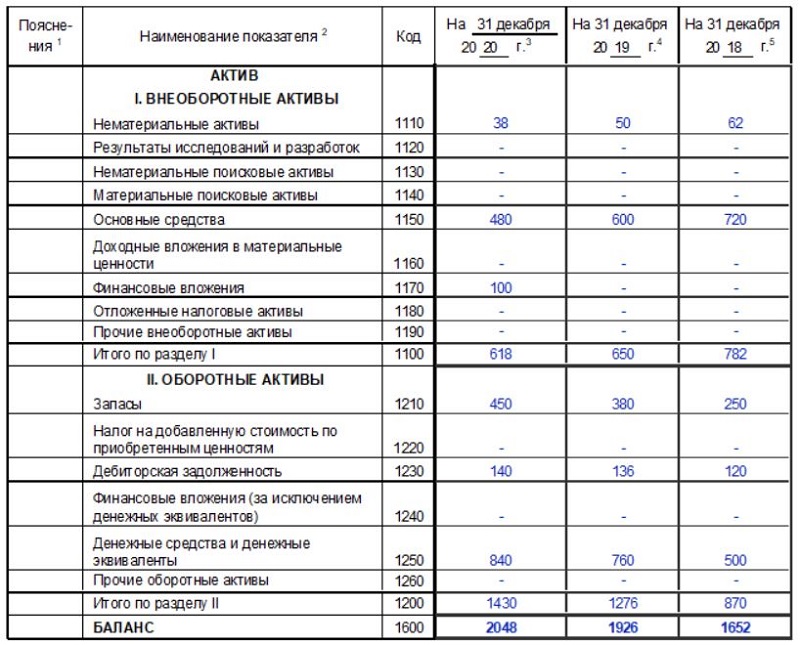
Например, при использовании метода сохраняемости сеанса sticky_route и включенной одиночной проверки работоспособности зона размером 256 КБ может вместить информацию об указанном количестве вышестоящих серверов:
- 128 серверов (каждый определяется как пара IP-адрес:порт)
- 88 серверов (каждый определяется как пара имя хоста:порт, где имя хоста разрешается в один IP-адрес)
- 12 серверов (каждый определяется как пара имя хоста:порт, где имя хоста разрешается в несколько IP-адресов)
Настройка балансировки нагрузки HTTP с использованием DNS
Конфигурацию группы серверов можно изменить во время выполнения с помощью DNS.
Для серверов в вышестоящей группе, которые идентифицируются доменным именем в директиве server , NGINX Plus может отслеживать изменения в списке IP-адресов в соответствующей записи DNS и автоматически применять изменения к балансировке нагрузки для вышестоящей группы. , не требуя перезагрузки. Это можно сделать, включив директиву
, не требуя перезагрузки. Это можно сделать, включив директиву resolver в блок http вместе с параметром resolve в директиву server :
http {
резольвер 10.0.0.1 действительный=300 с ipv6=выкл.;
резолвер_таймаут 10 с;
сервер {
место расположения / {
прокси_пасс http://бэкэнд;
}
}
восходящий сервер {
бэкенд зоны 32k;
наименьшее_соединение;
# ...
сервер backend1.example.com разрешает;
сервер backend2.example.com разрешает;
}
}
В этом примере параметр Resolve для директивы server указывает NGINX Plus периодически повторно разрешать backend1.example.com и backend2.example.com доменных имен в IP-адреса.
Директива распознавателя определяет IP-адрес DNS-сервера, на который NGINX Plus отправляет запросы (здесь 10. ). По умолчанию NGINX Plus повторно разрешает записи DNS с частотой, заданной временем жизни (TTL) в записи, но вы можете переопределить значение TTL с помощью допустимого параметра  0.0.1
0.0.1 ; в примере это 300 секунды или 5 минуты.
Необязательный параметр ipv6=off означает, что для балансировки нагрузки используются только адреса IPv4, хотя по умолчанию поддерживается разрешение как адресов IPv4, так и IPv6.
Если доменное имя разрешается в несколько IP-адресов, адреса сохраняются в вышестоящей конфигурации и распределяются по нагрузке. В нашем примере нагрузка на серверы распределяется по методу балансировки нагрузки с наименьшим количеством подключений. Если список IP-адресов для сервера изменился, NGINX Plus немедленно начинает балансировку нагрузки по новому набору адресов.
Балансировка нагрузки серверов Microsoft Exchange
В NGINX Plus R7 и более поздних версиях NGINX Plus может проксировать трафик Microsoft Exchange на сервер или группу серверов и балансировать нагрузку.
Для настройки балансировки нагрузки серверов Microsoft Exchange:
В блоке
locationнастройте прокси для вышестоящей группы серверов Microsoft Exchange с директивойproxy_pass:местоположение / { прокси_пасс https://exchange; # ... }Чтобы соединения Microsoft Exchange проходили на вышестоящие серверы, в блоке
locationустановите для директивыproxy_http_versionзначение1.1, а для директивыproxy_set_header— значениеConnection "", как и для keepalive подключение:местоположение / { # ... прокси_http_версия 1.1; proxy_set_header Соединение ""; # ... }В блоке
httpнастройте восходящую группу серверов Microsoft Exchange с восходящим блокомproxy_passна шаге 1. Затем укажите директиву ntlm, чтобы разрешить серверам в группе принимать запросы с аутентификацией NTLM:http { # ... восходящий обмен { зона обмена 64k; нтлм; # ... } }Добавьте серверы Microsoft Exchange в вышестоящую группу и при необходимости укажите метод балансировки нагрузки:
http { # ... восходящий обмен { зона обмена 64k; нтлм; обмен серверами1.пример.com; сервер exchange2.example.com; # ... } }
 Затем укажите директиву
Затем укажите директиву Полный пример NTLM
http {
# ...
восходящий обмен {
зона обмена 64k;
нтлм;
сервер exchange1.example.com;
сервер exchange2.example.com;
}
сервер {
слушать 443 ssl;
ssl_certificate /etc/nginx/ssl/company.com.crt;
ssl_certificate_key /etc/nginx/ssl/company. com.key;
ssl_протоколы TLSv1 TLSv1.1 TLSv1.2;
место расположения / {
прокси_пасс https://exchange;
прокси_http_версия 1.1;
proxy_set_header Соединение "";
}
}
}
 com.key;
ssl_протоколы TLSv1 TLSv1.1 TLSv1.2;
место расположения / {
прокси_пасс https://exchange;
прокси_http_версия 1.1;
proxy_set_header Соединение "";
}
}
}
com.key;
ssl_протоколы TLSv1 TLSv1.1 TLSv1.2;
место расположения / {
прокси_пасс https://exchange;
прокси_http_версия 1.1;
proxy_set_header Соединение "";
}
}
}
Дополнительные сведения о настройке Microsoft Exchange и NGINX Plus см. в руководстве по развертыванию балансировки нагрузки серверов Microsoft Exchange с NGINX Plus.
Динамическая конфигурация с использованием API NGINX Plus
В NGINX Plus конфигурация группы вышестоящих серверов может динамически изменяться с помощью API NGINX Plus.Команду конфигурации можно использовать для просмотра всех серверов или определенного сервера в группе, изменения параметра для определенного сервера и добавления или удаления серверов. Дополнительные сведения и инструкции см. в разделе Настройка динамической балансировки нагрузки с помощью API NGINX Plus.
Использование nginx в качестве балансировщика нагрузки HTTP
Использование nginx в качестве балансировщика нагрузки HTTP
Введение
Балансировка нагрузки между несколькими экземплярами приложений является широко используемой
метод оптимизации использования ресурсов, максимизация пропускной способности,
сокращение задержки и обеспечение отказоустойчивых конфигураций.
Можно использовать nginx как очень эффективный балансировщик нагрузки HTTP для распределить трафик на несколько серверов приложений и улучшить производительность, масштабируемость и надежность веб-приложений с nginx.
Методы балансировки нагрузки
Следующие механизмы (или методы) балансировки нагрузки поддерживаются в нгинкс:
- round-robin — запросы к серверам приложений распределяются круговым способом,
- наименее подключенный — следующий запрос назначается серверу с наименьшее количество активных подключений,
- ip-hash — хэш-функция используется для определения того, какой сервер должен быть выбранным для следующего запроса (на основе IP-адреса клиента).
Конфигурация балансировки нагрузки по умолчанию
Простейшая конфигурация для балансировки нагрузки с помощью nginx может выглядеть как следующее:
http {
вверх по течению myapp1 {
сервер srv1.example.com;
сервер srv2. example.com;
сервер srv3.example.com;
}
сервер {
слушать 80;
место расположения / {
прокси_пасс http://myapp1;
}
}
}
 example.com;
сервер srv3.example.com;
}
сервер {
слушать 80;
место расположения / {
прокси_пасс http://myapp1;
}
}
}
example.com;
сервер srv3.example.com;
}
сервер {
слушать 80;
место расположения / {
прокси_пасс http://myapp1;
}
}
}
В приведенном выше примере есть 3 экземпляра одного и того же приложения. работает на srv1-srv3.Если метод балансировки нагрузки специально не настроен, по умолчанию используется циклический алгоритм. Все запросы проксируется на группу серверов myapp1, а nginx применяет HTTP-загрузку балансировка для распределения запросов.
Реализация обратного прокси в nginx включает балансировку нагрузки для HTTP, HTTPS, FastCGI, uwsgi, SCGI, memcached и gRPC.
Чтобы настроить балансировку нагрузки для HTTPS вместо HTTP, просто используйте «https». как протокол.
При настройке балансировки нагрузки для FastCGI, uwsgi, SCGI, memcached или gRPC используйте fastcgi_pass, uwsgi_pass, scgi_pass, memcached_pass и grpc_pass директивы соответственно.
Балансировка нагрузки с наименьшим количеством подключений
Еще одна дисциплина балансировки нагрузки — наименее подключенная. Наименее подключенный позволяет контролировать нагрузку на приложение
случаев более справедливо в ситуации, когда часть запросов
потребуется больше времени для завершения.
Наименее подключенный позволяет контролировать нагрузку на приложение
случаев более справедливо в ситуации, когда часть запросов
потребуется больше времени для завершения.
При балансировке нагрузки с наименьшим количеством подключений nginx постарается не перегружать загруженный сервер приложений с чрезмерными запросами, раздающими новые вместо этого запросы к менее загруженному серверу.
Балансировка нагрузки по наименьшему количеству подключений в nginx активируется, когда Директива less_conn используется как часть конфигурации группы серверов:
вверх по течению myapp1 {
наименьшее_соединение;
сервер срв1.пример.com;
сервер srv2.example.com;
сервер srv3.example.com;
}
Постоянство сеанса
Обратите внимание, что при циклическом переборе или нагрузке с наименьшим количеством подключений
балансировка, каждый последующий запрос клиента может быть потенциально
распространяется на другой сервер. Нет гарантии, что один и тот же клиент будет всегда
направлены на тот же сервер.
Нет гарантии, что один и тот же клиент будет всегда
направлены на тот же сервер.
Если есть необходимость привязать клиента к конкретному серверу приложений — другими словами, сделать сеанс клиента «липким» или «постоянным» в условия всегда пытаются выбрать конкретный сервер — нагрузка IP-хэша можно использовать уравновешивающий механизм.
С ip-hash IP-адрес клиента используется в качестве ключа хеширования для определить, какой сервер в группе серверов должен быть выбран для запросы клиента. Этот метод гарантирует, что запросы от одного и того же клиента всегда будет направлен на один и тот же сервер за исключением случаев, когда этот сервер недоступен.
Для настройки балансировки нагрузки ip-hash достаточно добавить ip_hash директива для конфигурации группы серверов (upstream):
вверх по течению myapp1 {
ip_хэш;
сервер срв1.пример.com;
сервер srv2.example.com;
сервер srv3.example.com;
}
Взвешенная балансировка нагрузки
Также возможно влиять на алгоритмы балансировки нагрузки nginx даже
далее с помощью серверных весов.
В приведенных выше примерах вес сервера не настроен, что означает что все указанные серверы рассматриваются как одинаково квалифицированные для определенный метод балансировки нагрузки.
В частности, при круговой системе это также означает более или менее равные распределение запросов по серверам — при условии, что их достаточно запросы, и когда запросы обрабатываются единообразно и завершено достаточно быстро.
Когда масса параметр указан для сервера, вес учитывается как часть решения о балансировке нагрузки.
вверх по течению myapp1 {
сервер srv1.example.com вес=3;
сервер srv2.example.com;
сервер srv3.example.com;
}
При такой конфигурации каждые 5 новых запросов будут распределяться по экземпляры приложения следующим образом: 3 запроса будут направлены к srv1, один запрос пойдет к srv2, а другой — к srv3.
Аналогично можно использовать веса с наименее связным и
балансировка нагрузки ip-hash в последних версиях nginx.
Медицинские осмотры
Реализация обратного прокси в nginx включает внутриполосный (или пассивный) проверки работоспособности сервера. Если ответ от определенного сервера завершается с ошибкой, nginx пометит этот сервер как неисправный и попытается временно не выбирайте этот сервер для последующих входящих запросов.
То max_fails директива устанавливает количество последовательных неудачных попыток общаться с сервером, что должно произойти во время сбой_тайм-аут.По умолчанию, max_fails устанавливается на 1. Если установлено значение 0, проверки работоспособности для этого сервера отключены. То fail_timeout Параметр также определяет, как долго сервер будет помечен как неисправный. После fail_timeout интервал после сбоя сервера, nginx начнет изящно зондировать сервер с запросами живого клиента. Если зонды прошли успешно, сервер помечается как работающий.
Дальнейшее чтение
Кроме того, есть больше директив и параметров, управляющих сервером.
балансировка нагрузки в nginx, т. е.г.
proxy_next_upstream,
резервный,
вниз, и
поддерживать активность.
Для получения дополнительной информации, пожалуйста, проверьте наш
справочная документация.
е.г.
proxy_next_upstream,
резервный,
вниз, и
поддерживать активность.
Для получения дополнительной информации, пожалуйста, проверьте наш
справочная документация.
Последний, но тем не менее важный, балансировка нагрузки приложений, проверка работоспособности приложений, мониторинг активности и доступна оперативная перенастройка групп серверов в рамках наших платных подписок NGINX Plus.
В следующих статьях описывается балансировка нагрузки с помощью NGINX Plus. Подробнее:
Внешний обзор балансировки нагрузки HTTP(S) | Облако Google
В этом документе представлены концепции, которые необходимо понимать для настройки Внешняя балансировка нагрузки HTTP(S) Google Cloud.
Внешняя балансировка нагрузки HTTP(S) — это нагрузка уровня 7 на основе прокси-сервера.
балансировщик, который позволяет вам запускать и масштабировать свои службы за
один внешний IP-адрес. Распределение внешней балансировки нагрузки HTTP(S)
Трафик HTTP и HTTPS к бэкэндам, размещенным в различных облаках Google. платформах (таких как Compute Engine, Google Kubernetes Engine (GKE),
облачное хранилище и т. д.), а также внешние серверные части, подключенные через
через Интернет или через гибридное соединение.
Дополнительные сведения см. в разделе Варианты использования.
платформах (таких как Compute Engine, Google Kubernetes Engine (GKE),
облачное хранилище и т. д.), а также внешние серверные части, подключенные через
через Интернет или через гибридное соединение.
Дополнительные сведения см. в разделе Варианты использования.
Режимы работы
Вы можете настроить внешнюю балансировку нагрузки HTTP(S) в следующих режимах:
- Глобальный внешний балансировщик нагрузки HTTP(S). Это глобальная загрузка балансировщик, реализованный как управляемая служба в Google Front Ends (ГФЭ). Это использует Envoy с открытым исходным кодом прокси для поддержки расширенные возможности управления трафиком, такие как зеркалирование трафика, разделение трафика на основе веса, преобразования заголовков на основе запроса/ответа, и больше. Этот балансировщик нагрузки в настоящее время находится в Предварительный просмотр .
- Глобальный внешний балансировщик нагрузки HTTP(S) (классический). Это классический внешний балансировщик нагрузки HTTP(S), который
является глобальным в Premium Tier, но может быть настроен как региональный в Standard
Уровень.Этот балансировщик нагрузки реализован на Google Front Ends.
(ГФЭ). GFE являются
распределены по всему миру и работают вместе, используя глобальную сеть Google и
плоскость управления.
- Региональный внешний балансировщик нагрузки HTTP(S). Это региональная загрузка балансировщик, который реализован как управляемая служба на Envoy с открытым исходным кодом прокси. Это включает в себя расширенные возможности управления трафиком, такие как зеркалирование трафика, разделение трафика на основе веса, преобразования заголовков на основе запроса/ответа, и больше.Этот балансировщик нагрузки в настоящее время находится в Предварительный просмотр .
 Это классический внешний балансировщик нагрузки HTTP(S), который
является глобальным в Premium Tier, но может быть настроен как региональный в Standard
Уровень.Этот балансировщик нагрузки реализован на Google Front Ends.
(ГФЭ). GFE являются
распределены по всему миру и работают вместе, используя глобальную сеть Google и
плоскость управления.
Это классический внешний балансировщик нагрузки HTTP(S), который
является глобальным в Premium Tier, но может быть настроен как региональный в Standard
Уровень.Этот балансировщик нагрузки реализован на Google Front Ends.
(ГФЭ). GFE являются
распределены по всему миру и работают вместе, используя глобальную сеть Google и
плоскость управления.| Режим балансировки нагрузки | Рекомендуемые варианты использования | Возможности |
|---|---|---|
| Глобальный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | Используйте этот балансировщик нагрузки для внешних рабочих нагрузок HTTP(S) с
глобально рассредоточенные пользователи или серверные службы в нескольких регионах. | |
| Глобальный внешний балансировщик нагрузки HTTP(S) (классический) | Этот балансировщик нагрузки является глобальным на уровне Premium, но его можно настроить быть эффективным регионом на уровне Standard. В службе Premium Network уровень, этот балансировщик нагрузки предлагает балансировку нагрузки в нескольких регионах, направление трафика на ближайший работоспособный сервер который имеет пропускную способность и терминирует HTTP(S)-трафик как можно ближе возможно для ваших пользователей. В стандартной сети Уровень обслуживания, балансировка нагрузки осуществляется на региональном уровне. |
 |
| Региональный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | Этот балансировщик нагрузки содержит многие функции существующий глобальный внешний балансировщик нагрузки HTTP(S) (классический), наряду с дополнительными расширенными возможностями управления трафиком. Используйте этот балансировщик нагрузки, если вы хотите обслуживать контент из только одна геолокация (например, для соблюдения нормативных требований) или если стандарт Уровень сетевых служб желателен. | Полный список см. в разделе Загрузка. особенности балансировки. |
Идентификация режима
Чтобы определить режим балансировщика нагрузки, выполните следующую команду:
Правила переадресации вычислений gcloud описывают FORWARDING_RULE_NAME
В выводе команды проверьте схему балансировки нагрузки, регион и сеть
уровень. В следующей таблице показано, как определить режим нагрузки.
балансир.
В следующей таблице показано, как определить режим нагрузки.
балансир.
| Режим балансировки нагрузки | Схема балансировки нагрузки | Правило переадресации | Сетевой уровень |
|---|---|---|---|
| Глобальный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | ВНЕШНЕЕ_УПРАВЛЯЕМОЕ | Глобальный | ПРЕМИУМ |
| Глобальный внешний балансировщик нагрузки HTTP(S) (классический) | ВНЕШНИЙ | Глобальный | СТАНДАРТ или ПРЕМИУМ |
| Региональный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | ВНЕШНЕЕ_УПРАВЛЯЕМОЕ | Задает регион | СТАНДАРТ |
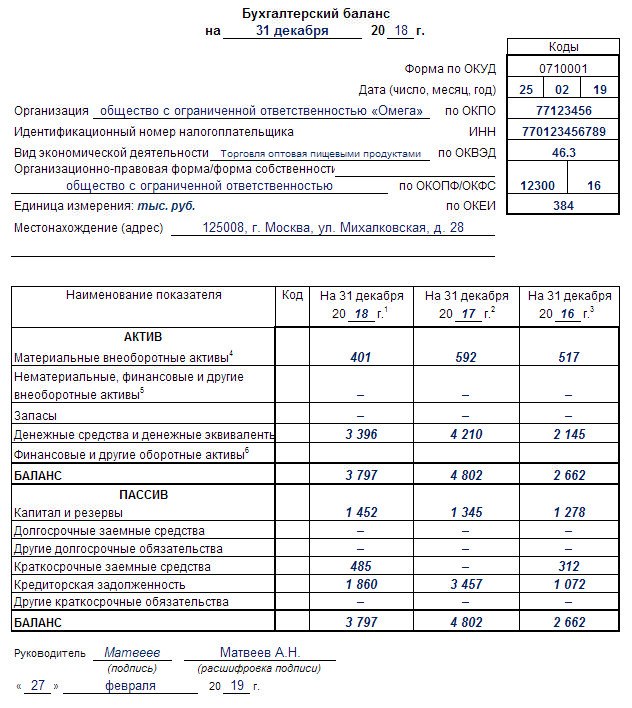 Вместо,
необходимо удалить балансировщик нагрузки и создать новый.
Вместо,
необходимо удалить балансировщик нагрузки и создать новый.Архитектура
Следующие ресурсы необходимы для балансировки нагрузки HTTP(S) развертывание:
Только для региональных внешних балансировщиков нагрузки HTTP(S) , только прокси-сервер подсеть используется для отправлять соединения от балансировщика нагрузки к бэкендам.
Внешнее правило переадресации указывает внешний IP-адрес, порт, и целевой HTTP(S) прокси.Клиенты используют IP-адрес и порт для подключиться к балансировщику нагрузки.
Целевой прокси-сервер HTTP(S) получает запрос от клиент. То Прокси-сервер HTTP (S) оценивает запрос, используя карту URL-адресов для создания трафика. маршрутные решения. Прокси-сервер также может аутентифицировать связь с использованием SSL-сертификатов.
- Для балансировки нагрузки HTTPS целевой прокси-сервер HTTPS использует SSL-сертификатов для подтверждения своей личности
клиенты. Целевой прокси-сервер HTTPS поддерживает документированные
номер
SSL-сертификатов.
- Для балансировки нагрузки HTTPS целевой прокси-сервер HTTPS использует SSL-сертификатов для подтверждения своей личности
клиенты.
Прокси-сервер HTTP(S) использует карту URL-адресов для маршрутизации определение на основе атрибутов HTTP (таких как путь запроса, файлы cookie или заголовки). В зависимости от решения о маршрутизации прокси-сервер перенаправляет запросы клиентов на определенные серверные службы или серверные сегменты. Карта URL может указывать дополнительные действия, такие как отправка перенаправлений клиентам.
Серверная служба распределяет запросы на работоспособные бэкенды. То глобальные внешние балансировщики нагрузки HTTP(S) также поддерживают внутренних сегментов .
- Один или несколько серверных модулей должны быть подключены к серверному сервису или внутреннее ведро.
Проверка работоспособности периодически контролирует готовность ваш бэкенды.
Это снижает риск того, что запросы могут быть отправлены на серверы, которые
не может обслужить запрос.Правила брандмауэра для ваших серверных частей, чтобы принять работоспособность проверить зонды. Для региональных внешних балансировщиков нагрузки HTTP(S) требуется дополнительное правило брандмауэра. разрешить трафику из подсети только для прокси-серверов достигать серверных частей.
 Целевой прокси-сервер HTTPS поддерживает документированные
номер
SSL-сертификатов.
Целевой прокси-сервер HTTPS поддерживает документированные
номер
SSL-сертификатов. Это снижает риск того, что запросы могут быть отправлены на серверы, которые
не может обслужить запрос.
Это снижает риск того, что запросы могут быть отправлены на серверы, которые
не может обслужить запрос.Global
На этой схеме показаны компоненты глобального внешнего балансировщика нагрузки HTTP(S) развертывание. Эта архитектура применима как к глобальному внешнему балансировщику нагрузки HTTP(S) с расширенными возможностями управления трафиком, и глобальный внешний балансировщик нагрузки HTTP(S) (классический) на уровне Premium.
Компоненты глобального внешнего балансировщика нагрузки HTTP(S)Региональный
На этой схеме показаны компоненты регионального внешнего балансировщика нагрузки HTTP(S)
развертывание.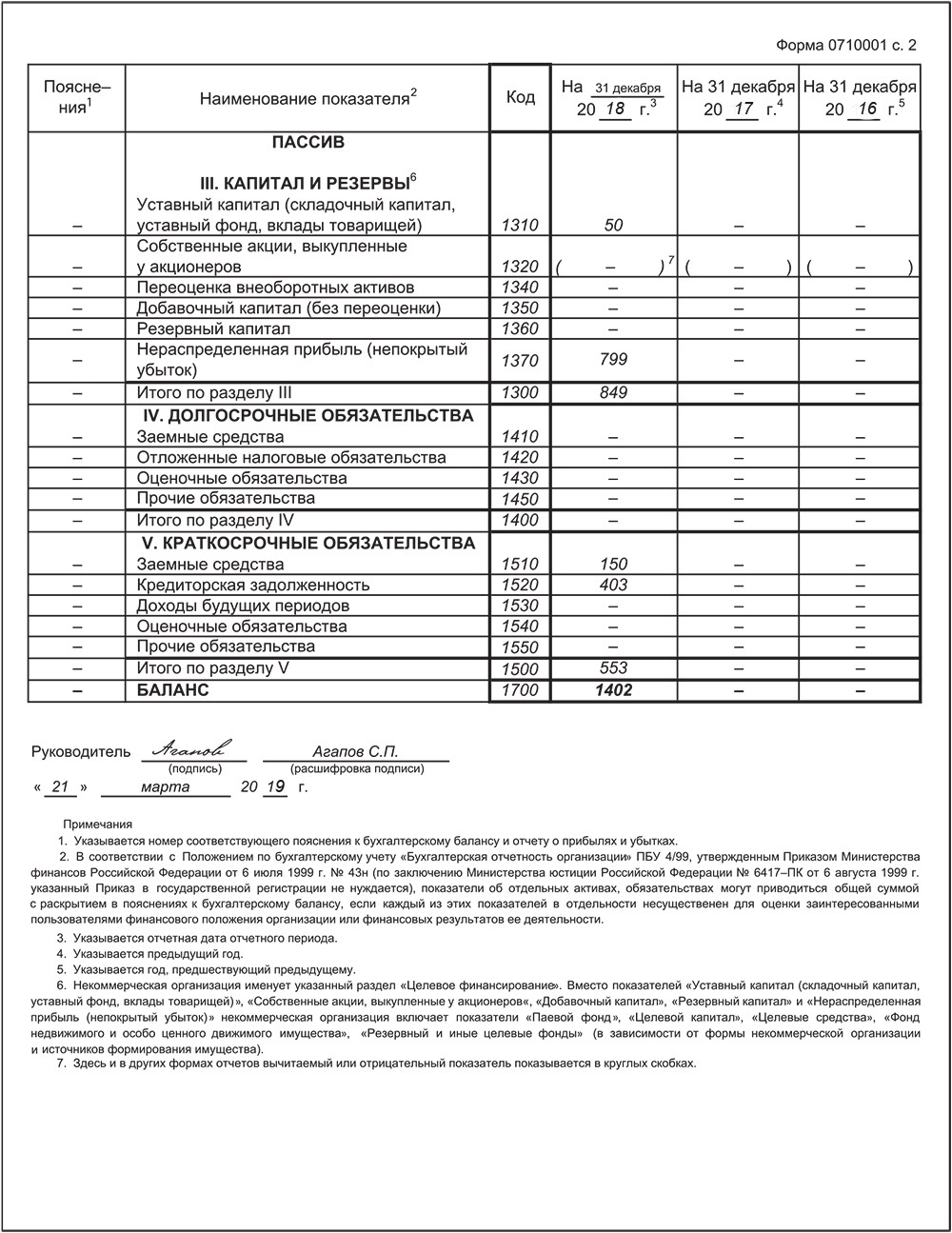
Подсеть только для прокси
Подсети только для прокси-сервера требуются только для региональных внешних балансировщиков нагрузки HTTP(S).
Подсеть только для прокси предоставляет набор IP-адресов
которые Google использует для запуска прокси-серверов Envoy от вашего имени. Вы должны создать один подсеть только для прокси в каждом регионе сети VPC, где вы используете
региональные внешние балансировщики нагрузки HTTP(S). Флаг --цель для этой подсети только для прокси-сервера
установлено значение REGIONAL_MANAGED_PROXY .Все региональные внешние балансировщики нагрузки HTTP(S) в одном
регион и сеть VPC совместно используют пул прокси-серверов Envoy из
та же подсеть только для прокси. Далее:
- Подсети только для прокси используются только для прокси-серверов Envoy, а не для ваших серверных частей.
- Серверные виртуальные машины или конечные точки всех региональных внешних балансировщиков нагрузки HTTP(S) в регионе и Сеть VPC получает подключения из подсети только для прокси.
- IP-адрес регионального внешнего балансировщика нагрузки HTTP(S) — , а не , расположенный в подсеть только для прокси.IP-адрес балансировщика нагрузки определяется его внешнее управляемое правило переадресации, описанное ниже.

--цель установлена на REGIONAL_MANAGED_PROXY ). В настоящее время только один прокси-сервер
подсеть может существовать в регионе сети VPC. Это означает, что
внутренние балансировщики нагрузки HTTP(S) и региональные внешние балансировщики нагрузки HTTP(S) совместно используют одну подсеть только для прокси-сервера в
тот же регион сети.Если у вас есть действующий INTERNAL_HTTPS_LOAD_BALANCER , вы можете изменить его назначение на REGIONAL_MANAGED_PROXY , если необходимо.
Правила пересылки и адреса
Правила переадресации направлять трафик по IP-адресу, порту и протоколу на балансировку нагрузки конфигурация, состоящая из целевого прокси, сопоставления URL-адресов и одного или нескольких серверных Сервисы.
Каждое правило переадресации предоставляет один IP-адрес, который можно использовать в записях DNS для вашего приложения. Балансировка нагрузки на основе DNS не требуется.Вы можете либо указать IP-адрес, который будет использоваться, либо позволить облачной балансировке нагрузки назначить один для вас.
- Правило переадресации для балансировщика нагрузки HTTP может ссылаться только на порты TCP 80 и 8080.
- Правило переадресации для балансировщика нагрузки HTTPS может ссылаться только на порт TCP 443.
Тип правила переадресации, IP-адрес и схема балансировки нагрузки, используемые
внешние балансировщики нагрузки HTTP(S) зависят от режима балансировщика нагрузки и того, какая сеть
Уровень обслуживания, на котором находится балансировщик нагрузки.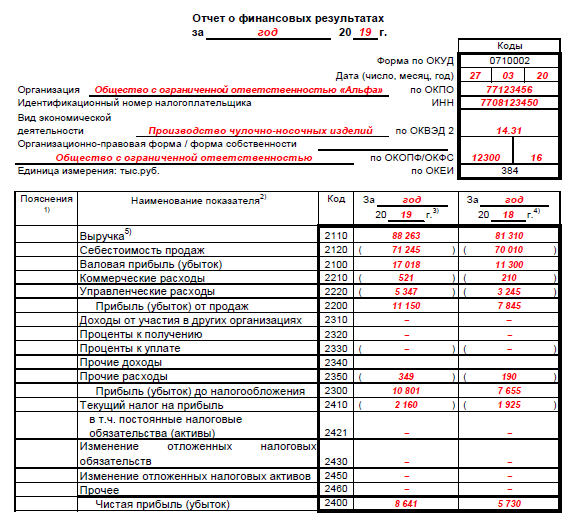
Полный список протоколов, поддерживаемых балансировкой нагрузки HTTP(S) правила переадресации в каждом режиме, см. Балансировщик нагрузки Особенности.
Целевые прокси
Целевые прокси завершают HTTP(S) подключения от клиентов. Одно или несколько правил переадресации трафик к целевому прокси-серверу, и целевой прокси-сервер сверяется с картой URL-адресов, чтобы определить, как направлять трафик на серверные части.
Не полагайтесь на прокси для сохранения регистра заголовка запроса или ответа
имена.Например, заголовок ответа Server: Apache/1.0 может появиться в
клиент как сервер : Apache/1.0 .
В следующей таблице указан тип целевого прокси-сервера, который требуется
Балансировка нагрузки HTTP(S) в каждом режиме.
| Режим балансировки нагрузки | Целевые типы прокси | Заголовки, добавленные прокси | Поддерживаются пользовательские заголовки | Облачная трассировка поддерживается |
|---|---|---|---|---|
| Глобальный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | Глобальный HTTP, Глобальный HTTPS | Прокси устанавливают заголовки HTTP-запроса/ответа следующим образом:
| Настроен на
серверная служба или серверная корзина Не поддерживается с облачной CDN | |
| Глобальный внешний балансировщик нагрузки HTTP(S) (классический) | Глобальный HTTP, Глобальный HTTPS | Прокси устанавливают заголовки HTTP-запроса/ответа следующим образом:
| Настроен на серверная служба или серверная часть | |
| Региональный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | Региональный HTTP, Региональный HTTPS |
|
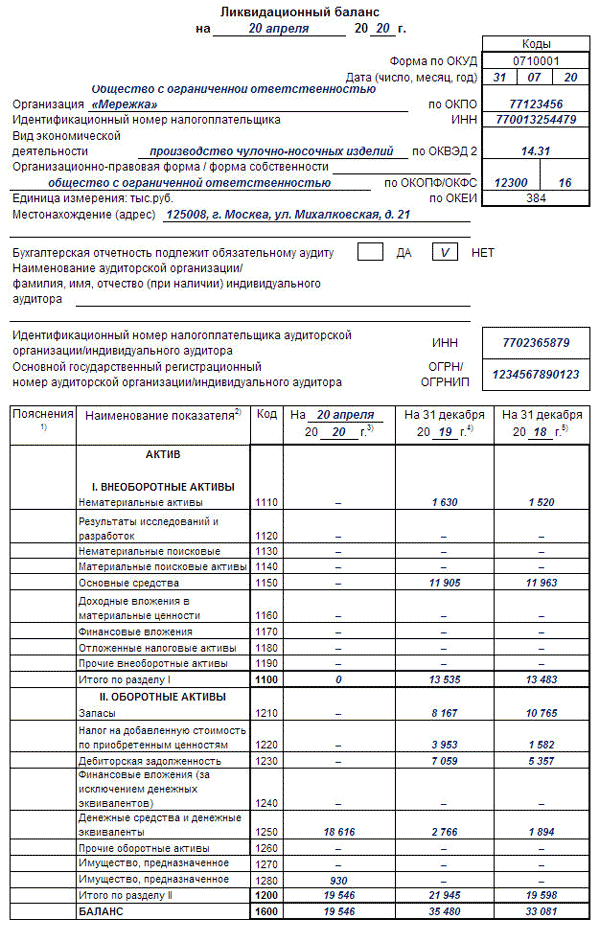 заголовок X-Forwarded-For) (только запросы)
заголовок X-Forwarded-For) (только запросы) заголовок X-Forwarded-For) (только запросы)
заголовок X-Forwarded-For) (только запросы)Когда балансировщик нагрузки делает HTTP-запрос, балансировщик нагрузки сохраняет Заголовок хоста исходного запроса.
Балансировщик нагрузки добавляет два IP-адреса, разделенные одной запятой, к Заголовок X-Forwarded-For в следующем порядке:
- IP-адрес клиента, который подключается к балансировщику нагрузки
- IP-адрес правила переадресации балансировщика нагрузки
Если во входящем запросе отсутствует заголовок X-Forwarded-For , эти
два IP-адреса — это полное значение заголовка:
X-Forwarded-For: ,
Если запрос включает заголовок X-Forwarded-For , балансировщик нагрузки сохраняет
предоставленное значение до :
X-Forwarded-For: <предоставленное значение>, ,
Внимание! Балансировщик нагрузки не проверяет IP-адреса, предшествующие , в этом заголовке. То
предшествующие IP-адреса могут содержать другие символы, включая пробелы.
То
предшествующие IP-адреса могут содержать другие символы, включая пробелы. При запуске программного обеспечения обратного прокси-сервера HTTP на серверных частях балансировщика нагрузки
программное обеспечение может добавить один или оба из следующих IP-адресов в конец
заголовок X-Forwarded-For :
IP-адрес внешнего интерфейса Google (GFE), подключенного к серверной части. Эти IP-адреса находятся в диапазонах
130.211.0.0/22 и35.191.0.0/16.IP-адрес самой серверной системы.
Таким образом, восходящий процесс после серверной части балансировщика нагрузки может получить X-Forwarded-For заголовок формы:
<существующие-значения>,,
Поддержка протоколов HTTP/3 и QUIC
HTTP/3 — это интернет-протокол нового поколения. Он построен на вершине
QUIC, а
протокол, разработанный на основе оригинального
Гугл QUIC) (
Он построен на вершине
QUIC, а
протокол, разработанный на основе оригинального
Гугл QUIC) ( gQUIC )
протокол.HTTP/3 поддерживается между внешним балансировщиком нагрузки HTTP(S), Cloud CDN и
клиенты.
В частности:
- IETF QUIC — это протокол транспортного уровня, обеспечивающий контроль перегрузки, аналогичный для TCP и является эквивалентом безопасности SSL/TLS для HTTP/2 с улучшенным представление.
- HTTP/3 — это прикладной уровень, созданный поверх IETF QUIC и основанный на QUIC. для управления мультиплексированием, контролем перегрузки и повторными попытками.
- HTTP/3 обеспечивает более быструю инициацию клиентского соединения, устраняет заголовки строк блокировку в мультиплексированных потоках и поддерживает миграцию соединения, когда меняется IP-адрес клиента.
- HTTP/3 влияет на соединения между клиентами и балансировщиком нагрузки, а не
соединения между балансировщиком нагрузки и его серверной частью.
- соединения HTTP/3 используют ББР протокол управления перегрузкой.
Включение HTTP/3 на вашем балансировщике нагрузки может улучшить время загрузки веб-страницы, уменьшить повторную буферизацию видео и повысить пропускную способность при соединениях с более высокой задержкой.
В следующей таблице указана поддержка HTTP/3 для балансировки нагрузки HTTP(S) в каждом режиме.
| Режим балансировки нагрузки | Поддержка HTTP/3 |
|---|---|
| Глобальный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | |
| Глобальный внешний балансировщик нагрузки HTTP(S) (классический) | |
| Региональный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) |
Настройка HTTP/3
Вы можете явно включить поддержку HTTP/3 для вашего балансировщика нагрузки,
установка quicOverride на ВКЛЮЧИТЬ .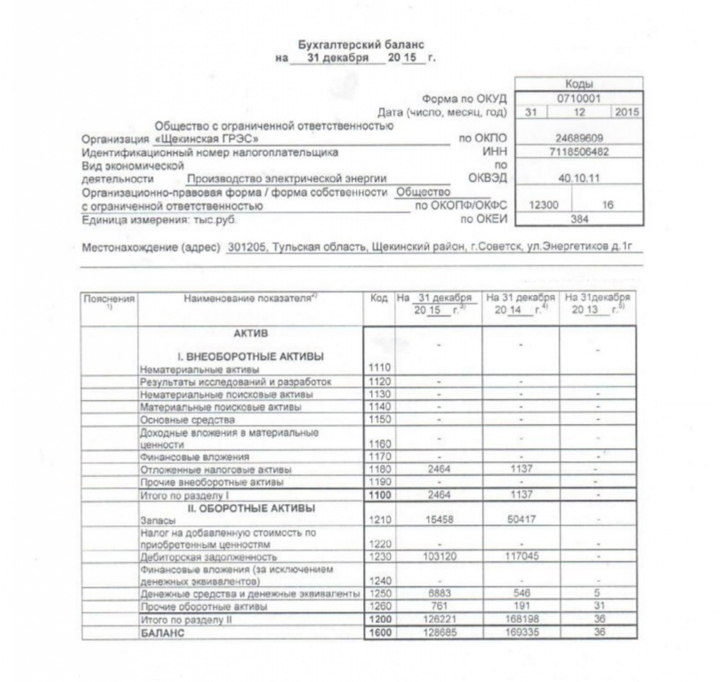
Клиенты, не поддерживающие HTTP/3 или gQUIC, не согласовывают HTTP/3 связь. Вам не нужно явно отключать HTTP/3, если у вас нет выявлены сломанные или старые реализации клиента.
Балансировка нагрузки HTTP(S) предоставляет три способа настройки HTTP/3, как показано на рисунке. в следующей таблице.
| значение quicOverride | Поведение |
|---|---|
НЕТ | HTTP/3 и Google QUIC не рекламируются клиентам. Важно! Это поведение меняется. Настройка по умолчанию quicOverride=NONE будет объявлять о поддержке HTTP/3
вашим клиентам. В настоящее время это изменение распространяется по всему миру. Если вы не хотите, чтобы это поведение менялось, вы можете отключить HTTP/3.
установив |
ВКЛЮЧИТЬ | Клиентам сообщается о поддержке HTTP/3 и Google QUIC.HTTP/3 есть рекламируется с более высоким приоритетом. Клиенты, поддерживающие оба протоколы должны предпочитать HTTP/3 Google QUIC. Примечание. TLS 0-RTT (также известный как TLS Early Data ) неявно поддерживается. когда клиент согласовывает Google QUIC, но в настоящее время это не поддерживается при использовании HTTP/3. |
ОТКЛЮЧИТЬ | Явно отключает рекламу HTTP/3 и Google QUIC для клиентов. |
Чтобы явно включить (или отключить) HTTP/3, выполните следующие действия.
Консоль: HTTPS
Примечание: Настройка согласования HTTP/3 в настоящее время не поддерживается на цели прокси и должны быть настроены путем редактирования конфигурации балансировщика нагрузки.
В Google Cloud Console перейдите на страницу Балансировка нагрузки .
Перейти к балансировке нагрузки
Выберите балансировщик нагрузки, который вы хотите изменить.
Нажмите Конфигурация внешнего интерфейса .
Выберите внешний IP-адрес и порт, которые вы хотите изменить. Для редактирования HTTP/3 конфигурации IP-адрес и порт должны быть HTTPS (порт 443).
Включить HTTP/3
- Выберите раскрывающийся список Согласование QUIC .
- Чтобы явно включить HTTP/3 для этого внешнего интерфейса, выберите Enabled .
- Если у вас есть несколько правил внешнего интерфейса, представляющих IPv4 и IPv6, убедитесь, что чтобы включить HTTP/3 для каждого правила.
Отключить HTTP/3
- Выберите раскрывающийся список Согласование QUIC .
- Чтобы явно отключить HTTP/3 для этого внешнего интерфейса, выберите Отключено .
- Если у вас есть несколько правил внешнего интерфейса, представляющих IPv4 и IPv6, убедитесь, что чтобы отключить HTTP/3 для каждого правила.

gcloud: HTTPS
Перед выполнением этой команды необходимо создать ресурс сертификата SSL для каждого сертификата.
gcloud вычислить цель-https-прокси создать HTTPS_PROXY_NAME \
--Глобальный \
--quic-override= QUIC_SETTING
Замените QUIC_SETTING одним из следующих:
НЕТ(по умолчанию): позволяет Google управлять согласованием QUICВ настоящее время при выборе
NONEQUIC отключается.От выбирая эту опцию, вы разрешаете Google автоматически включать Согласование QUIC и HTTP/3 в будущем для этого балансировщика нагрузки. В Cloud Console этот параметр называется Automatic.
(по умолчанию) .ВКЛЮЧИТЬ: объявляет HTTP/3 и Google QUIC клиентамОТКЛЮЧИТЬ: не рекламировать HTTP/3 или Google QUIC клиентам
API: HTTPS
ОТПРАВИТЬ https://www.googleapis.com/v1/compute/projects/ PROJECT_ID /global/targetHttpsProxies/ TARGET_PROXY_NAME /setQuicOverride
{
"quicOverride": QUIC_SETTING
}
Замените QUIC_SETTING одним из следующих:
НЕТ(по умолчанию): позволяет Google управлять согласованием QUICВ настоящее время при выборе
NONEQUIC отключается. От
выбирая эту опцию, вы разрешаете Google автоматически включать
Согласование QUIC и HTTP/3 в будущем для этого балансировщика нагрузки.В Cloud Console этот параметр называется Automatic.
(по умолчанию) .ВКЛЮЧИТЬ: объявляет HTTP/3 и Google QUIC клиентамОТКЛЮЧИТЬ: не рекламировать HTTP/3 или Google QUIC клиентам
 От
выбирая эту опцию, вы разрешаете Google автоматически включать
Согласование QUIC и HTTP/3 в будущем для этого балансировщика нагрузки.В Cloud Console этот параметр называется Automatic.
(по умолчанию) .
От
выбирая эту опцию, вы разрешаете Google автоматически включать
Согласование QUIC и HTTP/3 в будущем для этого балансировщика нагрузки.В Cloud Console этот параметр называется Automatic.
(по умолчанию) .Как согласовывается HTTP/3
Когда HTTP/3 включен, балансировщик нагрузки сообщает об этой поддержке клиентам, разрешение клиентам, поддерживающим HTTP/3, пытаться установить соединения HTTP/3 с балансировщиком нагрузки HTTPS.
- Правильно реализованные клиенты всегда возвращаются к HTTPS или HTTP/2, когда они не удается установить соединение QUIC.
- Клиенты, поддерживающие HTTP/3, используют свои кэшированные предварительные знания о поддержке HTTP/3. чтобы избежать ненужных обращений в оба конца в будущем.
- Из-за этого отката включение или отключение QUIC в балансировщике нагрузки не не нарушать способность балансировщика нагрузки подключаться к клиентам.
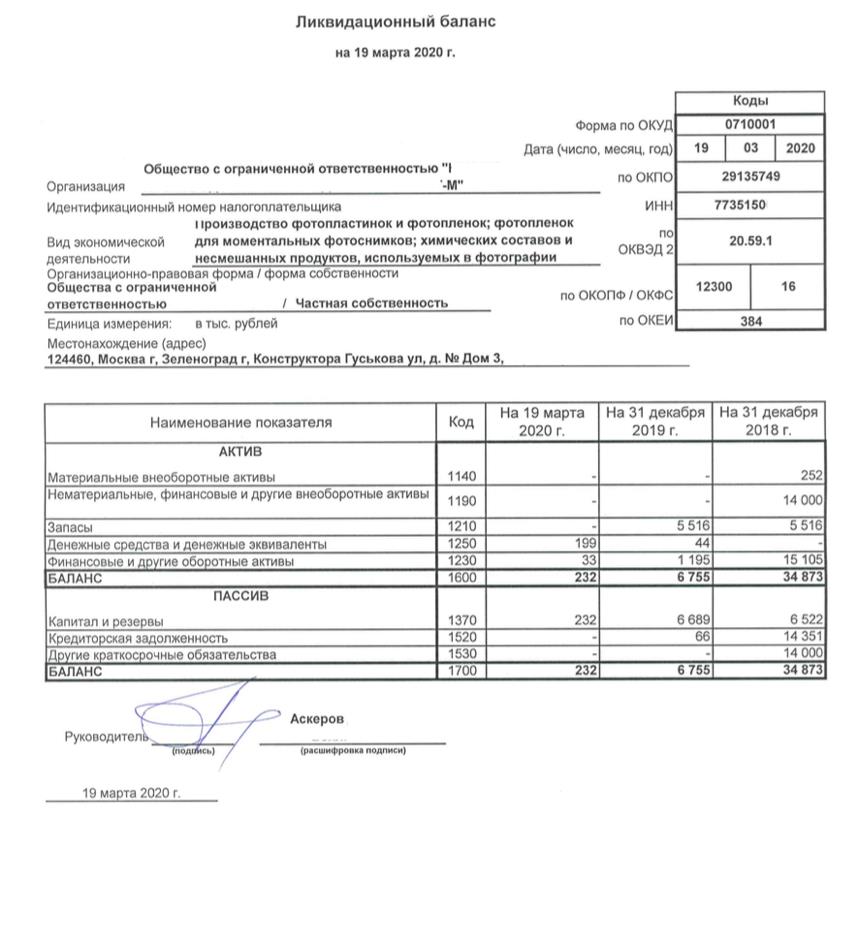 чтобы избежать ненужных обращений в оба конца в будущем.
чтобы избежать ненужных обращений в оба конца в будущем. Поддержка рекламируется в Альт-Svc Заголовок HTTP-ответа.Когда HTTP/3 настроен как ENABLE на
ресурс targetHttpsProxy внешнего балансировщика нагрузки HTTP(S), ответы от
балансировщик нагрузки включает следующее значение заголовка alt-svc :
alt-svc: h4 = ": 443"; ма=25
Alt-Svc рекламирует несколько версий HTTP/3 для поддержки
более ранние версии, которые используются некоторыми клиентами (например,г.
х4-29 ), а также версии
Google QUIC ( h4-Q050 ), которые также используются. Старые версии обоих
протоколы могут быть удалены из объявления Alt-Svc с течением времени. Если для HTTP/3 явно задано значение DISABLE , ответы не включают
заголовок ответа alt-svc .
Если на балансировщике нагрузки HTTPS включен QUIC, некоторые обстоятельства могут заставить ваш клиент вернуться к HTTPS или HTTP/2 вместо согласования QUIC.К ним относятся следующие:
- Когда клиент поддерживает версии HTTP/3, несовместимые с Версии HTTP/3, поддерживаемые балансировщиком нагрузки HTTPS.
- Когда балансировщик нагрузки обнаруживает, что трафик UDP заблокирован или ограничен по скорости таким образом, чтобы препятствовать работе HTTP/3 (QUIC).
- Клиент вообще не поддерживает HTTP/3 и поэтому не пытается
согласовать соединение HTTP/3.
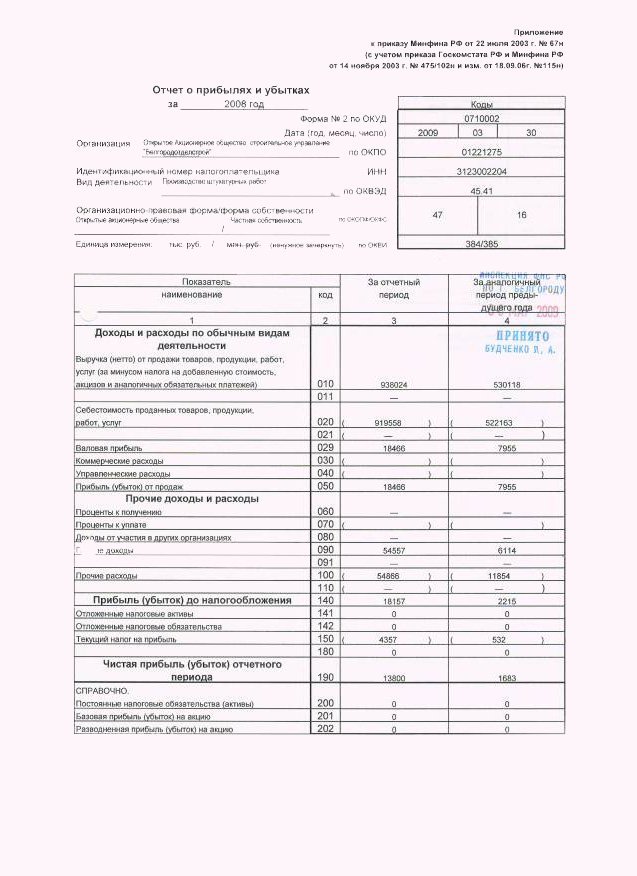
Когда соединение возвращается к HTTPS или HTTP/2 из-за этих обстоятельств, мы не считаем это сбоем балансировщика нагрузки.
Перед включением HTTP/3 убедитесь, что описанное выше поведение приемлемо. для ваших рабочих нагрузок.
URL-карты
Карты URL-адресов определяют шаблоны сопоставления для Маршрутизация запросов на основе URL-адресов к соответствующим внутренним службам. По умолчанию служба определена для обработки любых запросов, которые не соответствуют указанному хосту правило или правило сопоставления путей. В некоторых ситуациях, таких как пример балансировки нагрузки в нескольких регионах, вы можете не определять никаких правил URL и полагаться только на службу по умолчанию.Для маршрутизации запросов карта URL-адресов позволяет разделить трафик, исследуя компоненты URL для отправки запросов на различные наборы бэкенды.
сопоставления URL-адресов, используемые с глобальными внешними балансировщиками нагрузки HTTP(S) и региональными внешними балансировщиками нагрузки HTTP(S)
поддерживать несколько расширенных функций управления трафиком, таких как заголовки на основе
управление трафиком, разделение трафика на основе веса и зеркалирование запросов.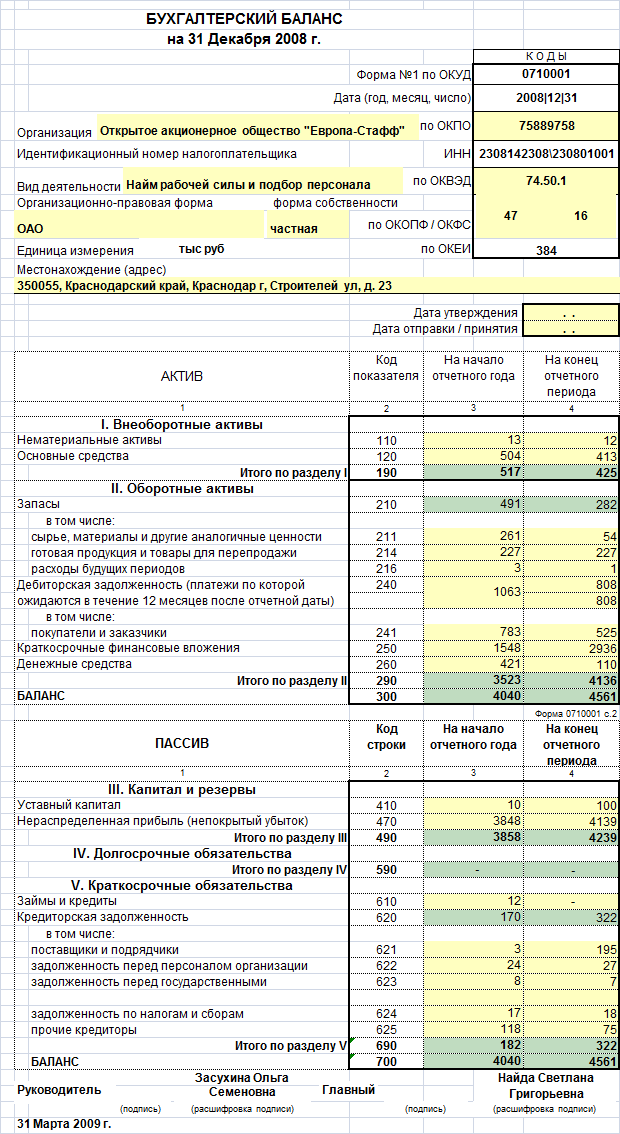 Для получения дополнительной информации см. следующее:
Для получения дополнительной информации см. следующее:
В следующей таблице указан тип сопоставления URL-адресов, требуемый Балансировка нагрузки HTTP(S) в каждом режиме.
SSL-сертификаты
Transport Layer Security (TLS) — это протокол шифрования, используемый в SSL. сертификаты для защиты сетевых коммуникаций.
Google Cloud использует SSL-сертификаты для обеспечения конфиденциальности и безопасности клиента. к балансировщику нагрузки. Если вы используете балансировку нагрузки на основе HTTPS, вы должны установите один или несколько SSL-сертификатов на целевой HTTPS-прокси.
В следующей таблице указана область действия SSL-сертификата, необходимого для Балансировка нагрузки HTTP(S) в каждом режиме:| Режим балансировки нагрузки | Область SSL-сертификата |
|---|---|
| Глобальный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | Глобальный |
| Глобальный внешний балансировщик нагрузки HTTP(S) (классический) | Глобальный |
| Региональный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | Региональный |
Для получения дополнительной информации о сертификатах SSL см.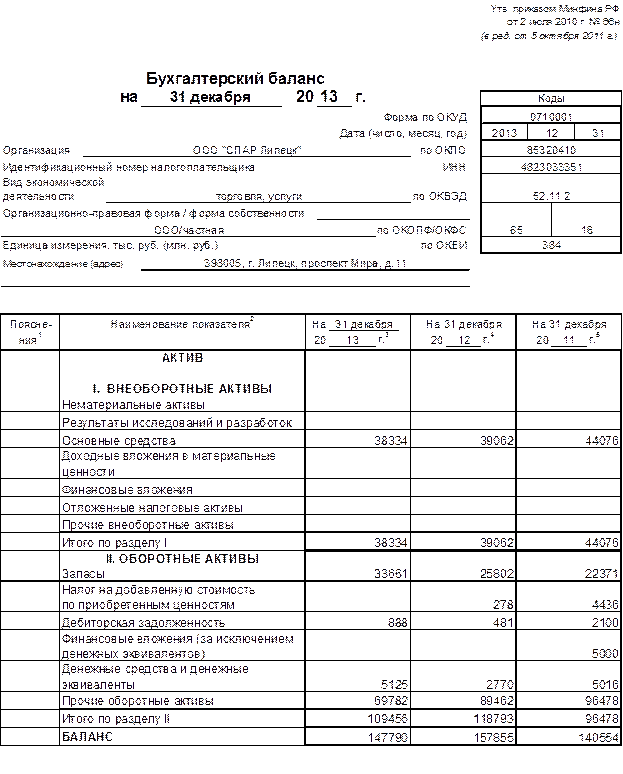 следующее:
следующее:
Политики SSL
ПолитикиSSL дают вам возможность для управления функциями SSL, с которыми согласовывает ваш балансировщик нагрузки HTTPS HTTPS-клиенты.
По умолчанию балансировка нагрузки HTTPS использует набор функций SSL, безопасность и широкая совместимость. Некоторые приложения требуют большего контроля над какие версии SSL и шифры используются для их соединений HTTPS или SSL. Ты можно определить политики SSL, управляющие функциями SSL, которые вы загружаете балансировщик согласовывает и связывает политику SSL с вашим целевым прокси-сервером HTTPS.
В следующей таблице указана поддержка политик SSL для балансировщиков нагрузки. в каждом режиме.
| Режим балансировки нагрузки | Поддерживаемые политики SSL |
|---|---|
| Глобальный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | |
| Глобальный внешний балансировщик нагрузки HTTP(S) (классический) | |
| Региональный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) |
Серверные службы и сегменты
Бэкэнд-сервисы предоставляют конфигурацию
информацию балансировщику нагрузки.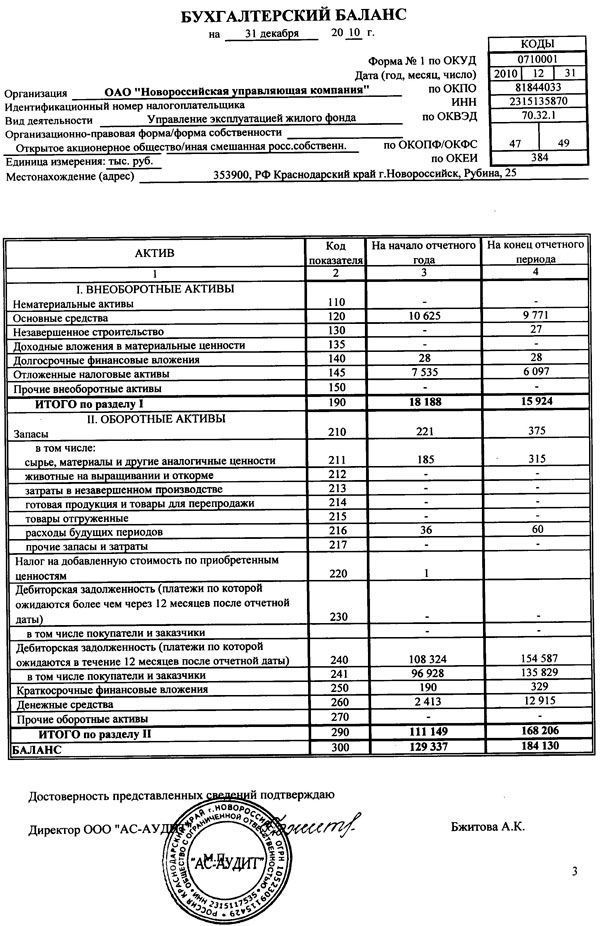 Балансировщики нагрузки используют информацию в
бэкэнд-сервис для направления входящего трафика на один или несколько подключенных бэкендов.
Пример, показывающий, как настроить балансировщик нагрузки с серверной частью
службу и серверную часть Compute Engine, см. раздел Настройка внешнего балансировщика нагрузки HTTP(S) с помощью
серверная часть Compute Engine.
Балансировщики нагрузки используют информацию в
бэкэнд-сервис для направления входящего трафика на один или несколько подключенных бэкендов.
Пример, показывающий, как настроить балансировщик нагрузки с серверной частью
службу и серверную часть Compute Engine, см. раздел Настройка внешнего балансировщика нагрузки HTTP(S) с помощью
серверная часть Compute Engine.
Backend-сегменты направляют входящий трафик в Cloud Storage ведра. Для примера, показывающего, как добавить корзину на внешний балансировщик нагрузки HTTP(S), см. раздел Настройка балансировщика нагрузки с помощью бэкэнд-ковши.
В следующей таблице указаны серверные функции, поддерживаемые Балансировка нагрузки HTTP(S) в каждом режиме.
| Режим балансировки нагрузки | Поддерживаемые серверные части в серверной службе | Поддерживает внутренние сегменты | Поддерживает Google Cloud Armor | поддерживает облачную CDN | Поддерживает IAP | ||||
|---|---|---|---|---|---|---|---|---|---|
| Группы экземпляров | Зональные NEG | NEG в Интернете | Бессерверные NEG | Гибридные NEG | |||||
| Глобальный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | |||||||||
| Глобальный внешний балансировщик нагрузки HTTP(S) (классический) | при использовании уровня Premium | | |||||||
| Региональный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | |||||||||
Для получения дополнительной информации см.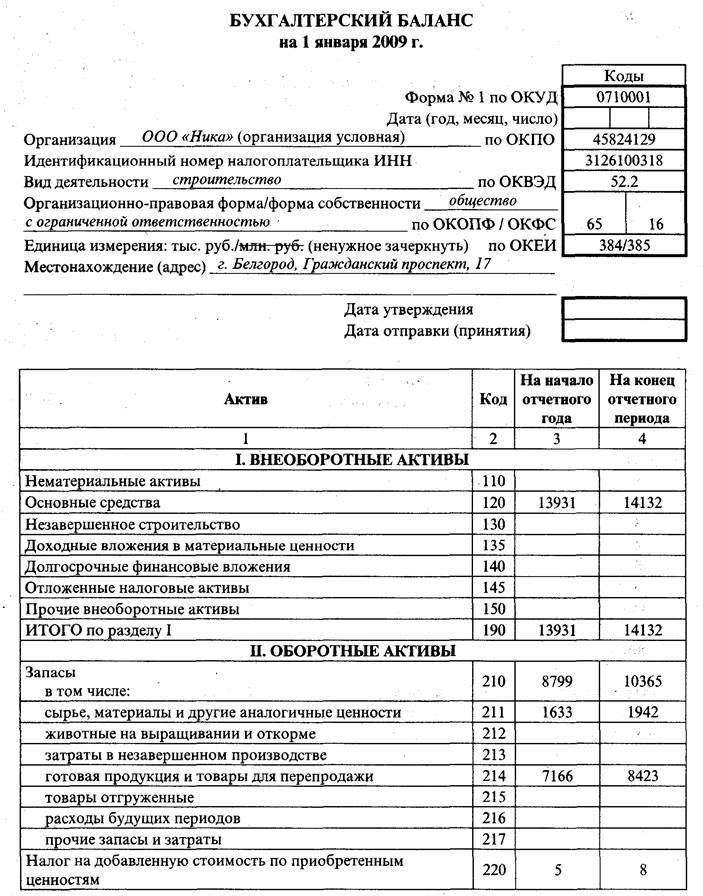 :
:
Серверные части и сети VPC
Ограничения на размещение серверных частей зависят от типа балансировщик нагрузки.
- Для глобального внешнего балансировщика нагрузки HTTP(S) все серверные части должны располагаться в одном Сеть VPC.
- Для глобального внешнего балансировщика нагрузки HTTP(S) (классического) все серверные части должны располагаться в одном проекта, но могут находиться в разных сетях VPC. То различные сети VPC не нужно соединять с помощью Сетевой пиринг VPC, поскольку прокси-системы GFE взаимодействуют напрямую с бэкэнды в соответствующих сетях VPC.
- Для регионального внешнего балансировщика нагрузки HTTP(S) все серверные части должны располагаться в одном Сеть VPC и регион.
Протокол к бэкендам
При настройке внутренней службы балансировщика нагрузки
установить протокол, который серверная служба использует для связи с серверными частями. Вы можете выбрать HTTP, HTTPS или HTTP/2. Балансировщик нагрузки использует только протокол
что вы указываете. Балансировщик нагрузки не переключается на другой
протоколы, если он не может договориться о подключении к серверной части с
указанный протокол.
Вы можете выбрать HTTP, HTTPS или HTTP/2. Балансировщик нагрузки использует только протокол
что вы указываете. Балансировщик нагрузки не переключается на другой
протоколы, если он не может договориться о подключении к серверной части с
указанный протокол.
Если вы используете HTTP/2, вы должны использовать TLS.HTTP/2 без шифрования не поддерживается.
Полный список поддерживаемых протоколов см. в разделе Функции балансировки нагрузки: Протоколы от балансировщика нагрузки к бэкенды.
Поддержка веб-сокетов
Балансировщики нагрузки Google Cloud на основе HTTP(S) имеют встроенную поддержку Протокол WebSocket, когда вы используете HTTP или HTTPS в качестве протокола для серверной части. Балансировщик нагрузки не нуждается в какой-либо настройке для прокси-сервера WebSocket. соединения.
Примечание. HTTP/2 не поддерживается. Протокол WebSocket обеспечивает полнодуплексный канал связи между
клиентов и серверов.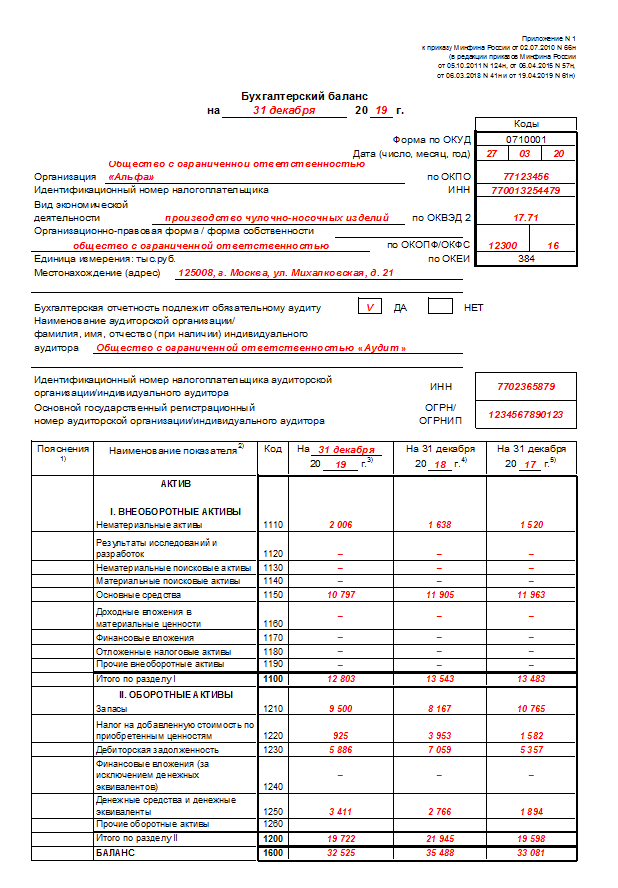 Запрос HTTP(S) инициирует канал. За
подробную информацию о протоколе см. в RFC
6455.
Запрос HTTP(S) инициирует канал. За
подробную информацию о протоколе см. в RFC
6455.
Когда балансировщик нагрузки распознает запрос WebSocket Upgrade от
клиент HTTP(S), за которым следует успешный ответ Upgrade от серверной части
Например, балансировщик нагрузки проксирует двунаправленный трафик для
продолжительность текущего соединения. Если серверный экземпляр не возвращается
при успешном ответе Upgrade балансировщик нагрузки закрывает соединение.
Время ожидания для соединения WebSocket зависит от настраиваемого бэкенда . тайм-аут службы балансировщика нагрузки, который по умолчанию составляет 30 секунд. Этот тайм-аут применяется к соединениям WebSocket независимо от того, находятся ли они в использовать.
Привязка сеанса для WebSockets работает так же, как и для любого другого запроса.
Для получения информации см. Сессия
близость.
Использование gRPC с приложениями Google Cloud
gRPC — это фреймворк с открытым исходным кодом. для удаленных вызовов процедур.Он основан на стандарте HTTP/2. Варианты использования для gRPC включает следующее:
- Распределенные системы с низкой задержкой, высокой масштабируемостью
- Разработка мобильных клиентов, взаимодействующих с облачным сервером
- Разработка новых протоколов, которые должны быть точными, эффективными и независимый от языка
- Многоуровневый дизайн для включения расширения, проверки подлинности и ведения журнала
Чтобы использовать gRPC с вашими приложениями Google Cloud, вы должны использовать прокси сквозные запросы через HTTP/2.Для этого:
- Настройте балансировщик нагрузки HTTPS.
- Включите HTTP/2 в качестве протокола от балансировщика нагрузки к серверным компонентам.
Балансировщик нагрузки согласовывает HTTP/2 с клиентами как часть подтверждения SSL путем
используя расширение ALPN TLS.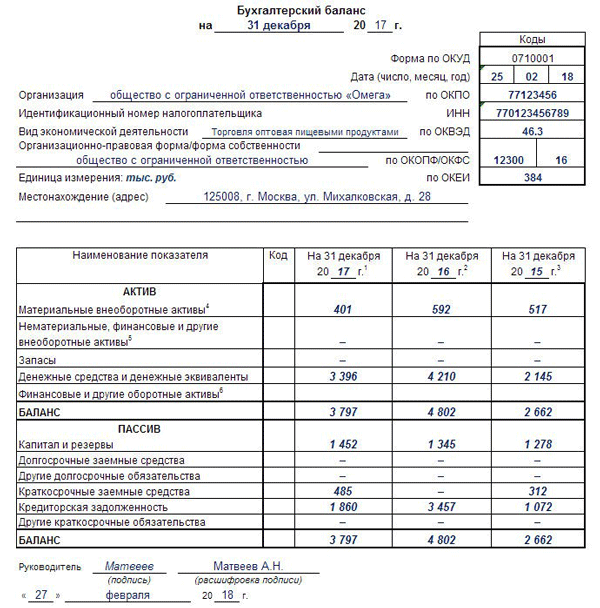
Балансировщик нагрузки по-прежнему может согласовывать HTTPS с некоторыми клиентами или принимать небезопасные HTTP-запросы балансировщика нагрузки, настроенного на использование HTTP/2. между балансировщиком нагрузки и серверными экземплярами. Эти HTTP или HTTPS запросы преобразуются балансировщиком нагрузки для проксирования запросов через HTTP/2. для серверных экземпляров.
Вы должны включить TLS на своих серверах. Дополнительные сведения см. в разделе Шифрование из балансировщик нагрузки на серверные части.
Если вы хотите настроить внешний балансировщик нагрузки HTTP(S) с помощью HTTP/2 с Google Kubernetes Engine Ingress или с помощью gRPC и HTTP/2 с Ingress, см. HTTP/2 для балансировки нагрузки с Ingress.
Информацию об устранении неполадок с HTTP/2 см. Устранение неполадок с HTTP/2 для бэкенды.
Для получения информации об ограничениях HTTP/2 см. Ограничения HTTP/2.
Медицинские осмотры
Каждая серверная служба определяет проверку работоспособности серверных экземпляров.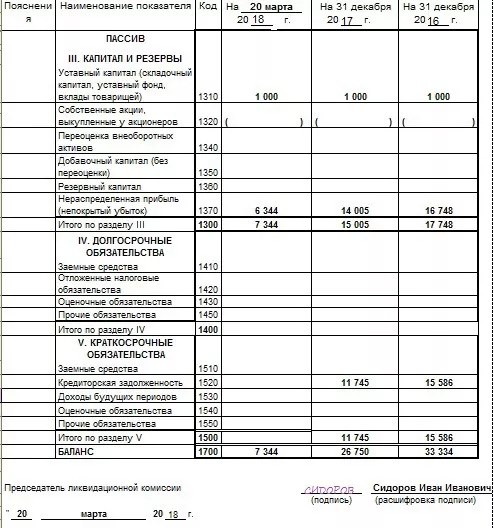
Для зондов проверки работоспособности необходимо создать правило брандмауэра, разрешающее вход, которое позволяет трафику достигать ваших серверных экземпляров. Правило брандмауэра должно разрешать следующие исходные диапазоны:
-
130.211.0.0/22 -
35.191.0.0/16
Хотя это и не обязательно, рекомендуется использовать проверку работоспособности, протокол соответствует протоколу серверной службы.Например, проверка работоспособности HTTP/2 наиболее точно проверяет подключение HTTP/2 к бэкенды. Список поддерживаемых протоколов проверки работоспособности см. в разделе Загрузка. особенности балансировки.
В следующей таблице указаны области проверки работоспособности, поддерживаемые Балансировка нагрузки HTTP(S) в каждом режиме.
| Режим балансировки нагрузки | Тип проверки работоспособности |
|---|---|
| Глобальный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | Глобальный |
| Глобальный внешний балансировщик нагрузки HTTP(S) (классический) | Глобальный |
| Региональный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | Региональный |
Дополнительные сведения о проверках работоспособности см. в следующих документах:
в следующих документах:
Правила брандмауэра
Для балансировки нагрузки HTTP(S) требуются следующие правила брандмауэра:
- Для глобальных внешних балансировщиков нагрузки HTTP(S) разрешение на вход
правило, разрешающее трафик из
Google Front Ends (GFE) для доступа к вашим бэкендам.
Для регионального внешнего балансировщика нагрузки HTTP(S) правило разрешения входа, разрешающее трафик из подсети только для прокси. - Правило разрешения входа, разрешающее трафик из диапазонов зондов проверки работоспособности. Для получения дополнительной информации о датчиках проверки работоспособности и о том, почему необходимо разрешить трафик от них, см. Диапазоны IP-адресов зонда и брандмауэр правила.
Порты для этих правил брандмауэра должны быть настроены следующим образом:
Разрешить трафик на порт назначения для проверки работоспособности каждой серверной службы.
Для серверных частей группы экземпляров: определите порты, которые должны быть настроены сопоставление между именованными серверными службами порт и номера портов, связанные с этим именованным портом в каждой группе экземпляров.
То
номера портов могут различаться среди групп экземпляров, назначенных одному и тому же бэкенду.
услуга.Для серверных частей
GCE_VM_IP_PORTNEG: разрешить трафик на номера портов конечные точки.
 То
номера портов могут различаться среди групп экземпляров, назначенных одному и тому же бэкенду.
услуга.
То
номера портов могут различаться среди групп экземпляров, назначенных одному и тому же бэкенду.
услуга.Правила брандмауэра реализованы на уровне экземпляра ВМ, а не на GFE-прокси.Вы не можете использовать правила брандмауэра Google Cloud для предотвращения трафик не достигает балансировщика нагрузки. Для глобального внешнего балансировщика нагрузки HTTP(S) вы для этого можно использовать Google Cloud Armor.
Для внешних балансировщиков нагрузки HTTP(S) в следующей таблице приведены требуемые IP-адреса. диапазоны для правил брандмауэра:
| Режим балансировки нагрузки | Диапазоны источников проверки работоспособности | Диапазоны источников запросов |
|---|---|---|
| Глобальный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) |
| Источник трафика GFE зависит от типа серверной части:
|
| Глобальный внешний балансировщик нагрузки HTTP(S) (классический) |
| Источник трафика GFE зависит от типа серверной части:
|
| Региональный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) |
| Подсеть только для прокси, которую вы настраиваете. |
 211.0.0/22
211.0.0/22  211.0.0/22
211.0.0/22 
Как работают соединения в балансировке нагрузки HTTP(S)
Глобальные внешние подключения балансировщика нагрузки HTTP(S)
Глобальные внешние балансировщики нагрузки HTTP(S) реализованы многими прокси-серверами под названием Google Front.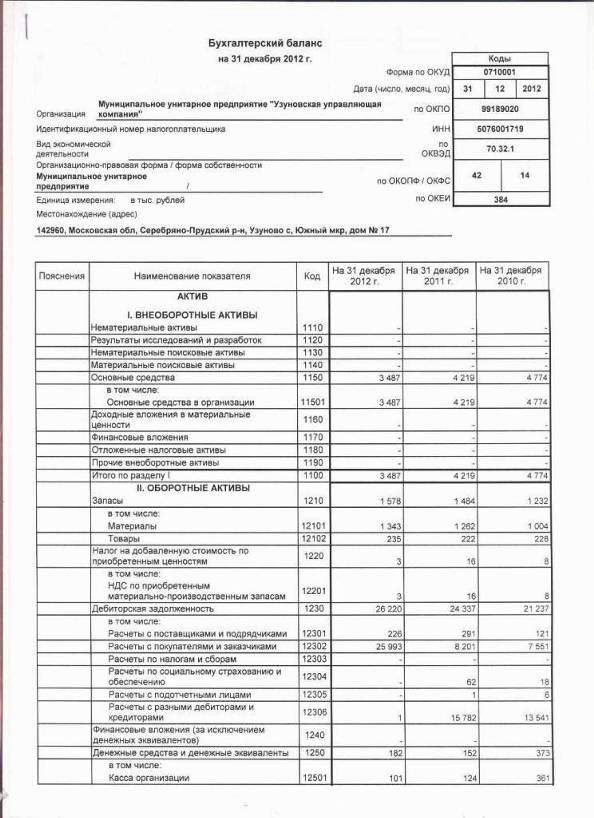 Концы (GFE).Там не просто один прокси. На уровне Premium тот же глобальный
внешний IP-адрес объявляется из различных точек присутствия, и клиент
запросы направляются в ближайший GFE клиента.
Концы (GFE).Там не просто один прокси. На уровне Premium тот же глобальный
внешний IP-адрес объявляется из различных точек присутствия, и клиент
запросы направляются в ближайший GFE клиента.
В зависимости от того, где находятся ваши клиенты, несколько GFE могут инициировать HTTP(S)
подключения к вашим бэкендам. Пакеты, отправленные из GFE, имеют исходные IP-адреса.
из того же диапазона, который используется зондами для проверки работоспособности: 35.191.0.0/16 и 130.211.0.0/22 .
В зависимости от конфигурации серверной службы протокол, используемый каждым GFE для подключение к вашим бэкендам может быть HTTP, HTTPS или HTTP/2. Для HTTP или HTTPS соединения, используемая версия HTTP — HTTP 1.1.
HTTP Keepalive включен по умолчанию, как указано в HTTP 1. 1.
Спецификация. Поддерживающие активности HTTP пытаются эффективно использовать один и тот же сеанс TCP;
однако нет никакой гарантии. GFE использует тайм-аут проверки активности 600 секунд,
и вы не можете настроить это.Однако вы можете настроить запрос/ответ
тайм-аут, установив тайм-аут серверной службы. Несмотря на тесное родство, HTTP
keepalive и тайм-аут простоя TCP — это не одно и то же. Чтобы получить больше информации,
увидеть тайм-ауты и повторные попытки.
1.
Спецификация. Поддерживающие активности HTTP пытаются эффективно использовать один и тот же сеанс TCP;
однако нет никакой гарантии. GFE использует тайм-аут проверки активности 600 секунд,
и вы не можете настроить это.Однако вы можете настроить запрос/ответ
тайм-аут, установив тайм-аут серверной службы. Несмотря на тесное родство, HTTP
keepalive и тайм-аут простоя TCP — это не одно и то же. Чтобы получить больше информации,
увидеть тайм-ауты и повторные попытки.
Количество соединений HTTP и сеансов TCP зависит от количества Подключение GFE, количество клиентов, подключающихся к GFE, протокол для серверные части и где развернуты серверные части.
Дополнительные сведения см. в разделе Как балансировка нагрузки HTTP(S) работает в руководстве по решениям: Оптимизация емкости приложений с глобальной нагрузкой Балансировка.
Региональные внешние подключения балансировщика нагрузки HTTP(S)
Региональный внешний балансировщик нагрузки HTTP(S) — это управляемая служба, реализованная на сервере Envoy. прокси. Региональный внешний балансировщик нагрузки HTTP(S) использует общую подсеть, называемую только прокси-сервером.
подсеть для предоставления набора IP-адресов, которые Google использует для запуска прокси-серверов Envoy.
от вашего имени. Флаг
прокси. Региональный внешний балансировщик нагрузки HTTP(S) использует общую подсеть, называемую только прокси-сервером.
подсеть для предоставления набора IP-адресов, которые Google использует для запуска прокси-серверов Envoy.
от вашего имени. Флаг --цель для этой подсети, предназначенной только для прокси, установлен на РЕГИОНАЛЬНЫЙ_УПРАВЛЯЕМЫЙ_ПРОКСИ . Все региональные внешние балансировщики нагрузки HTTP(S) в определенной сети
и регион разделяют эту подсеть.
--цель установлена на REGIONAL_MANAGED_PROXY ). На это
время, когда в регионе VPC может существовать только одна подсеть только для прокси
сеть. Это означает, что вы не можете одновременно создавать внутренние балансировщики нагрузки HTTP(S) и
региональные внешние балансировщики нагрузки HTTP(S) в том же регионе сети.
Клиенты используют IP-адрес и порт балансировщика нагрузки для подключения к нагрузке балансир. Клиентские запросы направляются в подсеть только для прокси в том же регион в качестве клиента.Балансировщик нагрузки завершает запросы клиентов, а затем открывает новые подключения из подсети только для прокси к вашим бэкендам. Следовательно, пакеты, отправляемые балансировщиком нагрузки, имеют исходные IP-адреса из прокси-сервера. подсеть.
В зависимости от конфигурации серверной службы протокол, используемый Envoy прокси-серверы для подключения к вашим бэкендам могут быть HTTP, HTTPS или HTTP/2. Если HTTP или HTTPS, версия HTTP — HTTP 1.1. HTTP Keepalive включен по умолчанию, т.к. указано в спецификации HTTP 1.1.Прокси-сервер Envoy использует поддержку активности тайм-аут 600 секунд, и вы не можете настроить это. Вы можете, однако, настроить тайм-аут запроса/ответа, установив тайм-аут серверной службы. Дополнительные сведения см. в разделе тайм-ауты и повторные попытки.
Связь клиента с подсистемой балансировки нагрузки
- Клиенты могут взаимодействовать с подсистемой балансировки нагрузки с помощью протокола HTTP 1. 1 или HTTP/2.
протокол.
- При использовании HTTPS современные клиенты по умолчанию используют HTTP/2. Это контролировал на клиенте , а не на балансировщике нагрузки HTTPS.
- Вы не можете отключить HTTP/2, изменив конфигурацию загрузки
балансир. Однако вы можете настроить некоторые клиенты для использования HTTP 1.1.
вместо HTTP/2. Например, для
curlиспользуйте параметр--http1.1. Балансировка нагрузки - HTTP(S) поддерживает ответ
HTTP/1.1 100 Continue.
 1 или HTTP/2.
протокол.
1 или HTTP/2.
протокол.Полный список протоколов, поддерживаемых балансировкой нагрузки HTTP(S) правила переадресации в каждом режиме, см. Балансировщик нагрузки Особенности.
IP-адреса источника для клиентских пакетов
Исходный IP-адрес для пакетов, который видят серверные части, равен , а не .
Внешний IP-адрес Google Cloud балансировщика нагрузки.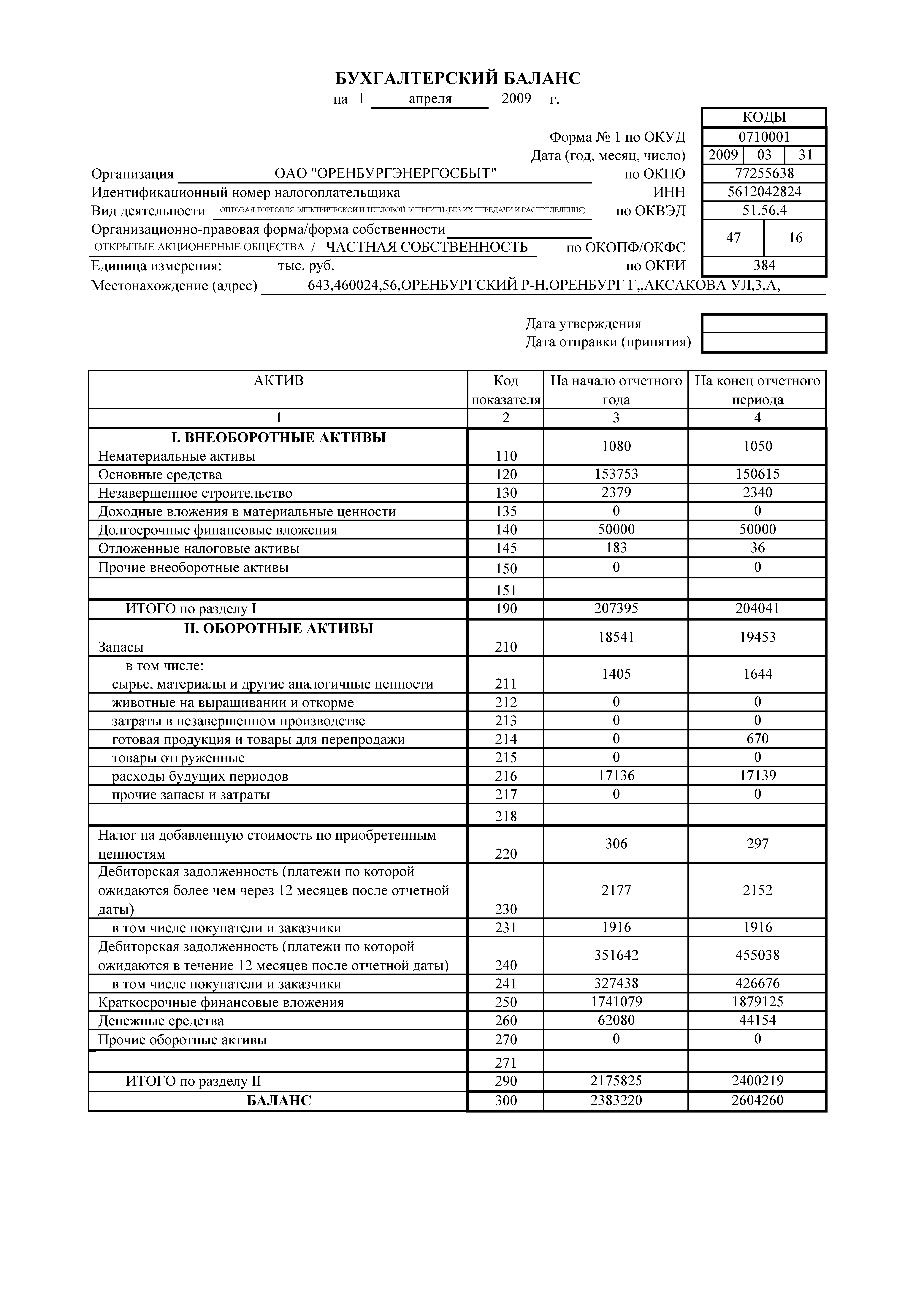 Другими словами,
есть два соединения TCP.
Другими словами,
есть два соединения TCP.
Соединение 1, от исходного клиента к балансировщику нагрузки (GFE):
- Исходный IP-адрес: исходный клиент (или внешний IP-адрес, если клиент находится за NAT или прямым прокси).
- IP-адрес назначения: IP-адрес вашего балансировщика нагрузки.
Подключение 2 от подсистемы балансировки нагрузки (GFE) к серверной виртуальной машине или конечной точке:
IP-адрес источника: IP-адрес в одном из диапазонов, указанных в Правила брандмауэра.
IP-адрес назначения: внутренний IP-адрес серверной ВМ или контейнер в сети VPC.
 в разделе Аутентификация
Запросы. Для региональных внешних балансировщиков нагрузки HTTP(S) :
в разделе Аутентификация
Запросы. Для региональных внешних балансировщиков нагрузки HTTP(S) :Соединение 1, от исходного клиента к балансировщику нагрузки (подсеть только для прокси):
- Исходный IP-адрес: исходный клиент (или внешний IP-адрес, если клиент находится за NAT или прямым прокси).
- IP-адрес назначения: IP-адрес вашего балансировщика нагрузки.
Соединение 2, от балансировщика нагрузки (подсеть только для прокси) к серверной виртуальной машине или конечная точка:
Исходный IP-адрес: IP-адрес только для прокси-сервера подсеть, которая является общей для всей нагрузки на основе Envoy балансировщики, развернутые в том же регионе и сети, что и балансировщик нагрузки.
IP-адрес назначения: внутренний IP-адрес серверной ВМ или контейнер в сети VPC.
Обратный путь
Для глобальных внешних балансировщиков нагрузки HTTP(S), Google Cloud
использует специальные маршруты, не определенные в вашем VPC
сети для проверки работоспособности. Для получения дополнительной информации см.
Пути возврата балансировщика нагрузки.
Для получения дополнительной информации см.
Пути возврата балансировщика нагрузки.
Для региональных внешних балансировщиков нагрузки HTTP(S) Google Cloud использует Envoy с открытым исходным кодом. прокси для завершения клиентских запросов к балансировщику нагрузки. Балансировщик нагрузки завершает сеанс TCP и открывает новый сеанс TCP с регионального прокси-сервера. только подсеть к вашему серверу.Маршруты, определенные в вашем VPC сети облегчают связь от прокси-серверов Envoy к вашим бэкэндам и от ваши серверные части к прокси-серверам Envoy.
Открытые порты
Этот раздел относится только к глобальные внешние балансировщики нагрузки HTTP(S), реализованные с использованием GFE.
Примечание: Региональный внешний балансировщик нагрузки HTTP(S) реализован с использованием прокси-серверов Envoy, которые поддерживаются только порты 80, 8080 и 443. GFE имеют несколько открытых портов для поддержки других служб Google, работающих на
такая же архитектура. Чтобы увидеть список некоторых портов, которые могут быть открыты на GFE,
см. Правило переадресации: Порт
технические характеристики.
Могут быть другие открытые порты для других сервисов Google, работающих на GFE.
Чтобы увидеть список некоторых портов, которые могут быть открыты на GFE,
см. Правило переадресации: Порт
технические характеристики.
Могут быть другие открытые порты для других сервисов Google, работающих на GFE.
Запуск сканирования портов по IP-адресу балансировщика нагрузки на основе GFE бесполезен. с точки зрения аудита по следующим причинам:
Сканирование портов (например, с помощью
nmap) обычно не ожидает ответного пакета или пакет TCP RST при выполнении проверки TCP SYN.GFE отправит SYN-ACK пакеты в ответ на запросы SYN для различных портов, если ваш балансировщик нагрузки использует IP-адрес уровня Premium. Однако GFE отправляют пакеты только на ваш бэкенды в ответ на пакеты, отправленные на IP-адрес вашего балансировщика нагрузки и порт назначения, настроенный в его правиле переадресации. Пакеты отправлены на различные IP-адреса балансировщика нагрузки или IP-адрес вашего балансировщика нагрузки на порт, не настроенный в вашем правиле переадресации, не приводит к отправке пакетов отправляются на серверные части вашего балансировщика нагрузки. GFE реализуют функции безопасности, такие как Google Cloud Armor. Даже без
Конфигурация Google Cloud Armor, инфраструктура Google и GFE обеспечивают
эшелонированная защита от DDoS-атак и SYN-флудов.На пакеты, отправленные на IP-адрес вашего балансировщика нагрузки, может ответить любой GFE в парке Google; однако сканирование IP-адреса балансировщика нагрузки и Комбинация портов назначения опрашивает только один GFE за TCP-соединение. IP-адрес вашего балансировщика нагрузки не назначен отдельное устройство или система.Таким образом, сканирование IP-адреса нагрузки на основе GFE балансировщик не сканирует все GFE в парке Google.
 GFE реализуют функции безопасности, такие как Google Cloud Armor. Даже без
Конфигурация Google Cloud Armor, инфраструктура Google и GFE обеспечивают
эшелонированная защита от DDoS-атак и SYN-флудов.
GFE реализуют функции безопасности, такие как Google Cloud Armor. Даже без
Конфигурация Google Cloud Armor, инфраструктура Google и GFE обеспечивают
эшелонированная защита от DDoS-атак и SYN-флудов.Имея это в виду, ниже приведены несколько более эффективных способов проверки безопасность ваших серверных экземпляров:
Аудитор безопасности должен проверить конфигурацию правил пересылки для конфигурация балансировщика нагрузки. Правила переадресации определяют пункт назначения порт, для которого ваш балансировщик нагрузки принимает пакеты и пересылает их на серверные части.
Для балансировщиков нагрузки на основе GFE каждая внешняя переадресация
правило может ссылаться только на один целевой TCP
порт. Для балансировщика нагрузки, использующего TCP-порт 443, UDP-порт 443 используется, когда
соединение обновлено до QUIC (HTTP/3).Аудитор безопасности должен проверить применимую конфигурацию правила брандмауэра к серверным виртуальным машинам. Установленные вами правила брандмауэра блокируют трафик от GFE. к внутренним виртуальным машинам, но не блокируйте входящий трафик к GFE. Для лучшего практики, см. раздел правил брандмауэра.
 Для балансировщиков нагрузки на основе GFE каждая внешняя переадресация
правило может ссылаться только на один целевой TCP
порт. Для балансировщика нагрузки, использующего TCP-порт 443, UDP-порт 443 используется, когда
соединение обновлено до QUIC (HTTP/3).
Для балансировщиков нагрузки на основе GFE каждая внешняя переадресация
правило может ссылаться только на один целевой TCP
порт. Для балансировщика нагрузки, использующего TCP-порт 443, UDP-порт 443 используется, когда
соединение обновлено до QUIC (HTTP/3).Завершение TLS
В следующей таблице показано, как завершение TLS обрабатывается внешние балансировщики нагрузки HTTP(S) в каждом режиме.
| Режим балансировки нагрузки | Завершение TLS |
|---|---|
| Глобальный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | TLS завершается на GFE, который может находиться в любой точке мира. |
| Глобальный внешний балансировщик нагрузки HTTP(S) (классический) | TLS завершается на GFE, который может находиться в любой точке мира. |
| Региональный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | TLS завершается на прокси-серверах Envoy, расположенных в подсеть в выбранном пользователем регионе. Используйте этот режим балансировщика нагрузки, если вам нужен географический контроль над регион, где TLS завершен. |
Время ожидания и повторные попытки
Внешняя балансировка нагрузки HTTP(S) имеет два различных типа тайм-аутов:Настраиваемый тайм-аут внутренней службы HTTP , который представляет количество времени, в течение которого балансировщик нагрузки ожидает, пока ваш сервер вернет полный HTTP-ответ.Значение по умолчанию для тайм-аута серверной службы: 30 секунд. Полный диапазон допустимых значений тайм-аута: 1–2 147 483 647.
секунды.Например, если значение тайм-аута серверной службы установлено по умолчанию. значение 30 секунд, у бэкендов есть 30 секунд, чтобы ответить на запросы. Балансировщик нагрузки повторяет HTTP-запрос GET один раз, если сервер закрывается. соединение или время ожидания перед отправкой заголовков ответа на загрузку балансир. Если серверная часть отправляет заголовки ответа или если запрос отправлен на серверная часть не является HTTP-запросом GET, балансировщик нагрузки не повторяет попытку.Если серверная часть вообще не отвечает, балансировщик нагрузки возвращает HTTP 5xx ответ клиенту. Для этих балансировщиков нагрузки измените значение времени ожидания. если вы хотите дать больше или меньше времени бэкендам для ответа на Запросы.
Тайм-аут серверной службы должен быть установлен на максимально возможное время с первого байта запроса до последнего байта ответа, для взаимодействие между GFE и вашим сервером. если ты используют WebSockets, тайм-аут серверной службы должен быть установлен на максимальная продолжительность WebSocket, бездействующего или активного.
Рассмотрите возможность увеличения этого времени ожидания при любом из следующих обстоятельств:
- Вы ожидаете, что серверная часть будет дольше возвращать ответы HTTP.
- Вы видите ответ HTTP
408сjsonPayload.statusDetailclient_timed_out. - Соединение обновлено до WebSocket.
Установленный вами тайм-аут серверной службы является максимально возможной целью. Это не гарантировать, что базовые TCP-соединения останутся открытыми в течение этот тайм-аут.
Вы можете установить для тайм-аута серверной службы любое желаемое значение; однако установка значения больше одного дня (86 400 секунд) не означает что балансировщик нагрузки будет поддерживать TCP-соединение в течение этого времени. Это может, а может и нет. Google периодически перезапускает GFE для программного обеспечения обновления и плановое обслуживание, а тайм-аут серверной службы не отменить это.
Чем дольше вы делаете тайм-аут серверной службы, тем больше
скорее всего, Google прервет TCP-соединение для GFE.
поддержание.Мы рекомендуем вам реализовать логику повторных попыток, чтобы уменьшить влияние
такие события.Для получения дополнительной информации см. Настройки серверной службы.
Тайм-аут серверной службы не является тайм-аутом бездействия HTTP (поддержки активности). Это возможно, что ввод и вывод (IO) из бэкенда заблокирован из-за медленный клиент (например, браузер с медленным подключением). Это время ожидания не учитывается в тайм-ауте серверной службы.
Для региональных внешних балансировщиков нагрузки HTTP(S) карта URL-адресов
Действия маршрута.тайм-аутпараметр может переопределить тайм-аут серверной службы. Бэкэнд время ожидания службы используется как значение по умолчанию дляrouteActions.timeout.
 секунды.
секунды.
 Чем дольше вы делаете тайм-аут серверной службы, тем больше
скорее всего, Google прервет TCP-соединение для GFE.
поддержание.Мы рекомендуем вам реализовать логику повторных попыток, чтобы уменьшить влияние
такие события.
Чем дольше вы делаете тайм-аут серверной службы, тем больше
скорее всего, Google прервет TCP-соединение для GFE.
поддержание.Мы рекомендуем вам реализовать логику повторных попыток, чтобы уменьшить влияние
такие события.- Тайм-аут проверки активности HTTP , фиксированное значение которого составляет 10 минут (600 секунд). Это значение нельзя настроить, изменив серверную службу. Ты должен
настройте программное обеспечение веб-сервера, используемое вашими бэкэндами, чтобы его поддержка активности
тайм-аут превышает 600 секунд, чтобы предотвратить закрытие соединений.
преждевременно бэкэндом.Этот тайм-аут не применяется к WebSockets. В этой таблице показаны изменения, необходимые для изменения тайм-аутов проверки активности для
общее программное обеспечение веб-сервера:
 Это значение нельзя настроить, изменив серверную службу. Ты должен
настройте программное обеспечение веб-сервера, используемое вашими бэкэндами, чтобы его поддержка активности
тайм-аут превышает 600 секунд, чтобы предотвратить закрытие соединений.
преждевременно бэкэндом.Этот тайм-аут не применяется к WebSockets. В этой таблице показаны изменения, необходимые для изменения тайм-аутов проверки активности для
общее программное обеспечение веб-сервера:
Это значение нельзя настроить, изменив серверную службу. Ты должен
настройте программное обеспечение веб-сервера, используемое вашими бэкэндами, чтобы его поддержка активности
тайм-аут превышает 600 секунд, чтобы предотвратить закрытие соединений.
преждевременно бэкэндом.Этот тайм-аут не применяется к WebSockets. В этой таблице показаны изменения, необходимые для изменения тайм-аутов проверки активности для
общее программное обеспечение веб-сервера:Повторные попытки
Поддержка балансировки нагрузки HTTP(S) для логики повторных попыток зависит от режима внешнего балансировщика нагрузки HTTP(S).
| Режим балансировки нагрузки | Логика повтора |
|---|---|
| Глобальный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | Настраивается с помощью
политика повторных попыток
в карте URL. Без политики повтора неудачные запросы без тела HTTP (например, запросы GET), приводящие к ответам HTTP 502, 503 или 504. повторяются один раз.Запросы HTTP POST не повторяются. |
| Глобальный внешний балансировщик нагрузки HTTP(S) (классический) | Политика повторных попыток не может быть изменена для повторных попыток подключения. Запросы HTTP POST не повторяются. Запросы HTTP GET всегда повторяются один раз до тех пор, пока 80% или более
бэкенды здоровы. Балансировщик нагрузки повторяет неудачные запросы GET в определенных
обстоятельствах, например, когда тайм-аут серверной службы исчерпан.
Количество повторных запросов ограничено Неудачные запросы приводят к тому, что балансировщик нагрузки синтезирует Ответ HTTP 502. |
| Региональный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | Настраивается с помощью
URL-карта
( Без политики повтора запросы без тела HTTP (например, GET-запросы) повторяются один раз. |
 Количество повторных попыток по умолчанию (
Количество повторных попыток по умолчанию (  Если в
группа и соединение с этим серверным экземпляром завершается сбоем,
процент неработоспособных серверных экземпляров составляет
100%, поэтому GFE не повторяет запрос.
Если в
группа и соединение с этим серверным экземпляром завершается сбоем,
процент неработоспособных серверных экземпляров составляет
100%, поэтому GFE не повторяет запрос.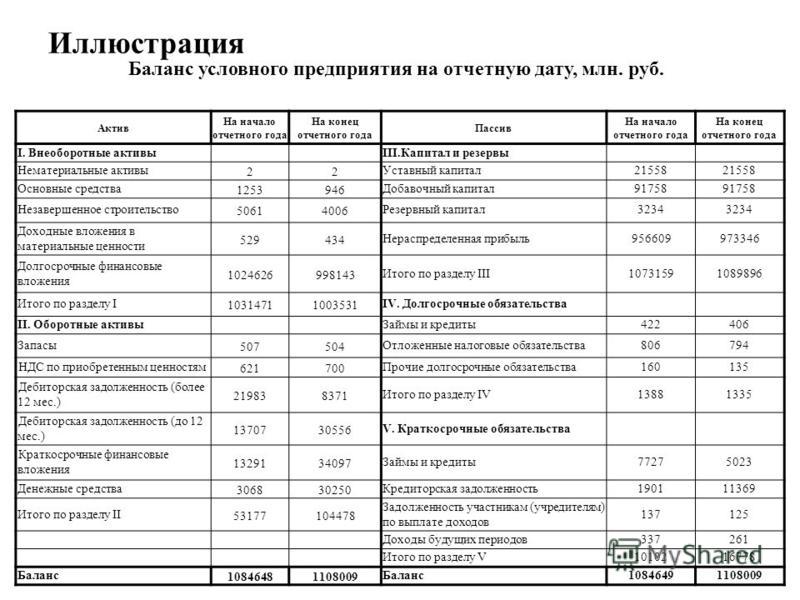
Протокол WebSocket поддерживается GKE Вход.
Недопустимая обработка запросов и ответов
Балансировщик нагрузки блокирует как клиентские запросы, так и внутренние ответы от достижения бэкенда или клиента, соответственно, по ряду причин.Немного причины строго для соответствия HTTP/1.1 и другие, чтобы избежать неожиданных данные передаются на серверы или из них. Ни одна из проверок не может быть отключена.
Балансировщик нагрузки блокирует следующее для соответствия HTTP/1.1:
- Невозможно проанализировать первую строку запроса.
- В заголовке отсутствует разделитель
:. - Заголовки или первая строка содержат недопустимые символы.
- Длина содержимого не является допустимым числом или существует несколько
заголовки длины содержимого.
- Имеется несколько ключей кодирования передачи или нераспознанные передавать значения кодировки.
- Тело не разбито на фрагменты, длина содержимого не указана.
- Фрагменты тела невозможно разобрать. Это единственный случай, когда некоторые данные достигает бэкенда. Балансировщик нагрузки закрывает соединения с клиентом и бэкэнд, когда он получает неразборчивый фрагмент.
Балансировщик нагрузки блокирует запрос, если выполняется одно из следующих условий:
- Общий размер заголовков запроса и URL запроса превышает предел максимального запроса размер заголовка для внешней балансировки нагрузки HTTP(S).
- Метод запроса не разрешает тело, но оно есть в запросе.
- Запрос содержит заголовок
Upgrade, а заголовокUpgradeне используется для включения соединений WebSocket. - Версия HTTP неизвестна.
Балансировщик нагрузки блокирует ответ серверной части, если выполняется одно из следующих действий. правда:
правда:
- Общий размер заголовков ответа превышает предел максимального ответа размер заголовка для внешней балансировки нагрузки HTTP(S).
- Версия HTTP неизвестна.
Распределение трафика
Когда вы добавляете группу серверных экземпляров или NEG к серверной службе, вы укажите режим балансировки , который определяет метод измерения нагрузки на серверную часть и целевая емкость. Внешняя балансировка нагрузки HTTP(S) поддерживает два режимы:
RATE, например, групп или NEG, является целевым максимальным числом запросов (запросов) в секунду (RPS, QPS). Целевой максимальный RPS/QPS может быть превышено, если все серверные части работают на полную мощность или превышают ее.ИСПОЛЬЗОВАНИЕ— использование серверной части виртуальных машин в группе экземпляров.
Способ распределения трафика между бэкендами зависит от режима
балансировщик нагрузки.
Глобальный внешний балансировщик нагрузки HTTP(S)
Перед тем, как внешний интерфейс Google (GFE) отправит запросы на серверные экземпляры, GFE оценивает, какие серверные экземпляры имеют возможность получать запросы. Этот оценка пропускной способности производится проактивно, а не одновременно с запросами прибытие.GFE получают периодическую информацию о доступной мощности и соответствующим образом распределять входящие запросы.
То, что означает емкость , частично зависит от режима балансировки. Для СТАВКА режиме, это относительно просто: GFE точно определяет, сколько запросов он может
назначить в секунду. ИСПОЛЬЗОВАНИЕ Балансировка нагрузки на основе более сложна: нагрузка
балансировщик проверяет текущее использование экземпляров, а затем оценивает запрос
нагрузка, с которой может справиться каждый экземпляр.Эта оценка меняется со временем, как например
использование и структура трафика меняются.
Оба фактора — оценка мощности и упреждающее назначение — влияют на Распределение между экземплярами. Таким образом, облачная балансировка нагрузки ведет себя отличается от простого циклического балансировщика нагрузки, который распределяет запросы ровно 50:50 между двумя экземплярами. Вместо этого балансировка нагрузки Google Cloud пытается оптимизировать выбор экземпляра бэкэнда для каждого запроса.
Для глобального внешнего балансировщика нагрузки HTTP(S) (классический) режим балансировки используется для выбора благоприятный бэкэнд (экземплярная группа или NEG).Затем трафик распределяется в циклический перебор между экземплярами или конечными точками внутри бэкэнда.
Для глобального внешнего балансировщика нагрузки HTTP(S) балансировка нагрузки является двухуровневой. Балансировка
режим определяет вес или долю трафика, который должен быть отправлен каждому
серверная часть (группа экземпляров или NEG). Затем политика балансировки нагрузки
( LocalityLbPolicy ) определяет, как трафик распределяется между экземплярами или
конечные точки внутри группы. Дополнительные сведения см. в разделе Балансировка нагрузки.
политика локации (API серверной службы
документация).
Дополнительные сведения см. в разделе Балансировка нагрузки.
политика локации (API серверной службы
документация).
Региональный внешний балансировщик нагрузки HTTP(S)
Для региональных внешних балансировщиков нагрузки HTTP(S) распределение трафика основано на нагрузке режим балансировки и политика локальности балансировки нагрузки.
Режим балансировки определяет вес и долю трафика, который должен
отправляется каждой группе (экземплярной группе или NEG). Политика локальности балансировки нагрузки
( LocalityLbPolicy ) определяет, как серверные части в группе распределяются по нагрузке.
Когда серверная служба получает трафик, она сначала направляет трафик на серверную
(группа экземпляров или NEG) в соответствии с режимом балансировки серверной части.После
серверной части, трафик затем распределяется между экземплярами или конечными точками в
этой серверной группы в соответствии с политикой локальности балансировки нагрузки.
Для получения дополнительной информации см. следующее:
Как распределяются запросы
Распределяется ли трафик регионально или глобально, зависит от того, какой используется режим балансировки нагрузки и уровень сетевых служб.
Для премиум-уровня:
- Google рекламирует IP-адрес вашего балансировщика нагрузки со всех точек присутствие по всему миру.Каждый IP-адрес балансировщика нагрузки является глобальным произвольным.
- Если вы настраиваете серверную службу с серверными частями в нескольких регионах, Google Внешние интерфейсы (GFE) пытаются направить запросы на исправный серверный экземпляр. группы или группы NEG в ближайшем к пользователю регионе. Подробности процесса есть задокументировано на этой странице.
Для стандартного уровня:
Google объявляет IP-адрес вашего балансировщика нагрузки из точек присутствия связанный с регионом правила переадресации.
Балансировщик нагрузки использует
региональный внешний IP-адрес.Вы можете настроить серверные части в том же регионе, что и правило переадресации. Задокументированный здесь процесс все еще применяется, но балансировщик нагрузки только направляет запросы к работоспособным бэкэндам в этом регионе.
 Балансировщик нагрузки использует
региональный внешний IP-адрес.
Балансировщик нагрузки использует
региональный внешний IP-адрес.Процесс распределения запросов:
Режим балансировки и выбор цели определяют полноту бэкенда с точки зрения каждой зоны GCE_VM_IP_PORT NEG, группа зональных экземпляров,
или зона региональной группы экземпляров.Распределение внутри зоны осуществляется с помощью
последовательное хеширование для глобального внешнего балансировщика нагрузки HTTP(S) (классический) и настраивается с помощью
политика локализации балансировки нагрузки для глобального внешнего балансировщика нагрузки HTTP(S) и
региональный внешний балансировщик нагрузки HTTP(S).Глобальные внешние балансировщики нагрузки HTTP(S) на основе GFE используют следующий процесс для распределения входящие запросы:
- Внешний IP-адрес правила переадресации объявляется пограничными маршрутизаторами на
границы сети Google. В каждом объявлении указан следующий переход к
Система балансировки нагрузки уровня 3/4 (Maglev) максимально приближена к пользователю. Системы
- Maglev проверяют исходный IP-адрес входящего пакета. Они направить входящий запрос в системы Maglev, которые гео-IP Google системы определяют, находятся как можно ближе к пользователю.
- Системы Maglev направляют трафик на первый уровень Google Front End (GFE). GFE первого уровня при необходимости завершает TLS, а затем направляет трафик на GFE второго уровня в соответствии с этим процессом:
- Карта URL-адресов выбирает серверную службу.
- Если серверная служба использует группу экземпляров или
GCE_VM_IP_PORTСерверные части NEG, GFE первого уровня предпочитают GFE второго уровня, которые расположенный в регионе, содержащем группу экземпляров или NEG, или рядом с ним. - Для серверных сегментов и серверных служб с гибридными NEG, без сервера
NEG и интернет-NEG, GFE первого уровня выбирают GFE второго уровня в
подмножество регионов, такое, что время прохождения туда и обратно между двумя GFE равно
сведен к минимуму.
Предпочтение GFE второго уровня не является гарантией и может динамически изменяться в зависимости от состояния сети и технического обслуживания Google.
GFE второго уровня осведомлены о статусе проверки работоспособности и фактическом бэкэнде использование мощностей.
- GFE второго уровня направляет запросы на серверные части в зонах в пределах своего область.
- Для уровня Premium иногда GFE второго уровня отправляют запросы на серверные части. в зонах разных регионов.Такое поведение называется перелив .
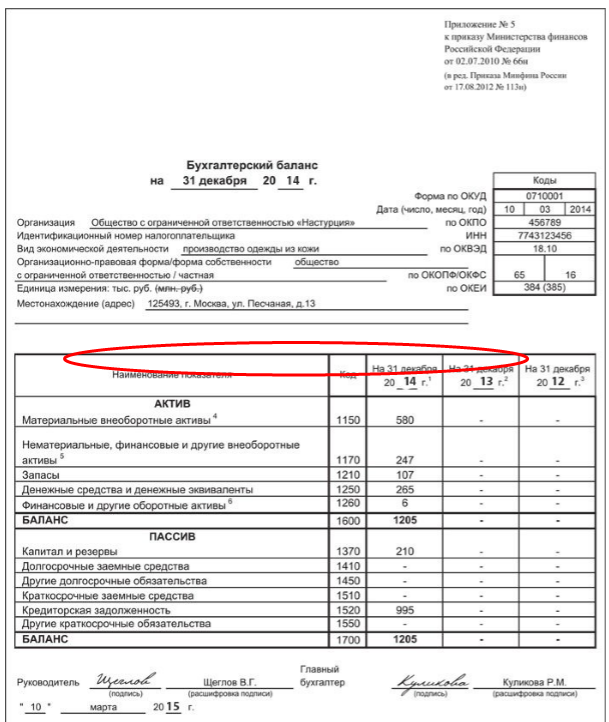 В каждом объявлении указан следующий переход к
Система балансировки нагрузки уровня 3/4 (Maglev) максимально приближена к пользователю.
В каждом объявлении указан следующий переход к
Система балансировки нагрузки уровня 3/4 (Maglev) максимально приближена к пользователю.
Распространение регулируется двумя принципами:
- Распространение возможно, когда все серверные части известны второму уровню GFE загружены или неисправны.
- GFE второго уровня содержит информацию о исправном, доступном бэкенды в зонах другого региона.
GFE второго уровня обычно настраиваются для обслуживания подмножества
серверные локации.
Побочное поведение не исчерпывает все возможные Google Cloud зоны. Если вам нужно направить трафик от бэкэндов в определенном зоне или во всем регионе, необходимо установить Масштабирование емкости до нуля. Настройка бэкендов для отказа от проверок работоспособности не гарантирует, что GFE второго уровня распространяется на серверные части в зонах другого региона.
При распределении запросов на серверные части GFE работают на зональном уровень.
При небольшом количестве запросов в секунду GFE второго уровня иногда предпочитают одну зону в регионе другим зонам. Это предпочтение нормально и ожидаемо. Распределение по зонам в регионе не выравниваться до тех пор, пока балансировщик нагрузки не получит больше запросов в секунду.
Привязка сеанса
Привязка сеанса
обеспечивает максимальные попытки отправки запросов от конкретного клиента к
один и тот же бэкэнд до тех пор, пока бэкэнд исправен и имеет емкость,
в соответствии с настроенным режимом балансировки.
При использовании сходства сеансов мы рекомендуем режим балансировки RATE , а не
чем ИСПОЛЬЗОВАНИЕ . Сходство сеансов работает лучше всего, если вы установите режим балансировки
запросов в секунду (RPS).
Балансировка нагрузки HTTP(S) предлагает следующие типы сходство сеансов:
В следующей таблице приведены поддерживаемые параметры сходства сеансов для каждого режим балансировки нагрузки HTTP(S):
| Режим балансировки нагрузки | Параметры привязки сеанса | ||||
|---|---|---|---|---|---|
| Нет | IP-адрес клиента | Сгенерированный файл cookie | Поле заголовка | Файл cookie HTTP | |
| Глобальный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | |||||
| Глобальный внешний балансировщик нагрузки HTTP(S) (классический) | |||||
| Региональный внешний балансировщик нагрузки HTTP(S) (Предварительный просмотр) | |||||
Поддержка HTTP/2
Максимальное количество одновременных потоков HTTP/2
HTTP/2 SETTINGS_MAX_CONCURRENT_STREAMS настройка описывает максимальное количество потоков, которые принимает конечная точка,
по инициативе сверстника. Значение, объявленное клиентом HTTP/2 для
Балансировщик нагрузки Google Cloud фактически бесполезен, потому что нагрузка
балансировщик не инициирует потоки для клиента.
Значение, объявленное клиентом HTTP/2 для
Балансировщик нагрузки Google Cloud фактически бесполезен, потому что нагрузка
балансировщик не инициирует потоки для клиента.
В случаях, когда балансировщик нагрузки использует HTTP/2 для связи с сервером
который работает на виртуальной машине, балансировщик нагрузки учитывает SETTINGS_MAX_CONCURRENT_STREAMS значение, объявленное сервером. Если значение
объявлен ноль, балансировщик нагрузки не может пересылать запросы на сервер, и
это может привести к ошибкам.
Ограничения HTTP/2
- HTTP/2 между балансировщиком нагрузки и экземпляром может требуют значительно больше TCP-соединений с экземпляром, чем HTTP(S). Объединение соединений, оптимизация, уменьшающая количество соединения с HTTP(S), в настоящее время недоступен с HTTP/2.
- HTTP/2 между балансировщиком нагрузки и серверной частью не поддерживает запуск
Протокол WebSocket через один поток соединения HTTP/2 (RFC
8441).
- HTTP/2 между балансировщиком нагрузки и серверной частью не поддерживает отправку на сервер.
- Частота ошибок gRPC и объем запросов не видны в Google Cloud API или облачная консоль. Если конечная точка gRPC возвращает ошибку, журналы балансировщика нагрузки и данные мониторинга сообщают о HTTP «ОК 200» код ответа.

Ограничения
- Балансировщики нагрузки HTTPS не поддерживают проверку подлинности на основе сертификатов клиентов, также известная как взаимная аутентификация TLS.
- Балансировщики нагрузки HTTPS не отправляют закрытие
close_notifyоповещение, когда завершение SSL-соединений.То есть балансировщик нагрузки закрывает TCP подключение вместо выполнения отключения SSL. - Балансировщики нагрузки HTTPS поддерживают только символы нижнего регистра в
домены в атрибуте общего имени (
CN) или атрибут альтернативного имени субъекта (SAN) сертификата. Сертификаты
с прописными буквами в доменах возвращаются только в том случае, если они установлены в качестве
первичный сертификат в
целевой прокси. Балансировщики нагрузки HTTPS - не используют расширение Server Name Indication (SNI) при подключении к бэкенду, кроме балансировщиков нагрузки с интернетом NEG бэкенды.Дополнительные сведения см. в разделе Шифрование от балансировщика нагрузки до бэкенды.
- Когда Google Cloud Armor используется с глобальным внешним балансировщиком нагрузки HTTP(S) с расширенными возможностями управления трафиком,
определенные взаимодействия между правилами Google Cloud Armor и
EXTERNAL_MANAGEDсерверные службы могут привести к тайм-ауту HTTP 408, особенно когда запросы включать тела POST.
 Сертификаты
с прописными буквами в доменах возвращаются только в том случае, если они установлены в качестве
первичный сертификат в
целевой прокси.
Сертификаты
с прописными буквами в доменах возвращаются только в том случае, если они установлены в качестве
первичный сертификат в
целевой прокси.Что дальше
Балансировщики сетевой нагрузки— эластичная балансировка нагрузки
Балансировщик нагрузки служит единой точкой контакта для клиентов. Клиенты отправляют запросы балансировщику нагрузки, а балансировщик нагрузки отправляет их целевым объектам,
таких как экземпляры EC2, в одной или нескольких зонах доступности.
Клиенты отправляют запросы балансировщику нагрузки, а балансировщик нагрузки отправляет их целевым объектам,
таких как экземпляры EC2, в одной или нескольких зонах доступности.
Чтобы настроить балансировщик нагрузки, вы создаете целевые группы, а затем регистрируете цели в своих целевых группах. Ваш груз балансировщик наиболее эффективен, если вы убедитесь, что каждая включенная зона доступности имеет по крайней мере одна зарегистрированная цель. Вы также создаете прослушиватели для проверки запросов на подключение от клиентов и маршрутизации запросов от клиентов к целям в ваших целевых группах.Балансировщики сетевой нагрузки
поддерживают подключения от клиентов через пиринг VPC, управляемую AWS VPN, AWS Direct Connect и сторонние VPN-решения.
Состояние балансировщика нагрузки
Балансировщик нагрузки может находиться в одном из следующих состояний:
-
обеспечение Балансировщик нагрузки настраивается.
-
активный Балансировщик нагрузки полностью настроен и готов к маршрутизации трафика.
-
ошибка Балансировщик нагрузки не может быть настроен.
Атрибуты балансировщика нагрузки
Ниже приведены атрибуты балансировщика нагрузки:
-
журналы_доступа.s3.enabled Указывает, включены ли журналы доступа, хранящиеся в Amazon S3. По умолчанию
ложь.-
access_logs. s3.bucket Имя корзины Amazon S3 для журналов доступа. Этот атрибут требуется, если журналы доступа включены. Дополнительные сведения см. в разделе Требования к корзине.
-
access_logs.s3.prefix Префикс местоположения в корзине Amazon S3.
-
удаление_защиты.включено Указывает, будет ли удаление защита включена. По умолчанию
false.-
ipv6.deny_all_igw_traffic Блокирует доступ интернет-шлюза (IGW) к балансировщику нагрузки, предотвращая непреднамеренный доступ к вашему внутреннему балансировщику нагрузки через Интернет шлюз. Для балансировщиков нагрузки, подключенных к Интернету, установлено значение
false. иtrueдля внутренних балансировщиков нагрузки. Этот атрибут не предотвратить доступ в Интернет без IGW (например, через пиринг, транзитный шлюз, AWS Direct Connect или AWS VPN).-
load_balancing.cross_zone.enabled Указывает, является ли кросс-зона Балансировка нагрузки включена. По умолчанию
ложь.
 s3.bucket
s3.bucket Тип IP-адреса
Вы можете установить типы IP-адресов, которые клиенты могут использовать с вашим балансировщиком нагрузки.
Ниже приведены типы IP-адресов:
-
IPv4 Клиенты должны подключаться к балансировщику нагрузки, используя адреса IPv4 (для например, 192.0.2.1). Балансировщики нагрузки с поддержкой IPv4 (как с выходом в Интернет, так и с internal) поддерживают прослушиватели TCP, UDP, TCP_UDP и TLS.
-
двойной стек Клиенты могут подключаться к балансировщику нагрузки, используя оба адреса IPv4 (для пример 192.0.2.1) и адреса IPv6 (например, 2001:0db8:85a3:0:0:8a2e:0370:7334). Балансировщики нагрузки с поддержкой Dualstack (оба доступ к Интернету и внутренний) поддерживают прослушиватели TCP и TLS.
Особенности балансировки нагрузки Dualstack
Балансировщик нагрузки связывается с целями на основе типа IP-адреса целевая группа.
При включении режима двойного стека для балансировщика нагрузки Elastic Load Balancing предоставляет AAAA Запись DNS для балансировщика нагрузки. Клиенты, взаимодействующие с нагрузкой балансировщик, использующий адреса IPv4, разрешает запись A DNS. Клиенты, которые общаются с балансировщиком нагрузки, использующим адреса IPv6, разрешает запись DNS AAAA.
Доступ к вашим внутренним балансировщикам нагрузки с двумя стеками через интернет-шлюз заблокирован для предотвращения непреднамеренного доступа в Интернет.Однако это не мешает доступ в Интернет без IWG (например, через пиринг, Transit Gateway, AWS Direct Connect или АВС VPN).
Дополнительные сведения о типах IP-адресов балансировщика нагрузки см. в разделе Обновление адреса тип.
Зоны доступности
Вы включаете одну или несколько зон доступности для балансировщика нагрузки при его создании.Если вы включите несколько зон доступности для балансировщика нагрузки, это увеличит отказоустойчивость ваших приложений. Вы не можете отключить зоны доступности для балансировщика сетевой нагрузки. после его создания, но вы можете включить дополнительные зоны доступности.
При включении зоны доступности вы указываете одну подсеть из этой зоны доступности. Зона. Elastic Load Balancing создает узел балансировки нагрузки в зоне доступности и сети. интерфейс для подсети (описание начинается с «ELB net» и включает имя балансировщик нагрузки).Каждый узел балансировщика нагрузки в зоне доступности использует эту сеть. интерфейс для получения адреса IPv4. Обратите внимание, что вы можете просматривать этот сетевой интерфейс, но вы не может его изменить.
При создании балансировщика нагрузки с выходом в Интернет можно дополнительно указать один Эластичный IP-адрес для каждой подсети. Если вы не выберете один из собственных эластичных IP-адресов Elastic Load Balancing предоставляет вам один эластичный IP-адрес на подсеть. Эти эластичные IP-адреса адреса предоставляют вашему балансировщику нагрузки статические IP-адреса, которые не будут меняться в течение срока службы балансировщика нагрузки.Вы не можете изменить эти эластичные IP-адреса после вы создаете балансировщик нагрузки.
При создании внутреннего балансировщика нагрузки можно дополнительно указать один частный IP-адрес. адрес в подсети. Если вы не укажете IP-адрес из подсети, Elastic Load Balancing выбирает один для тебя. Эти частные IP-адреса предоставляют вашему балансировщику нагрузки статический IP-адрес. адреса, которые не изменятся в течение срока службы балансировщика нагрузки. Вы не можете изменить эти частные IP-адреса после создания балансировщика нагрузки.
Требования
Для балансировщиков нагрузки с выходом в Интернет указанные подсети должны иметь не менее 8 доступных IP-адресов. Для внутренних балансировщиков нагрузки это только требуется, если вы разрешите AWS выбрать частный IPv4-адрес из подсети.
Вы не можете указать подсеть в ограниченной зоне доступности.Ошибка сообщение «Балансировщики нагрузки с типом «сеть» не поддерживаются в az_name «. Можно указать подсеть в другом Зона доступности без ограничений и балансировка нагрузки между зонами для распределять трафик по целям в ограниченной зоне доступности.
Вы не можете указать подсеть в локальной зоне.
После включения зоны доступности подсистема балансировки нагрузки начинает перенаправлять запросы на зарегистрированные цели в этой зоне доступности.Ваш балансировщик нагрузки наиболее эффективен если вы убедитесь, что в каждой включенной зоне доступности есть хотя бы один зарегистрированный цель.
Чтобы добавить зоны доступности с помощью консоли
Откройте консоль Amazon EC2 по адресу https://console.aws.amazon.com/ec2/.
На панели навигации в разделе БАЛАНСИРОВКА НАГРУЗКИ выберите Балансировщики нагрузки .
Выберите балансировщик нагрузки.
На вкладке Description в разделе Basic Конфигурация , выберите Редактировать подсети .
Чтобы включить зону доступности, установите флажок для этой зоны доступности. Зона. Если для этой зоны доступности имеется одна подсеть, она выбирается. Если в этой зоне доступности несколько подсетей, выберите один из подсети.Обратите внимание, что вы можете выбрать только одну подсеть для каждой зоны доступности.
Для балансировщика нагрузки с выходом в Интернет можно выбрать эластичный IP-адрес для каждой зоны доступности. Для внутреннего балансировщика нагрузки можно назначить частный IP-адрес из диапазона IPv4 каждой подсети вместо того, чтобы позволять Elastic Load Balancing назначать один.
Выберите Сохранить .
Чтобы добавить зоны доступности с помощью интерфейса командной строки AWS
Использовать набор подсетей команда.
Балансировка нагрузки между зонами
По умолчанию каждый узел балансировщика нагрузки распределяет трафик между зарегистрированными целями. только в своей зоне доступности. Если вы включите балансировку нагрузки между зонами, каждая нагрузка узел балансировщика распределяет трафик по зарегистрированным таргетам во всех включенных Зоны доступности. Дополнительные сведения см. в разделе Балансировка нагрузки между зонами в Elastic Load Balancing Руководство пользователя .
Чтобы включить балансировку нагрузки между зонами с помощью консоли
Откройте консоль Amazon EC2 по адресу https://console.aws.amazon.com/ec2/.
На панели навигации в разделе БАЛАНСИРОВКА НАГРУЗКИ выберите Балансировщики нагрузки .
Выберите балансировщик нагрузки.
Выбрать Описание , Редактировать атрибуты .
В диалоговом окне Изменить атрибуты балансировщика нагрузки выберите Включить для Перекрестная нагрузка балансировка и выберите Сохранить .
Чтобы отключить балансировку нагрузки между зонами с помощью консоли
Выполните описанные выше действия с шага 1 по шаг 4. Затем в окне Редактировать загрузку диалоговое окно атрибутов балансировщика , очистить Включить из Балансировка нагрузки между зонами и выберите Сохранить .
Включение или отключение балансировки нагрузки между зонами с помощью интерфейса командной строки AWS
Используйте команду change-load-balancer-attributes с параметром атрибут load_balancing.cross_zone.enabled , где возможно
значения true (для включения балансировки нагрузки между зонами) и false (для отключения балансировки нагрузки между зонами). По умолчанию ложь .
Защита от удаления
Чтобы предотвратить случайное удаление вашего балансировщика нагрузки, вы можете включить удаление защита. По умолчанию защита от удаления для балансировщика нагрузки отключена.
Если вы включаете защиту от удаления для балансировщика нагрузки, вы должны отключить ее перед вы можете удалить балансировщик нагрузки.
Чтобы включить защиту от удаления с помощью консоли
Откройте консоль Amazon EC2 по адресу https://консоль.aws.amazon.com/ec2/.
На панели навигации в разделе БАЛАНСИРОВКА НАГРУЗКИ выберите Балансировщики нагрузки .
Выберите балансировщик нагрузки.
Выбрать Описание , Редактировать атрибуты .
На странице Изменить атрибуты балансировщика нагрузки выберите Включить для Удалить защиту и выберите Сохранить .
Чтобы отключить защиту от удаления с помощью консоли
Откройте консоль Amazon EC2 по адресу https://console.aws.amazon.com/ec2/.
На панели навигации в разделе БАЛАНСИРОВКА НАГРУЗКИ выберите Балансировщики нагрузки .
Выберите балансировщик нагрузки.
Выбрать Описание , Редактировать атрибуты .
На странице Изменить атрибуты балансировщика нагрузки снимите флажок Включите защиту от удаления и выберите Сохранить .
Включение или отключение защиты от удаления с помощью интерфейса командной строки AWS
Используйте команду change-load-balancer-attributes с параметром удаление_защита.включен атрибут .
Тайм-аут простоя соединения
Для каждого TCP-запроса, который клиент делает через Network Load Balancer, состояние этого соединения отслеживается. Если данные не отправляются через соединение ни клиентом, ни целью для дольше, чем тайм-аут простоя, соединение закрывается. Если клиент или цель отправляет данные после истечения периода простоя, он получает пакет TCP RST, чтобы указать что соединение больше не действует.
Elastic Load Balancing устанавливает значение времени простоя для потоков TCP равным 350 секундам. Вы не можете изменить это ценность. Клиенты или цели могут использовать пакеты проверки активности TCP для сброса тайм-аута простоя. Пакеты проверки активности, отправляемые для поддержания соединений TLS, не могут содержать данные или полезная нагрузка.
Пока UDP не устанавливает соединение, балансировщик нагрузки поддерживает состояние потока UDP на основе исходный и конечный IP-адреса и порты, гарантируя, что пакеты, принадлежащие один и тот же поток последовательно отправляется на одну и ту же цель.После периода простоя истекает, балансировщик нагрузки рассматривает входящий UDP-пакет как новый поток и направляет его к новой цели. Эластичная балансировка нагрузки устанавливает значение тайм-аута простоя для потоков UDP равным 120 секундам.
экземпляра EC2 должны ответить на новый запрос в течение 30 секунд, чтобы установить Обратный путь.
DNS-имя
Каждый компонент Network Load Balancer получает имя системы доменных имен (DNS) по умолчанию со следующим синтаксисом: имя — идентификатор .откос регион .amazonaws.com.
Например,
my-load-balancer-1234567890abcdef.elb.us-east-2.amazonaws.com.
Если вы предпочитаете использовать DNS-имя, которое легче запомнить, вы можете создать доменное имя и свяжите его с DNS-именем балансировщика нагрузки. Когда клиент делает запрос, используя это пользовательское доменное имя, DNS-сервер разрешает его в DNS имя вашего балансировщика нагрузки.
Сначала зарегистрируйте доменное имя у аккредитованного регистратора доменных имен.Далее используйте свой Служба DNS, например регистратор вашего домена, для создания записи CNAME для маршрутизации запросов. к вашему балансировщику нагрузки. Дополнительные сведения см. в документации по службе DNS. Например, вы можете использовать Amazon Route 53 в качестве службы DNS. Дополнительные сведения см. в разделе Маршрутизация трафика на нагрузку ELB. балансировщик в Руководстве разработчика Amazon Route 53 .
Балансировщик нагрузки имеет один IP-адрес для каждой включенной зоны доступности.Эти
адреса узлов балансировщика нагрузки. DNS-имя балансировщика нагрузки разрешается в
эти адреса. Например, предположим, что имя пользовательского домена для балансировщика нагрузки example.networkloadbalancer.com . Используйте следующее dig или nslookup команда для определения IP
адреса узлов балансировщика нагрузки.
Linux или Mac
$ копать + короткий пример.networkloadbalancer.com Windows
C:\> nslookup example.networkloadbalancer.com Балансировщик нагрузки имеет записи DNS для своих узлов балансировщика нагрузки. Вы можете использовать DNS-имена
со следующим синтаксисом для определения IP-адресов узлов балансировщика нагрузки: аз . имя — идентификатор .elb. регион .amazonaws.com.
Linux или Mac
$ dig +short us-east-2b.my-load-balancer-1234567890abcdef.elb.us-east-2.amazonaws.com Windows
C:\> nslookup us-east-2b.my-load-balancer-1234567890abcdef.elb.us-east-2.amazonaws.com Распределение нагрузки с BGP в односетевых и многосетевых средах
Введение
В этом документе описывается распределение нагрузки, которое позволяет маршрутизатору распределять исходящий и входящий трафик по нескольким путям.Пути получаются либо статически, либо с помощью динамических протоколов, таких как:
Протокол маршрутной информации (RIP)
Расширенный протокол маршрутизации внутреннего шлюза (EIGRP)
Открытый протокол кратчайшего пути (OSPF)
Протокол маршрутизации внутреннего шлюза (IGRP)
По умолчанию протокол пограничного шлюза (BGP) выбирает только один лучший путь и не выполняет балансировку нагрузки.В этом документе показано, как выполнять распределение нагрузки в различных сценариях с использованием BGP. Дополнительные сведения о балансировке нагрузки см. в разделе Как работает балансировка нагрузки?.
Предпосылки
Требования
Убедитесь, что вы соответствуете этим требованиям, прежде чем пытаться выполнить эту настройку:
Используемые компоненты
Этот документ не ограничен конкретными версиями программного и аппаратного обеспечения.
Информация в этом документе была создана из устройств в специальной лабораторной среде.Все устройства, используемые в этом документе, запускались с очищенной (по умолчанию) конфигурацией. Если ваша сеть работает, убедитесь, что вы понимаете потенциальное влияние любой команды.
Распределение нагрузки с петлевым адресом в качестве соседа BGP
В этом сценарии показано, как добиться распределения нагрузки при наличии нескольких (максимум до шести) каналов с одинаковой стоимостью. Каналы заканчиваются на одном маршрутизаторе в локальной автономной системе (AS) и на другом маршрутизаторе в удаленной AS в односетевой среде BGP.Сетевая диаграмма служит примером.
Схема сети
В этом разделе используется следующая настройка сети:
Конфигурации
В этом разделе используются следующие конфигурации:
МаршрутизаторA
петля интерфейса 0 IP-адрес 1.1.1.1 255.255.255.0 серийный номер интерфейса 0 IP-адрес 160.20.20.1 255.255.255.0 нет ip route-cache серийный номер интерфейса 1 IP-адрес 150.10.10.1 255.255.255.0 нет ip route-cache маршрутизатор бгп 11 сосед 2.2.2.2 удаленный-как 10 сосед 2.2.2.2 петля источника обновления 0 !--- Используйте IP-адрес loopback-интерфейса для соединений TCP.>сосед 2.2.2.2 ebgp-multihop !--- Вы должны настраивать ebgp-multihop каждый раз, когда внешние соединения BGP (eBGP)
!--- не находятся на одном и том же сетевом адресе.eigrp маршрутизатора 12
сеть 1.0.0.0
сеть 150.10.0.0
сеть 160.20.0.0нет автоматического суммирования
Маршрутизатор B
петля интерфейса 0 айпи адрес 2.2.2.2 255.255.255.0 серийный номер интерфейса 0 IP-адрес 160.20.20.2 255.255.255.0 нет ip route-cache серийный номер интерфейса 1 IP-адрес 150.10.10.2 255.255.255.0 нет ip route-cache маршрутизатор бгп 10 сосед 1.1.1.1 удаленный-как 11 сосед 1.1.1.1 петля источника обновления 0 !--- Использовать IP-адрес loopback-интерфейса для соединений TCP.сосед 1.1.1.1 ebgp-multihop !--- Вы должны настроить ebgp-multihop всякий раз, когда соединения eBGP
!--- не находятся на одном и том же сетевом адресе.eigrp маршрутизатора 12
сеть 2.0.0.0
сеть 150.10.0.0
сеть 160.20.0.0нет автоматического суммирования
Примечание : вы можете использовать статические маршруты вместо протокола маршрутизации, чтобы ввести два пути с одинаковой стоимостью для достижения пункта назначения. В данном случае протокол маршрутизации — EIGRP.
Проверить
Используйте этот раздел, чтобы убедиться, что ваша конфигурация работает правильно.
Cisco CLI Analyzer (только для зарегистрированных клиентов) поддерживает определенные команды show .Используйте Cisco CLI Analyzer для просмотра анализа выходных данных команды show .
Выходные данные команды show ip route показывают, что оба пути к сети 2.2.2.0 получены через EIGRP. Выходные данные команды traceroute показывают, что нагрузка распределяется между двумя последовательными каналами. В этом сценарии распределение нагрузки происходит для каждого пакета. Вы можете выполнить команду ip route-cache на последовательных интерфейсах, чтобы выполнить распределение нагрузки для каждого пункта назначения.Вы также можете настроить балансировку нагрузки для каждого пакета и для каждого пункта назначения с помощью Cisco Express Forwarding. Дополнительные сведения о настройке Cisco Express Forwarding см. в разделе Настройка Cisco Express Forwarding.
RouterA# показать IP-маршрут !--- Вывод подавлен. Шлюз последней инстанции не установлен2.2.0 [90/2297856] via 150.10.10.2, 00:00:45, Serial1
[90/2297856] via 160.20.20.2, 00:00:45, Serial0
160.20.0.0/24 разделен на подсети, 1 подсеть
C 160.20.20.0 подключен напрямую, Serial0
150.10.0.0/24 разделен на подсети, 1 подсеть
C 150.10.10.0 подключен напрямую, Serial1RouterA# traceroute 2.2.2.2 Введите escape-последовательность, чтобы прервать. Отслеживание маршрута до 2.2.2.2 1 160.20.20.2 16 мс 150.10.10.2 8 мс *
Устранение неполадок
В настоящее время нет конкретной информации по устранению неполадок для этой конфигурации.
Распределение нагрузки при двойном подключении к одному интернет-провайдеру (ISP) через один локальный маршрутизатор
В этом сценарии показано, как добиться распределения нагрузки при наличии нескольких каналов связи между удаленной AS и локальной AS. Эти каналы заканчиваются на одном маршрутизаторе в локальной AS и на нескольких маршрутизаторах в удаленных AS в односетевой среде BGP. Сетевая диаграмма является примером такой сети.
В этом примере конфигурации используется команда max-paths .По умолчанию BGP выбирает один лучший путь из возможных путей равной стоимости, полученных от одной AS. Однако вы можете изменить максимально допустимое количество параллельных путей равной стоимости. Чтобы внести это изменение, включите команду max-paths paths в конфигурацию BGP. Используйте число от 1 до 6 для аргумента путей .
Схема сети
В этом разделе используется следующая настройка сети:
Конфигурации
В этом разделе используются следующие конфигурации:
МаршрутизаторA
интерфейс Loopback0 айпи адрес 1.1.1.1 255.255.255.0 ! Интерфейс Серийный 0 IP-адрес 160.20.20.1 255.255.255.0 ! ! интерфейс серийный 1 IP-адрес 150.10.10.1 255.255.255.0 ! ! маршрутизатор бгп 11 сосед 160.20.20.2 удаленный-как 10 сосед 150.10.10.2 удаленный-как 10 сеть 1.0.0.0 максимальные пути 2 !--- Эта команда задает максимальное количество путей
!--- для установки в таблице маршрутизации для определенного пункта назначения.
Маршрутизатор B
интерфейс Ethernet0 IP-адрес 2.2.2.1 255.255.255.0 ! Интерфейс Серийный 0 IP-адрес 160.20.20.2 255.255.255.0 ! ! маршрутизатор бгп 10 сосед 160.20.20.1 удаленный-как 11 сеть 2.0.0.0 автосуммирование
МаршрутизаторC
интерфейс Ethernet0 IP-адрес 2.2.2.2 255.255.255.0 ! интерфейс серийный 1 IP-адрес 150.10.10.2 255.255.255.0 ! ! маршрутизатор бгп 10 сосед 150.10.10.1 удаленный-как 11 сеть 2.0.0.0 автосуммирование
Проверить
Используйте этот раздел, чтобы убедиться, что ваша конфигурация работает правильно.
Cisco CLI Analyzer (только для зарегистрированных клиентов) поддерживает определенные команды show . Используйте Cisco CLI Analyzer для просмотра анализа выходных данных команды show .
Выходные данные команды show ip route показывают, что оба пути к сети 2.2.2.0 получены через BGP. Выходные данные команды traceroute показывают, что нагрузка распределяется между двумя последовательными каналами. В этом сценарии распределение нагрузки происходит для каждого пункта назначения.Команда show ip bgp дает допустимые записи для сети 2.0.0.0.
RouterA# показать IP-маршрут !--- Выход подавленШлюз последней инстанции не установлен
1.0.0.0/24 разделен на подсети, 1 подсеть
C 1.1.1.0 подключен напрямую, Loopback0
B 2.0.0.0/8 [20/0 ] через 150.10.10.2, 00:04:23 [20/0] via 160.20.20.2, 00:04:01
160.20.0.0/24 разделен на подсети, 1 подсеть C 160.20.20.0 подключен напрямую, Serial0 150.10.0.0/24 разделен на подсети, 1 подсеть C 150.10.10.0 подключен напрямую, Serial1 RouterA# traceroute 2.2.2.2 Введите escape-последовательность, чтобы прервать. Отслеживание маршрута до 2.2.2.2 1 160.20.20.2 16 мс 150.10.10.2 8 мс * RouterA# показать ip bgp Версия таблицы BGP — 3, идентификатор локального маршрутизатора — 1.1.1.1. Коды состояния: S подавленные, D демпфированные, H истории, * Действительно,> Лучший, я - внутренний Коды происхождения: i - IGP, e - EGP, ? - неполный Сеть Метрика следующего перехода LocPrf Вес Путь *> 1.0.0.0 0.0.0.0 0 32768 я *> 2.0.0.0 160.20.20.2 0 0 10 я * 150.10.10.2 0 0 10 я
Устранение неполадок
В настоящее время нет конкретной информации по устранению неполадок для этой конфигурации.
Распределение нагрузки При двойным подключением к одному провайдеру через несколько локальных маршрутизаторов
Этот сценарий показывает, как добиться распределения нагрузки при наличии несколько подключений к одной ISP через несколько локальных маршрутизаторов.Два EBGP коллег заканчиваются на два отдельных локальных маршрутизаторах. Балансировка нагрузки по двум линиям, не возможно, потому что BGP выбирает единственный наилучший путь среди сетей, которые извлечены из EBGP и внутреннего протокола BGP (IBGP). Распределение нагрузки между несколькими путями к AS 10 является следующим лучшим вариантом. При этом типе распределения нагрузки, трафика конкретных сетей, на основе заранее определенных политик, проходит через обе ссылки. Кроме того, каждое звено действует в качестве резервной копии на другой линии связи, в случае, если одна ссылка терпит неудачу.
Для простоты предположим, что политика маршрутизации BGP для AS 11:
AS 11 принимает локальные маршруты от AS 10, а также маршруты по умолчанию для остальных интернет-маршрутов.
Политика исходящего трафика:
Весь трафик, направляемый в Интернет от R101, выходит через канал R101-R103.
В случае сбоя соединения R101-R103 весь трафик в Интернет от R101 проходит через R102 к AS 10.
Аналогично, весь трафик, направляемый в Интернет от R102, проходит по каналу R102-R104.
В случае сбоя соединения R102-R104 весь трафик в Интернет от R102 проходит через R101 к AS 10.
Политика входящего трафика:
Трафик, предназначенный для сети 192.168.11.0/24 из Интернета, должен поступать по каналу R103-R101.
Трафик, предназначенный для сети 192.168.12.0/24 из интернета должен исходить из ссылки R104-R102.
Если одна ссылка на AS 10 выходит из строя, то другая ссылка должна направлять трафик, предназначенный для всех сетей, обратно в AS 11 из Интернета.
Для этого 192.168.11.0 объявляется с R101 по R103 с более коротким AS_PATH, чем объявляется с R102 по R104. AS 10 находит лучший путь по каналу R103-R101. Точно так же объявляется 192.168.12.0 с более коротким путем по каналу R102-R104.AS 10 предпочитает канал R104-R102 для трафика, привязанного к 192.168.12.0 в AS 11.
Для исходящего трафика BGP определяет лучший путь на основе маршрутов, полученных через eBGP. Эти маршруты предпочтительнее маршрутов, полученных через iBGP. Итак, R101 узнает 10.10.34.0 от R103 через eBGP и от R102 через iBGP. Внешний путь выбирается вместо внутреннего пути. Итак, если вы посмотрите на таблицу BGP в конфигурации R101, маршрут к 10.10.34.0 будет проходить через канал R101-R103 со следующим узлом 10.10.13.3. На R102 маршрут к 10.10.34.0 будет проходить через канал R102-R104 со следующим узлом 10.10.24.4. Это обеспечивает распределение нагрузки для трафика, предназначенного для 10.10.34.0. Аналогичные рассуждения применимы к маршрутам по умолчанию на R101 и R102. Для получения дополнительной информации о критериях выбора пути BGP см. Алгоритм выбора оптимального пути BGP.
Схема сети
В этом разделе используется следующая настройка сети:
Конфигурации
В этом разделе используются следующие конфигурации:
Р101
имя хоста R101 ! интерфейс Ethernet0/0 айпи адрес 192.168.11.1 255.255.255.0 вторичный IP-адрес 192.168.12.1 255.255.255.0 ! интерфейс Serial8/0 IP-адрес 10.10.13.1 255.255.255.0 ! маршрутизатор бгп 11 нет синхронизации bgp log-neighbour-changes сеть 192.168.11.0 сеть 192.168.12.0 сосед 10.10.13.3 удаленный-как 10 сосед 10.10.13.3 карта маршрутов R101-103-MAP исходящий !--- AS_PATH увеличен для 192.168.12.0. сосед 192.168.12.2 удаленный-как 11 сосед 192.168.12.2 следующий переход максимальные пути 2 нет автоматического суммирования ! список доступа 1 разрешение 192.168.12.0 разрешение списка доступа 2 192.168.11.0 маршрут-карта R101-103-MAP разрешение 10 совпадать с IP-адресом 1 установить как путь перед 11 11 11 ! маршрут-карта R101-103-MAP разрешение 20 соответствует IP-адресу 2
Р102
имя хоста R102 ! интерфейс Ethernet0/0 IP-адрес 192.168.11.2 255.255.255.0 вторичный IP-адрес 192.168.12.2 255.255.255.0 ! интерфейс Serial8/0 IP-адрес 10.10.24.2 255.255.255.0 ! маршрутизатор бгп 11 нет синхронизации bgp log-neighbour-changes сеть 192.168.0.11,0 сеть 192.168.12.0 сосед 10.10.24.4 удаленный-как 10 сосед 10.10.24.4 route-map R102-104-MAP out !--- AS_PATH увеличен для 192.168.11.0. сосед 192.168.12.1 удаленный-как 11 сосед 192.168.12.1 следующий переход нет автоматического суммирования ! список доступа 1 разрешение 192.168.11.0 разрешение списка доступа 2 192.168.12.0 маршрут-карта R102-104-MAP разрешение 10 совпадать с IP-адресом 1 установить как путь перед 11 11 11 ! маршрут-карта R102-104-MAP разрешение 20 совпадать с IP-адресом 2 !
Р103
имя хоста R103 ! интерфейс Ethernet0/0 айпи адрес 10.10.34.3 255.255.255.0 ! интерфейс Serial8/0 IP-адрес 10.10.13.3 255.255.255.0 ! маршрутизатор бгп 10 нет синхронизации bgp log-neighbour-changes сеть 10.10.34.0 маска 255.255.255.0 сосед 10.10.13.1 удаленный-как 11 сосед 10.10.13.1 источник по умолчанию сосед 10.10.34.4 удаленный-как 10 сосед 10.10.34.4 следующий переход сам нет автоматического суммирования !
Р104
имя хоста R104 ! интерфейс Ethernet0/0 IP-адрес 10.10.34.4 255.255.255.0 ! интерфейс Serial8/0 айпи адрес 10.10.24.4 255.255.255.0 ! маршрутизатор бгп 10 нет синхронизации bgp log-neighbour-changes сосед 10.10.24.2 удаленный-как 11 сосед 10.10.24.2 источник по умолчанию сосед 10.10.34.3 удаленный-как 10 сосед 10.10.34.3 сам-следующий переход нет автоматического суммирования !
Проверить
В этом разделе содержится информация, которую можно использовать для проверки правильности работы конфигурации.
Определенные команды show поддерживаются Cisco CLI Analyzer (только для зарегистрированных клиентов), который позволяет просматривать анализ выходных данных команды show .
Проверка, когда обе ссылки между AS 11 и AS 10 активны
Проверка исходящего трафика
Примечание : Знак «больше» (>) в выходных данных команды show ip bgp представляет лучший путь для использования в этой сети среди возможных путей. Дополнительную информацию см. в разделе Алгоритм выбора оптимального пути BGP.
Таблица BGP в R101 показывает, что лучший путь для всего исходящего трафика в Интернет — это канал R101-R103.Выходные данные команды show ip route подтверждают наличие маршрутов в таблице маршрутизации.
R101# показать IP BGP Версия таблицы BGP — 5, идентификатор локального маршрутизатора — 192.168.12.1. Коды состояния: s подавлен, d демпфирован, h история, * действительный, > лучший, i - внутренний Коды происхождения: i - IGP, e - EGP, ? - неполный Сеть Метрика следующего перехода LocPrf Вес Путь * i0.0.0.0 192.168.12.2 100 0 10 я *> 10.10.13.3 0 10 я !--- Это следующий шаг R103. * i10.10.34.0/24 192.168.12.2 100 0 10 я *> 10.10.13.3 0 0 10 я !--- Это следующий шаг R103. * i192.168.11.0 192.168.12.2 0 100 0 я *> 0.0.0.0 0 32768 я * i192.168.12.0 192.168.12.2 0 100 0 я *> 0.0.0.0 0 32768 я R101 # показать IP-маршрут !--- Вывод подавлен.Шлюз последней инстанции — 10.10.13.3 в сеть 0.0.0.0 C 192.168.12.0/24 подключен напрямую, Ethernet0/0 C 192.168.11.0/24 подключен напрямую, Ethernet0/0 10.0.0.0/24 разбит на подсети, 2 подсети C 10.10.13.0 подключен напрямую, Serial8/0 B 10.10.34.0 [20/0] через 10.10.13.3, 00:08:53 !--- Это следующий шаг R103.
B* 0.0.0.0/0 [20/0] через 10.10.13.3, 00:08:53 !--- Это следующий шаг R103.
Вот таблицы BGP и маршрутизации для R102. Согласно политике, R102 должен направлять весь трафик на AS 10 через канал R102-R104:
.R102# показать IP BGP Версия таблицы BGP — 7, идентификатор локального маршрутизатора — 192.168.12.2. Коды состояния: s подавлен, d демпфирован, h история, * действительный, > лучший, i - внутренний Коды происхождения: i - IGP, e - EGP, ? - неполный Сеть Метрика следующего перехода LocPrf Вес Путь *> 0.0.0.0 10.10.24.4 0 10 я !--- Это следующий шаг R104.* я 192.168.12.1 100 0 10 я *> 10.10.34.0/24 10.10.24.4 0 10 i !--- Это следующий шаг R104.
* я 192.168.12.1 0 100 0 10 я * i192.168.11.0 192.168.12.1 0 100 0 я *> 0.0.0.0 0 32768 я * и192.168.12.0 192.168.12.1 0 100 0 я *> 0.0.0.0 0 32768 я R102 # показать IP-маршрут !--- Вывод подавлен.
Шлюз последней инстанции — 10.10.24.4 в сеть 0.0.0.0 C 192.168.12.0/24 подключен напрямую, Ethernet0/0 C 192.168.11.0/24 подключен напрямую, Ethernet0/0 10.0.0.0/24 разбит на подсети, 2 подсети C 10.10.24.0 подключен напрямую, Serial8/0 B 10.10.34.0 [20/0] через 10.10.24.4, 00:11:21 !--- Это следующий шаг R104.
B* 0.0.0.0/0 [20/0] через 10.10.24.4, 00:11:21 !--- Это следующий шаг R104.
Проверка входящего трафика от AS 10 к AS 11
Сети 192.168.11.0 и 192.168.12.0 принадлежат AS 11. В соответствии с политикой AS 11 должен предпочитать канал R103-R101 для трафика, предназначенного для сети 192.168.11.0, и канал R104-R102 для трафика, предназначенного к сети 192.168.12.0.
R103# показать IP BGP
Версия таблицы BGP — 4, идентификатор локального маршрутизатора — 10.10.34.3.
Коды состояния: s подавлен, d демпфирован, h история, * действительный, > лучший, i - внутренний
Коды происхождения: i - IGP, e - EGP, ? - неполный
Сеть Метрика следующего перехода LocPrf Вес Путь
*> 10.10.34.0/24 0.0.0.0 0 32768 я
*> 192.168.11.0 10.10.13.1 0 0 11 я
!--- Следующий переход — R101.
* 192.168.12.0 10.10.13.1 0 0 11 11 11 11 я
*>i 10.10.34.4 0 100 0 11 i
!--- Следующий переход — R104.
R103# показать IP-маршрут
!--- Вывод подавлен.
Шлюз последней инстанции не установлен
Б 192.168.12.0/24 [200/0] через 10.10.34.4, 00:04:46
!--- Следующий переход — R104.
Б 192.168.11.0/24 [20/0] через 10.10.13.1, 00:04:46
!--- Следующий переход — R101.
10.0.0.0/24 разбит на подсети, 2 подсети
C 10.10.13.0 подключен напрямую, Serial8/0
C 10.10.34.0 подключен напрямую, Ethernet0/0 Лучший путь для сети 192.168.11.0 на маршрутизаторе R103 — через канал R103-R101, а лучший путь для сети 192.168.12.0 — через R104 к AS 11. В этом случае наилучший путь определяется по кратчайшей длине пути.
Аналогично, на R104 таблица BGP и маршрутизации выглядит так:
R104# показать IP BGP
Версия таблицы BGP — 13, идентификатор локального маршрутизатора — 10.10.34.4
Коды состояния: s подавлен, d демпфирован, h история, * действительный, > лучший, i - внутренний
Коды происхождения: i - IGP, e - EGP, ? - неполный
Сеть Метрика следующего перехода LocPrf Вес Путь
*>i10.10.34.0/24 10.10.34.3 0 100 0 я
*>i192.168.11.0 10.10.34.3 0 100 0 11 я
* 10.10.24.2 0 0 11 11 11 11 я
*> 192.168.12.0 10.10.24.2 0 0 11 я
R104# показать IP-маршрут
!--- Вывод подавлен.
Шлюз последней инстанции не установлен
Б 192.168.12.0/24 [20/0] через 10.10.24.2, 00:49:06
!--- Следующий переход — R102.
Б 192.168.11.0/24 [200/0] через 10.10.34.3, 00:07:36
!--- Следующий переход — R103.
10.0.0.0/24 разбит на подсети, 2 подсети
C 10.10.24.0 подключен напрямую, Serial8/0
C 10.10.34.0 подключен напрямую, Ethernet0/0 Проверка при сбое соединения R101-R103
При сбое канала R101-R103 весь трафик должен перенаправляться через R102.Эта диаграмма иллюстрирует это изменение:
Отключите канал R103-R101 на маршрутизаторе R103, чтобы смоделировать эту ситуацию.
R103(config)# последовательный интерфейс 8/0 R103(config-if)# выключение * 1 мая 00:52:33.379: %BGP-5-ADJCHANGE: сосед 10.10.13.1 Вниз флап интерфейса * 1 мая 00:52:35.311: %LINK-5-CHANGED: Интерфейс Serial8/0, изменено состояние на административно вниз * 1 мая 00:52:36.127: %LINEPROTO-5-UPDOWN: линейный протокол на интерфейсе Serial8/0 изменен состояние вниз
Проверьте исходящий маршрут к AS 10.
R101# показать IP BGP Версия таблицы BGP — 17, идентификатор локального маршрутизатора — 192.168.12.1. Коды состояния: s подавлен, d демпфирован, h история, * действительный, > лучший, i - внутренний Коды происхождения: i - IGP, e - EGP, ? - неполный Сеть Метрика следующего перехода LocPrf Вес Путь *>i0.0.0.0 192.168.12.2 100 0 10 я !--- Это следующий шаг R102.
*>i10.10.34.0/24 192.168.12.2 100 0 10 i
!--- Это следующий переход R102.* I192.168.11.0 192.168.12.2 0 100 0 I
*> 0.0.0.0 0 32768 I
* I192.168.12.0 192.168.12.2 0 100 0 I
*> 0,0.0,0 0 32768 IR101 # show ip route
!--- Вывод подавлен.
Шлюз последней инстанции 192.168.12.2 к сети 0.0.0.0
C 192.168.12.0/24 подключен напрямую, Ethernet0/0
C 192.168.11.0/24 напрямую подключен, Ethernet0/0
10.0.0.0/24 разделен на подсети, 1 подсеть
B 10.10.34.0 [200/0] через 192.168.12.2, 00:01:34
B* 0,0 .0.0/0 [200/0] via 192.168.12.2, 00:01:34
!--- Весь исходящий трафик проходит через R102.R102# показать IP-маршрут
!--- Вывод подавлен.
Шлюз последней инстанции 10.10.24.4 к сети 0.0.0.0
C 192.168.12.0/24 подключен напрямую, Ethernet0/0
C 192.168.11.0/24 напрямую подключен, Ethernet0/0
10.0.0.0/24 разделен на подсети, 2 подсети
C 10.10.24.0 напрямую подключен, Serial8/0
B 10.10.34.0 [20/0] через 10.10.24.4 , 00:13:22
B* 0.0.0.0/0 [20/0] via 10.10.24.4, 00:55:22
!--- Весь исходящий трафик на R102 проходит через R104.
Проверьте маршрут входящего трафика, когда R101-R103 не работает.
R103# показать IP BGP Версия таблицы BGP — 6, идентификатор локального маршрутизатора — 10.10.34.3 Коды состояния: s подавлен, d демпфирован, h история, * действительный, > лучший, i - внутренний Коды происхождения: i - IGP, e - EGP, ? - неполный Сеть Метрика следующего перехода LocPrf Вес Путь *> 10.10.34.0/24 0.0.0.0 0 32768 i *>i192.168.11.0 10.10.34.4 0 100 0 11 11 11 11 я *>i192.168.12.0 10.10.34.4 0 100 0 11 я R103# показать IP-маршрут !--- Вывод подавлен.
Шлюз последней инстанции не установленB 192.168.12.0/24 [200/0] via 10.10.34.4, 00:14:55
!--- Следующий переход — R104.B 192.168.11.0/24 [200/0] через 10.10.34.4, 00:05:46
!--- Следующий переход — R104.
10.0.0.0/24 разделен на подсети, 1 подсеть
C 10.10.34.0 подключен напрямую, Ethernet0/0
На R104 трафик для 192.168.11.0 и 192.168.12.0 проходит по каналу R104-R102.
R104# показать IP-маршрут !--- Вывод подавлен.Шлюз последней инстанции не установлен
B 192.168.12.0/24 [20/0] через 10.10.24.2, 00:58:35
!--- Следующий переход — R102.B 192.168.11.0/24 [20/0] через 10.10.24.2, 00:07:57
!--- Следующий переход — R102.10.0.0.0/24 разделен на подсети, 2 подсети
C 10.10.24.0 подключен напрямую, Serial8/0
C 10.10.34.0 подключен напрямую, Ethernet0/0
Устранение неполадок
В настоящее время нет конкретной информации по устранению неполадок для этой конфигурации.
Распределение нагрузки при многосетевом подключении к двум интернет-провайдерам через один локальный маршрутизатор
В этом сценарии балансировка нагрузки невозможна в многосетевой среде, поэтому можно только распределять нагрузку. Вы не можете выполнить балансировку нагрузки, потому что BGP выбирает только один лучший путь к месту назначения среди маршрутов BGP, полученных от разных AS.Идея состоит в том, чтобы установить лучшую метрику для маршрутов в диапазоне от 1.0.0.0 до 128.0.0.0, полученных от провайдера (A), и лучшую метрику для остальных маршрутов, полученных от провайдера (B). Сетевая диаграмма является примером.
Дополнительную информацию см. в разделе Образец конфигурации для BGP с двумя разными поставщиками услуг (многоадресная связь).
Схема сети
В этом разделе используется следующая настройка сети:
Конфигурации
В этом разделе используются следующие конфигурации:
МаршрутизаторA
интерфейс Серийный 0
айпи адрес 160.20.20.1 255.255.255.0
нет ip route-cache
интерфейс серийный 1
IP-адрес 150.10.10.1 255.255.255.0
нет ip route-cache
маршрутизатор бгп 11
сосед 160.20.20.2 удаленный-как 10
карта маршрутов соседа 160.20.20.2 ОБНОВЛЕНИЯ-1 в
!--- Разрешены только сети до 128.0.0.0.
сосед 150.10.10.2 удаленный-как 12
карта маршрутов соседа 150.10.10.2 ОБНОВЛЕНИЯ-2 в
!--- Это разрешает все, что выше сети 128.0.0.0.
авторезюме
карта маршрутов ОБНОВЛЕНИЯ-1 разрешение 10
совпадать с IP-адресом 1
установить вес 100
карта маршрутов ОБНОВЛЕНИЯ-1 разрешение 20
совпадать с IP-адресом 2
карта маршрутов ОБНОВЛЕНИЯ-2 разрешение 10
совпадать с IP-адресом 1
карта маршрута ОБНОВЛЕНИЯ-2 разрешение 20
совпадать с IP-адресом 2
установить вес 100
список доступа 1 разрешение 0.0.0.0 127.255.255.255
список доступа 2 запретить 0.0.0.0 127.255.255.255
список доступа 2 разрешает любой Маршрутизатор B
интерфейс Loopback0 IP-адрес 2.2.2.2 255.255.255.0 внутренняя петля 1 IP-адрес 170.16.6.5 255.255.255.0 Интерфейс Серийный 0 IP-адрес 160.20.20.2 255.255.255.0 нет ip route-cache маршрутизатор бгп 10 сосед 160.20.20.1 удаленный-как 11 сеть 2.0.0.0 сеть 170.16.0.0 автосуммирование
МаршрутизаторC
интерфейс Loopback0 айпи адрес 170.16.6.6 255.255.255.0 интерфейс Loopback1 IP-адрес 2.2.2.1 255.255.255.0 интерфейс серийный 1 IP-адрес 150.10.10.2 255.255.255.0 нет ip route-cache маршрутизатор бгп 12 сосед 150.10.10.1 удаленный-как 11 сеть 2.0.0.0 сеть 170.16.0.0 автосуммирование
Проверить
Используйте этот раздел, чтобы убедиться, что ваша конфигурация работает правильно.
Cisco CLI Analyzer (только для зарегистрированных клиентов) поддерживает определенные команды show . Используйте Cisco CLI Analyzer для просмотра анализа выходных данных команды show .
Выходные данные команды show ip route и выходные данные команды traceroute показывают, что любая сеть ниже 128.0.0.0 выходит из RouterA через 160.20.20.2. Этот маршрут является следующим переходом из интерфейса Serial 0. Остальные сети выходят через 150.10.10.2, который является следующим переходом из интерфейса Serial 1.
RouterA# показать IP-маршрут !--- Вывод подавлен.
Шлюз последней инстанции не установлен
B 170.16.0.0/16 [20/0] через 150.10.10.2, 00:43:43
!--- Это следующий переход через последовательный порт 1.B 2.0.0.0/8 [20/0 ] через 160.20.20.2, 00:43:43
!--- Это следующий переход через последовательный порт 0.160.20.0.0/24 разделен на подсети, 1 подсеть
C 160.20.20.0 подключен напрямую, Serial0
C 150.10.10.0 подключен напрямую, Serial1RouterA# show ip bgp
Версия таблицы BGP — 3, идентификатор локального маршрутизатора — 160.20.20.1 Коды состояния: s подавлен, d демпфирован, h история, * действительный, > лучший, i - внутренний Коды происхождения: i - IGP, e - EGP, ? - неполный Сеть Метрика следующего перехода LocPrf Вес Путь Сеть Метрика следующего перехода LocPrf Вес Путь * 2.0.0.0 150.10.10.2 0 0 12 я *> 160.20.20.2 0 100 10 я * 170.16.0.0 160.20.20.2 0 0 10 я *> 150.10.10.2 0 100 12 я RouterA# трассировка маршрута 2.2.2.2 Введите escape-последовательность, чтобы прервать. Отслеживание маршрута до 2.2.2.2 1 160.20.20.2 16 мс * 16 мс RouterA# трассировка 170.16.6.6 Введите escape-последовательность, чтобы прервать. Отслеживание маршрута до 170.16.6.6 1 150.10.10.2 4 мс * 4 мс
Устранение неполадок
В настоящее время нет конкретной информации по устранению неполадок для этой конфигурации.
Распределение нагрузки при многосетевом подключении к двум интернет-провайдерам через несколько локальных маршрутизаторов
Балансировка нагрузки невозможна в многосетевой среде с двумя интернет-провайдерами.BGP выбирает только один лучший путь к месту назначения среди путей BGP, полученных от разных AS, что делает балансировку нагрузки невозможной. Но в таких многосетевых сетях BGP возможно распределение нагрузки. На основе предопределенных политик поток трафика контролируется с помощью различных атрибутов BGP.
В этом разделе обсуждается наиболее часто используемая конфигурация множественной адресации. Конфигурация показывает, как добиться распределения нагрузки. См. сетевую диаграмму, на которой многодомная сеть AS 100 обеспечивает надежность и распределение нагрузки.
Примечание : IP-адреса в этом примере соответствуют стандартам RFC 1918 для частного адресного пространства и не маршрутизируются в Интернете.
Для простоты предположим, что политика маршрутизации BGP для AS 100:
AS 100 принимает локальные маршруты от обоих провайдеров, а также маршруты по умолчанию для остальных Интернет-маршрутов.
Политика исходящего трафика:
Трафик, предназначенный для AS 300, проходит по каналу R1-ISP(A).
Трафик, предназначенный для AS 400, проходит по каналу R2-ISP(B).
Весь остальной трафик должен предпочитать маршрут по умолчанию 0.0.0.0 через ссылку R1-ISP(A).
При сбое канала R1-ISP(A) весь трафик должен проходить через канал R2-ISP(B).
Политика входящего трафика:
Трафик, предназначенный для сети 10.10.10.0/24 из Интернета, должен исходить из канала ISP(A)-R1.
Трафик, предназначенный для сети 10.10.20.0/24 из Интернета, должен поступать по каналу ISP(B)-R2.
В случае сбоя одного поставщика услуг Интернета другой поставщик услуг Интернета должен перенаправить трафик обратно в AS 100 из Интернета для всех сетей.
Схема сети
В этом разделе используется следующая настройка сети:
Конфигурации
В этом разделе используются следующие конфигурации:
Р2
интерфейс Ethernet0 айпи адрес 192.168.21.2 255.255.255.0 ! интерфейс Serial0 IP-адрес 192.168.42.2 255.255.255.0 роутер бгп 100 нет синхронизации bgp log-neighbour-changes !--- В следующих двух строках объявляются сети партнерам BGP. сеть 10.10.10.0 маска 255.255.255.0 сеть 10.10.20.0 маска 255.255.255.0 !--- В следующей строке настраивается iBGP на маршрутизаторе R1. сосед 192.168.21.1 удаленный-как 100 сосед 192.168.21.1 следующий переход !--- В следующей строке настраивается eBGP с провайдером (B). сосед 192.168.42.4 удаленный-как 400 !--- Это карта входящих маршрутов политики для приложения
!--- атрибутов определенных маршрутов. сосед 192.168.42.4 route-map AS-400-INCOMING в !--- Это исходящая карта маршрутов политики для приложения
!--- атрибутов определенных маршрутов. сосед 192.168.42.4 route-map AS-400-OUTGOING out нет автоматического суммирования ! ! !--- В этой строке задается список доступа к путям AS.
!--- Строка разрешает все маршруты в домене маршрутизации провайдера.400$ ! !--- Эти две строки задают список доступа. список доступа 10 разрешение 10.10.10.0 0.0.0.255 список доступа 20 разрешение 10.10.20.0 0.0.0.255 !--- Следующие три строки настраивают LOCAL_PREF для маршрутов
!--- которые соответствуют списку доступа к путям AS 1. маршрут-карта AS-400-INCOMING разрешение 10 соответствует пути 1 установить локальные предпочтения 150 !--- Здесь карта маршрутов добавляет AS 100 к обновлениям BGP для сетей
!--- разрешенных списком доступа 10. маршрут-карта AS-400-ИСХОДЯЩЕЕ разрешение 10 соответствует IP-адресу 10 установить как путь перед 100 !--- В этой строке объявляется сеть, разрешенная
!--- списком доступа 20 без каких-либо изменений в атрибутах BGP. маршрут-карта AS-400-ИСХОДЯЩЕЕ разрешение 20 совпадать с IP-адресом 20
Р1
интерфейс Serial0/0 IP-адрес 192.168.31.1 255.255.255.0 ! интерфейс Ethernet1/0 IP-адрес 192.168.21.1 255.255.255.0 ! роутер бгп 100 нет синхронизации bgp log-neighbour-changes сеть 10.10.10.0 маска 255.255.255.0 сеть 10.10.20.0 маска 255.255.255.0 !--- Пиринг IBGP с R2 сосед 192.168.21.2 удаленный-как 100 сосед 192.168.21.2 следующего прыжка ! !--- Эта строка устанавливает пиринг eBGP с провайдером (A). сосед 192.168.31.3 удаленный-как 300 ! !--- Это карта входящих маршрутов политики для приложения
!--- атрибутов определенных маршрутов. сосед 192.168.31.3 route-map AS-300-INCOMING в ! !--- Это исходящая карта маршрутов политики для приложения
!--- атрибутов определенных маршрутов. сосед 192.168.31.3 route-map AS-300-OUTGOING out нет автоматического суммирования font color="#0000ff">!--- Эта строка устанавливает список доступа к пути AS.300$ ! !--- Эти две строки задают список доступа IP. список доступа 10 разрешение 10.10.20.0 0.0.0.255 список доступа 20 разрешение 10.10.10.0 0.0.0.255 !--- Следующие три строки настраивают LOCAL_PREF для маршрутов, соответствующих
!--- Список доступа к путям AS 1. маршрут-карта AS-300-ВХОДЯЩЕЕ разрешение 10 соответствует пути 1 установить локальное предпочтение 200 ! !--- Здесь карта маршрутов добавляет AS 100 к обновлениям BGP для сетей
!--- разрешенных списком доступа 10. маршрут-карта AS-300-ИСХОДЯЩИЙ пропуск 10 соответствует IP-адресу 10 установить как путь перед 100 ! !--- В этой строке объявляется сеть, разрешенная
!--- списком доступа 20 без каких-либо изменений в атрибутах BGP. маршрут-карта AS-300-ИСХОДЯЩЕЕ разрешение 20 совпадать с IP-адресом 20 !
Проверить
Используйте этот раздел, чтобы убедиться, что ваша конфигурация работает правильно.
Cisco CLI Analyzer (только для зарегистрированных клиентов) поддерживает определенные команды show . Используйте Cisco CLI Analyzer для просмотра анализа выходных данных команды show .
Введите команду show ip bgp , чтобы проверить, работает ли исходящая/входящая политика.
Примечание : Знак «больше» (>) в выводе show ip bgp представляет лучший путь для использования в этой сети среди возможных путей.Дополнительную информацию см. в разделе Алгоритм выбора оптимального пути BGP.
R1# показать IP BGP Версия таблицы BGP — 6, идентификатор локального маршрутизатора — 192.168.31.1. Коды состояния: s подавлен, d демпфирован, h история, * действительный, > лучший, i - внутренний Коды происхождения: i - IGP, e - EGP, ? - неполный Версия таблицы BGP — 6, идентификатор локального маршрутизатора — 192.168.31.1. Коды состояния: s подавлен, d демпфирован, h история, * действительный, > лучший, i - внутренний Коды происхождения: i - IGP, e - EGP, ? - неполный Сеть Метрика следующего перехода LocPrf Вес Путь *> 0.0.0.0 192.168.31.3 200 0 300 я !--- Эта строка показывает, что маршрут по умолчанию 0.0.0.0/0 является предпочтительным
!--- через AS 300, ISP(A).* i10.10.10.0/24 192.168.21.2 0 100 0 i
*> 0.0.0.0 0 32768 i
* i10.10.20.0/24 192.168.21.2 0 100 0 7 6 90.005.3.02 *> 0 я
*> 30.30.30.0/24 192.168.31.3 0 200 0 300 i
*>i40.40.40.0/24 192.168.21.2 0 150 0 400 i!--- Маршрут к сети 30.32.40.0/24 предпочтительный
!--- по каналу R1-ISP(A).
!--- Предпочтителен маршрут к сети 40.40.40.0/24 (AS 400)
!--- через канал R2-ISP(B).
Теперь посмотрите на вывод show ip bgp на маршрутизаторе R2:
.R2# показать IP BGP Версия таблицы BGP — 8, идентификатор локального маршрутизатора — 192.168.42.2 Коды состояния: s подавлен, d демпфирован, h история, * действительный, > лучший, i - внутренний Коды происхождения: i - IGP, e - EGP, ? - неполный Сеть Метрика следующего перехода LocPrf Вес Путь * 0.0.0.0 192.168.42.4 150 0 400 я *>i 192.168.21.1 200 0 300 i !--- Эта строка показывает, что предпочтительным является маршрут по умолчанию 0.0.0.0/0
!--- через AS 300 по каналу R2-ISP(B).*> 10.10.10.0/24 0.0.0.0 0 32768 i
* i 192.168.21.1 0 100 0 i
*> 10.10.20.0/24 0.0.0.0 0 32768 i
* i 192.168.200.1 6 i 0 900 0 .30.30.0/24 192.168.21.1 0 200 0 300 i
*> 40.40.40.0/24 192.168.42.4 0 150 0 400 i !--- Предпочтителен маршрут к сети 30.30.30.0/24 (AS 300)
!--- через канал R1-ISP(A).
!--- Предпочтителен маршрут к сети 40.40.40.0/24 (AS 400)
!--- через канал R2-ISP(B).
Выполните команду show ip bgp на маршрутизаторе 6, чтобы соблюдать политику входящего трафика для сетей 10.10.10.0/24 и 10.10.20.0/24:
R6# показать IP BGP Версия таблицы BGP — 15, идентификатор локального маршрутизатора — 192.168.64.6. Коды состояния: s подавлен, d демпфирован, h история, * действительный, > лучший, i - внутренний Коды происхождения: i - IGP, e - EGP, ? - неполный Сеть Метрика следующего перехода LocPrf Вес Путь *> 10.10.10.0/24 192.168.63.3 0 300 100 100 я !--- Эта строка показывает, что сеть 10.10.10.0/24 маршрутизируется через AS 300
!--- с каналом ISP(A)-R1.* 192.168.64.4 0 400 100 100 100 I
* 10.10.20.0/24 192.168.63.3 0 300 100 100 I
*> 192.168.64.4 0 400 100 I! --- Эта строка показывает, что сеть 10.10.20.0/24 маршрутизируется через AS 400
!--- с каналом ISP(B)-R2.*> 30.30.30.0/24 192.168.63.3 0 0 300 i
*> 40.40.40.0/24 192.168.64.4 0 0 400 i
Отключите канал R1-ISP(A) на маршрутизаторе R1 и просмотрите таблицу BGP. Ожидайте, что весь трафик в Интернет будет направляться через канал R2-ISP(B):
.R1(config)# последовательный интерфейс 0/0 R1(config-if)# выключение *2 мая 19:00:47.377: %BGP-5-ADJCHANGE: соседний 192.168.31.3 Down Интерфейсный клапан * 2 мая 19:00:48.277: %LINK-5-CHANGED: Interface Serial0/0, изменено состояние на административно вниз * 23 мая 12:00:51.255: %LINEPROTO-5-UPDOWN: линейный протокол на интерфейсе Serial0 изменен состояние вниз R1 # показать IP BGP Версия таблицы BGP — 12, идентификатор локального маршрутизатора — 192.168.31.1. Коды состояния: s подавлен, d демпфирован, h история, * действительный, > лучший, i - внутренний Коды происхождения: i - IGP, e - EGP, ? - неполный Сеть Метрика следующего перехода LocPrf Вес Путь *>i0.0.0.0 192.168.21.2 150 0 400 я !--- Теперь лучший путь по умолчанию — через канал R2-ISP(B).* i10.10.10.0/24 192.168.21.2 0 100 0 i
*> 0.0.0.0 0 32768 i
* i10.10.20.0/24 192.168.21.2 0 100 0 7 6 90.005.3.02 *> 0 i
*>i40.40.40.0/24 192.168.21.2 0 150 0 400 iR2# show ip bgp
Версия таблицы BGP — 14, идентификатор локального маршрутизатора — 192.168.42.2 Коды состояния: s подавлен, d демпфирован, h история, * действительный, > лучший, i - внутренний Коды происхождения: i - IGP, e - EGP, ? - неполный Сеть Метрика следующего перехода LocPrf Вес Путь *> 0.0.0.0 192.168.42.4 150 0 400 я !--- Лучший маршрут по умолчанию теперь через ISP(B) с
!--- локальным предпочтением 150. .0.0 0 32768 i
* i10.10.20.0/24 192.168.21.1 0 100 0 i
*> 0.0.0.0 0 32768 i
*> 40.40.40.0/24 192.168.42.4 0 150 0 400 i
Посмотрите маршрут для сети 10.10.10.0/24 в маршрутизаторе 6:
R6# показать IP BGP Версия таблицы BGP — 14, идентификатор локального маршрутизатора — 192.168.64.6. Коды состояния: s подавлен, d демпфирован, h история, * действительный, > лучший, i - внутренний Коды происхождения: i - IGP, e - EGP, ? - неполный Сеть Метрика следующего перехода LocPrf Вес Путь *> 10.10.10.0/24 192.168.64.4 0 400 100 100 я !--- Сеть 10.10.10.0 доступна через поставщика услуг Интернета (B), который объявил
!--- сеть с добавлением пути AS.*> 10.10.20.0.0/24 192.168.64.4 0 400 100 I
*> 30.30.30.0/24 192.168.63.3 0 0 300 I
*> 40.40.40.0/24 192.168.64.4 0 0 400 I
Устранение неполадок
В настоящее время нет конкретной информации по устранению неполадок для этой конфигурации.
Сопутствующая информация
компонентов Azure Load Balancer | Документы Майкрософт
- Статья
- 5 минут на чтение
Пожалуйста, оцените свой опыт
да Нет
Любая дополнительная обратная связь?
Отзыв будет отправлен в Microsoft: при нажатии кнопки отправки ваш отзыв будет использован для улучшения продуктов и услуг Microsoft.Политика конфиденциальности.
Представлять на рассмотрение
Спасибо.
В этой статье
Azure Load Balancer включает несколько ключевых компонентов. Эти компоненты можно настроить в вашей подписке через портал Azure, Azure CLI, Azure PowerShell, шаблоны Resource Manager или соответствующие альтернативы.
IP-конфигурация внешнего интерфейса
IP-адрес вашего Azure Load Balancer.Это точка контакта для клиентов. Эти IP-адреса могут быть:
- Общедоступный IP-адрес
- Частный IP-адрес
Характер IP-адреса определяет тип созданного балансировщика нагрузки. При выборе частного IP-адреса создается внутренний балансировщик нагрузки. Выбор общедоступного IP-адреса создает общедоступный балансировщик нагрузки.
| Общедоступный балансировщик нагрузки | Внутренний балансировщик нагрузки | |
|---|---|---|
| IP-конфигурация внешнего интерфейса | Общедоступный IP-адрес | Частный IP-адрес |
| Описание | Общедоступный балансировщик нагрузки сопоставляет общедоступный IP-адрес и порт входящего трафика с частным IP-адресом и портом виртуальной машины.Балансировщик нагрузки наоборот сопоставляет трафик с ответным трафиком от виртуальной машины. Вы можете распределять определенные типы трафика между несколькими виртуальными машинами или службами, применяя правила балансировки нагрузки. Например, вы можете распределить нагрузку трафика веб-запросов между несколькими веб-серверами. | Внутренний балансировщик нагрузки распределяет трафик по ресурсам, находящимся внутри виртуальной сети. Azure ограничивает доступ к интерфейсным IP-адресам виртуальной сети с балансировкой нагрузки. Внешние IP-адреса и виртуальные сети никогда не передаются напрямую конечной точке Интернета, а это означает, что внутренний балансировщик нагрузки не может принимать входящий трафик из Интернета.Внутренние бизнес-приложения выполняются в Azure, и доступ к ним осуществляется из Azure или из локальных ресурсов. |
| Поддерживаемые SKU | Базовый, Стандартный | Базовый, Стандартный |
Балансировщик нагрузки может иметь несколько интерфейсных IP-адресов. Узнайте больше о нескольких интерфейсах.
Серверный пул
Группа виртуальных машин или экземпляров в масштабируемом наборе виртуальных машин, который обслуживает входящий запрос.Для рентабельного масштабирования для обработки больших объемов входящего трафика в рекомендациях по вычислениям обычно рекомендуется добавлять больше экземпляров в серверный пул.
Балансировщик нагрузки мгновенно перенастраивается с помощью автоматической перенастройки при увеличении или уменьшении масштаба экземпляров. Добавление или удаление виртуальных машин из внутреннего пула изменяет конфигурацию балансировщика нагрузки без дополнительных операций. Областью внутреннего пула является любая виртуальная машина в одной виртуальной сети.
Внутренние пулы поддерживают добавление экземпляров через сетевой интерфейс или IP-адреса.
При рассмотрении того, как спроектировать серверный пул, спроектируйте наименьшее количество отдельных ресурсов серверного пула, чтобы оптимизировать продолжительность операций управления. Нет никакой разницы в производительности или масштабе плоскости данных.
Зонды здоровья
Проверка работоспособности используется для определения состояния работоспособности экземпляров в серверном пуле. Во время создания балансировщика нагрузки настройте пробу работоспособности для использования балансировщиком нагрузки. Эта проверка работоспособности определит, исправен ли экземпляр и может ли он получать трафик.
Вы можете определить порог неработоспособности для ваших тестов работоспособности. Когда зонд не отвечает, балансировщик нагрузки прекращает отправлять новые подключения к неработоспособным экземплярам. Сбой зонда не влияет на существующие соединения. Соединение продолжается до приложения:
- Завершает поток
- Тайм-аут простоя
- ВМ выключается
Балансировщик нагрузки предоставляет различные типы тестов работоспособности для конечных точек: TCP, HTTP и HTTPS. Узнайте больше о проверках работоспособности Load Balancer.
Базовый балансировщик нагрузки не поддерживает зонды HTTPS. Базовый балансировщик нагрузки закрывает все соединения TCP (включая установленные соединения).
Правила балансировщика нагрузки
Правило балансировщика нагрузки используется для определения того, как входящий трафик распределяется между всеми экземплярами внутреннего пула. Правило балансировки нагрузки сопоставляет данную конфигурацию внешнего IP-адреса и порт с несколькими внутренними IP-адресами и портами. Правила Load Balancer предназначены только для входящего трафика.
Например, используйте правило балансировщика нагрузки для порта 80, чтобы направить трафик с внешнего IP-адреса на порт 80 серверных экземпляров.
Рисунок: Правила балансировки нагрузки
Порты высокой доступности
Правило балансировщика нагрузки, настроенное с параметром «протокол — все и порт — 0» , известно как правило порта высокой доступности (HA). Это правило позволяет использовать одно правило для балансировки нагрузки всех потоков TCP и UDP, поступающих на все порты внутреннего балансировщика нагрузки Standard.
Решение о балансировке нагрузки принимается для каждого потока. Это действие основано на следующем соединении из пяти кортежей:
- исходный IP-адрес
- исходный порт
- IP-адрес назначения
- порт назначения
- протокол
Правила балансировки нагрузки портов высокой доступности помогают в критических сценариях, таких как высокая доступность и масштабирование сетевых виртуальных устройств (NVA) внутри виртуальных сетей.Эта функция может помочь, когда необходимо сбалансировать нагрузку на большое количество портов.
Рисунок: Правила портов высокой доступности
Узнайте больше о портах высокой доступности.
Правила NAT для входящего трафика
Правило NAT для входящего трафика перенаправляет входящий трафик, отправленный на внешний IP-адрес и комбинацию портов. Трафик отправляется на конкретную виртуальную машину или экземпляр во внутреннем пуле. Переадресация портов выполняется тем же распределением на основе хэшей, что и балансировка нагрузки.
Рисунок: Правила NAT для входящего трафика
Входящие правила NAT в контексте масштабируемых наборов виртуальных машин — это входящие пулы NAT. Узнайте больше о компонентах Load Balancer и масштабируемом наборе виртуальных машин.
Правила исходящего трафика
Исходящее правило настраивает исходящее преобразование сетевых адресов (NAT) для всех виртуальных машин или экземпляров, идентифицированных внутренним пулом. Это правило позволяет экземплярам в бэкэнде обмениваться данными (исходящими) с Интернетом или другими конечными точками.
Дополнительные сведения об исходящих соединениях и правилах.
Базовый балансировщик нагрузки не поддерживает исходящие правила.
Рисунок: Правила исходящего трафика
Ограничения
- Узнайте об ограничениях балансировщика нагрузки
- Балансировщик нагрузки обеспечивает балансировку нагрузки и переадресацию портов для определенных протоколов TCP или UDP. Правила балансировки нагрузки и правила NAT для входящего трафика поддерживают TCP и UDP, но не поддерживают другие протоколы IP, включая ICMP.
- Внутренний пул Load Balancer не может состоять из частной конечной точки.
- Исходящий поток от внутренней виртуальной машины к внешнему интерфейсу внутреннего балансировщика нагрузки завершится ошибкой.
- Правило балансировщика нагрузки не может охватывать две виртуальные сети. Все внешние интерфейсы балансировщика нагрузки и их серверные экземпляры должны находиться в одной виртуальной сети.
- Пересылка фрагментов IP не поддерживается правилами балансировки нагрузки. IP-фрагментация пакетов UDP и TCP не поддерживается правилами балансировки нагрузки. Правила балансировки нагрузки портов HA можно использовать для пересылки существующих фрагментов IP. Дополнительные сведения см. в разделе Обзор портов высокой доступности.
- У вас может быть только 1 общедоступный балансировщик нагрузки и 1 внутренний балансировщик нагрузки на группу доступности